mysql数据库网站北京环球影城可以带水果吗
华为云cce健康检查
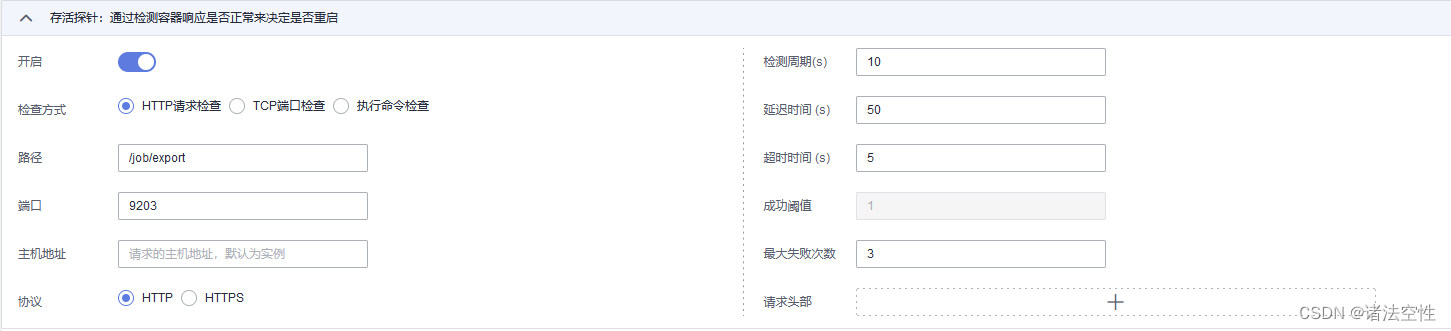
如上图,华为云健康检查可用来探测cce的实例运行状态,必要时cce会自动重启实例,达到cce持续服务。
但是配置时需要注意一下几个方面,否则cce的状态总是有些不正常。
1、http探查比较友好。因为我们的在cce里面发布的服务很多时候都是java spring boot的,直接使用spring boot服务本身的接口自然比较方便。
2、http探测使用的是ajax的状态标记,spring boot里面将业务错误封装成结果中的错误code,与http请求的错误标记是分开的,所以只要能连接后台服务,健康检查不会关注你springboot里面的状态。所以在路径上,你可以配置你spring boot中的任意接口,只要他能访问得到,健康检查就会通过,认为此时服务正常。
3、延迟时间需要大于cce负载之中服务的启动时间,否则会引起cce实例的循环启动,也就是cce实例还没启动起来呢,健康检查发现服务返回的不是200,也就是服务不正常,他会自动重启实例,从而导致服务循环启动,所以延迟时间的配置要注意。
4、端口,端口就是你的本服务的端口,不是对外映射的端口。
5、最大失败次数需要多一点。但是也需要根据自己的实际情况来。如果cce节点的压力比较大,则需要把次数舍得多一点,要不然cce节点中的实例会卡死,也就是实例启动不起来,但是他也不会自动被删除,这样反而会占用cce节点的资源,导致cce节点因为资源被占用过高而卡死,所有服务实例都给宕机了。
6、当然,这时候其实应该检查一下你的cce节点,cce节点的配置必须高于负载的分配,最好是性能高于负载配置的一倍,否则cce节点性能不足时还是比较容易卡死的,cce节点中还要运行K8S本身的一些负载。