广东网站快速备案如何建设局域网内部网站
大家好!本节主要介绍设计模式中的抽象工厂模式。
简介:
抽象工厂模式,它是所有形态的工厂模式中最为抽象和最具一般性的一种形态。它用于处理当有多个抽象角色时的情况。抽象工厂模式可以向客户端提供一个接口,使客户端在不必指定产品的具体情况下创建多个产品组中的产品对象。这种模式根据里氏替换原则,任何接受父类型的地方都应当能够接受子类型。实际上,系统所需要的仅仅是类型与这些抽象产品角色相同的一些实例。
抽象工厂模式的创建步骤如下:
1、创建抽象工厂类,定义具体工厂的公共接口。
2、创建抽象产品族类,定义抽象产品的公共接口。
3、创建抽象产品类(继承抽象产品族类),定义具体产品的公共接口。
4、创建具体产品类(继承抽象产品类)&定义生产的具体产品。
5、创建具体工厂类(继承抽象工厂类),定义创建对应具体产品实例的方法。
6、客户端通过实例化具体的工厂类,并调用其创建不同目标产品的方法创建不同具体产品类的实例。
抽象工厂模式的优点,主要包括:
1、隔离了具体类的生产:使得客户并不需要知道什么被创建,降低了客户端与具体产品的耦合度。
2、保证同一产品族的使用:当一个产品族中的多个对象被设计成一起工作时,抽象工厂模式能保证客户端始终只使用同一个产品族中的对象。
3、易于扩展:增加新的具体工厂和产品族很方便,无须修改已有系统,符合“开闭原则”。
4、提供更高层次的抽象:抽象工厂模式能够提供更高层次的抽象,同时也能够更好地管理不同产品族之间的关系,从而使得系统更加灵活和易于扩展。
5、符合单一职责原则:每个具体工厂只负责创建一组具体产品,不会与其他产品产生耦合。
抽象工厂模式的缺点,主要包括:
1、增加新的产品等级结构麻烦:需要对原有系统进行较大的修改,甚至需要修改抽象层代码,这可能会违背开闭原则。
2、抽象工厂模式需要识别和定义所有的抽象产品类和具体产品类,这会增加系统的复杂性。
3、在客户端代码中需要显式地指定使用哪个具体工厂,这会增加客户端代码的复杂性。
4、如果出现异常情况,很难确定是哪一个工厂或者是哪一个产品出现问题,因为它们都是独立的对象。
5、实现抽象工厂模式需要消耗较多的时间和精力,因为需要分离出抽象工厂类和具体工厂类,并且需要针对每个具体工厂类编写对应的客户端代码。
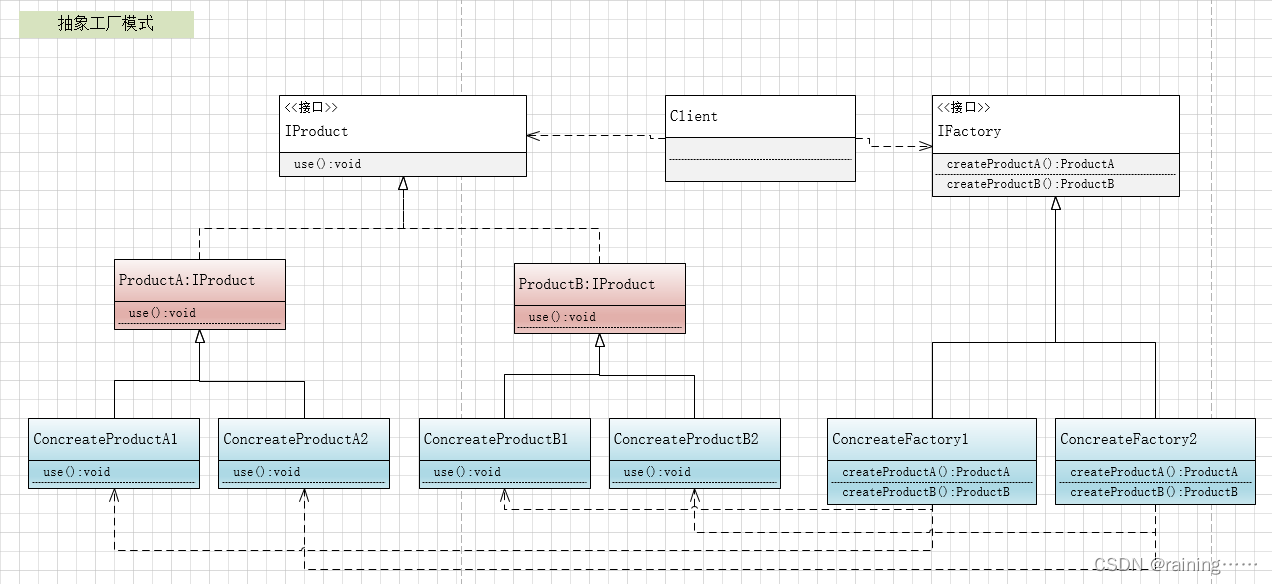
示例:
在实际应用中,工厂的创建和产品的生产可能会更加复杂,并且可能会有更多的具体工厂和产品类。
一、C#抽象工厂模式
以下是一个示例,展示了如何在C#中实现抽象工厂模式:
//首先,定义一个接口来表示工厂:
public interface IFactory { Product CreateProduct();
}
//接下来,实现具体工厂类,它们分别创建具体产品对象:
public class ConcreteFactoryA : IFactory { public Product CreateProduct() { return new ConcreteProductA(); }
} public class ConcreteFactoryB : IFactory { public Product CreateProduct() { return new ConcreteProductB(); }
}
//然后,定义一个抽象产品接口和具体产品类来实现该接口:
public interface Product { void Use();
} public class ConcreteProductA : Product { public void Use() { Console.WriteLine("Using Product A"); }
} public class ConcreteProductB : Product { public void Use() { Console.WriteLine("Using Product B"); }
}
//最后,编写客户端代码来使用抽象工厂模式创建产品对象:
public class Client { public void UseProduct(IFactory factory) { Product product = factory.CreateProduct(); product.Use(); }
}
//在主程序中,可以创建客户端对象并使用不同的工厂对象来创建产品对象:
static void Main() { Client client = new Client(); IFactory factoryA = new ConcreteFactoryA(); client.UseProduct(factoryA); // Output: Using Product A IFactory factoryB = new ConcreteFactoryB(); client.UseProduct(factoryB); // Output: Using Product B
}
二、java抽象工厂模式模式
抽象工厂模式通常通过以下方式实现:
//抽象工厂接口:这是一个工厂的抽象接口,它定义了创建对象的方法,但并不实现。
public interface AbstractFactory { ProductA createProductA(); ProductB createProductB();
} //具体工厂类:这些类实现了抽象工厂接口,并知道如何创建特定类型的对象。
public class ConcreteFactory1 implements AbstractFactory { @Override public ProductA createProductA() { return new ProductA1(); } @Override public ProductB createProductB() { return new ProductB1(); }
} public class ConcreteFactory2 implements AbstractFactory { @Override public ProductA createProductA() { return new ProductA2(); } @Override public ProductB createProductB() { return new ProductB2(); }
}//抽象产品接口:这些接口定义了产品的规范,即产品应具有的通用方法。
public interface ProductA { void use();
} public interface ProductB { void use();
}//具体产品类:这些类实现了抽象产品接口,并提供了具体的实现。
public class ProductA1 implements ProductA { @Override public void use() { System.out.println("Using product A1"); }
} public class ProductA2 implements ProductA { @Override public void use() { System.out.println("Using product A2"); }
} //最后,在客户端代码中,我们通常会使用一个“提供者”类(如名称“Provider”)来获取工厂对象,然后使用这些工厂对象来创建产品。这样可以让客户端代码与工厂的具体实现解耦。
public class Client { private AbstractFactory factory; public Client(AbstractFactory factory) { this.factory = factory; } public void useProducts() { ProductA productA = factory.createProductA(); productA.use(); ProductB productB = factory.createProductB(); productB.use(); }
}
//主程序
public static void main(String[] args) { Client client = new Client(); AbstractFactory factory1 = new ConcreteFactory1(); client.UseProduct(factory1); // Output: Using Product A AbstractFactory factory2 = new ConcreteFactory2(); client.UseProduct(factory2); // Output: Using Product B
}
三、javascript抽象工厂模式
在JavaScript中,抽象工厂模式通常可以通过构造函数和对象字面量的组合来实现。
// 抽象工厂接口
function AbstractFactory() { this.createProduct = function() { throw new Error("This method is abstract and has to be implemented"); };
} // 具体工厂类1
function ConcreteFactory1() {}
ConcreteFactory1.prototype.createProduct = function() { return new Product1();
}; // 具体工厂类2
function ConcreteFactory2() {}
ConcreteFactory2.prototype.createProduct = function() { return new Product2();
}; // 产品接口
function Product() {}
Product.prototype.use = function() { throw new Error("This is an abstract method and has to be implemented");
}; // 产品类1
function Product1() {}
Product1.prototype = Object.create(Product.prototype);
Product1.prototype.constructor = Product1;
Product1.prototype.use = function() { console.log("Using product 1");
}; // 产品类2
function Product2() {}
Product2.prototype = Object.create(Product.prototype);
Product2.prototype.constructor = Product2;
Product2.prototype.use = function() { console.log("Using product 2");
}; // 客户端代码
function Client() { var factory; this.setFactory = function(f) { factory = f; }; this.useFactory = function() { var product = factory.createProduct(); product.use(); };
} var client = new Client();
client.setFactory(new ConcreteFactory1());
client.useFactory(); // Outputs: Using product 1
client.setFactory(new ConcreteFactory2());
client.useFactory(); // Outputs: Using product 2四、C++抽象工厂模式
以下是在C++中实现抽象工厂模式:
#include <iostream>
#include <string> // 抽象产品接口
class Product {
public: virtual void use() = 0;
}; // 具体产品类1
class ProductA : public Product {
public: void use() { std::cout << "Using Product A" << std::endl; }
}; // 具体产品类2
class ProductB : public Product {
public: void use() { std::cout << "Using Product B" << std::endl; }
}; // 抽象工厂接口
class Factory {
public: virtual Product* createProduct() = 0;
}; // 具体工厂类1
class FactoryA : public Factory {
public: Product* createProduct() { return new ProductA(); }
}; // 具体工厂类2
class FactoryB : public Factory {
public: Product* createProduct() { return new ProductB(); }
}; int main() { // 创建抽象工厂对象 Factory* factory = nullptr; // 创建具体工厂类1的对象,并赋值给抽象工厂对象 FactoryA factoryA; factory = &factoryA; // 使用抽象工厂对象创建产品对象,并使用产品对象 Product* product = factory->createProduct(); product->use(); // 创建具体工厂类2的对象,并赋值给抽象工厂对象 FactoryB factoryB; factory = &factoryB; // 使用抽象工厂对象创建产品对象,并使用产品对象 product = factory->createProduct(); product->use(); return 0;
}
五、python抽象工厂模式
以下是在python中实现抽象工厂模式:
#定义抽象产品接口,抽象产品接口定义了产品对象的通用方法。
class Product: def use(self): raise NotImplementedError("This method is abstract and has to be implemented")#实现具体产品类
class ProductA(Product): def use(self): print("Using Product A") class ProductB(Product): def use(self): print("Using Product B")#定义抽象工厂接口,抽象工厂接口定义了创建产品对象的通用方法。
class Factory: def createProduct(self): raise NotImplementedError("This method is abstract and has to be implemented")#实现具体工厂类,具体工厂类继承抽象工厂接口并实现createProduct方法
class FactoryA(Factory): def createProduct(self): return ProductA() class FactoryB(Factory): def createProduct(self): return ProductB()#创建客户端代码,客户端代码使用抽象工厂接口创建产品对象并使用它们。
factory = Factory() # 创建抽象工厂对象
product = factory.createProduct() # 使用抽象工厂对象创建产品对象
product.use() # 使用产品对象
六、go抽象工厂模式
以下是一个示例,展示了如何在go中实现抽象工厂模式:
//定义接口:首先,定义出需要创建对象的接口,这个接口规定了对象的共有方法。
type Product interface { Use()
} type ConcreteProductA struct{} func (p *ConcreteProductA) Use() { fmt.Println("Using Product A")
} type ConcreteProductB struct{} func (p *ConcreteProductB) Use() { fmt.Println("Using Product B")
}//定义抽象工厂接口:接下来,定义出抽象工厂接口,这个接口规定了创建对象的方法。
type Factory interface { CreateProduct() Product
} type ConcreteFactoryA struct{} func (f *ConcreteFactoryA) CreateProduct() Product { return &ConcreteProductA{}
} type ConcreteFactoryB struct{} func (f *ConcreteFactoryB) CreateProduct() Product { return &ConcreteProductB{}
}//实现客户端代码:现在可以写客户端代码了,这个代码使用抽象工厂接口来创建产品对象。
func main() { factoryA := &ConcreteFactoryA{} productA := factoryA.CreateProduct() productA.Use() // Output: Using Product A factoryB := &ConcreteFactoryB{} productB := factoryB.CreateProduct() productB.Use() // Output: Using Product B
}
七、PHP抽象工厂模式
以下是一个示例,展示了如何在PHP中实现抽象工厂模式:
// 抽象产品接口
interface Product { public function operation();
} // 具体产品类实现抽象接口
class ConcreteProductA implements Product { public function operation() { echo "Product A operation\n"; }
} class ConcreteProductB implements Product { public function operation() { echo "Product B operation\n"; }
} // 抽象工厂接口
interface Factory { public function createProduct();
} // 具体工厂类实现抽象工厂接口,创建具体产品对象
class ConcreteFactoryA implements Factory { public function createProduct() { return new ConcreteProductA(); }
} class ConcreteFactoryB implements Factory { public function createProduct() { return new ConcreteProductB(); }
} // 客户端代码使用抽象工厂对象创建具体产品对象
class Client { public function useProduct(Factory $factory) { $product = $factory->createProduct(); $product->operation(); }
} // 示例用法
$client = new Client();
$factoryA = new ConcreteFactoryA();
$client->useProduct($factoryA); // Output: Product A operation $factoryB = new ConcreteFactoryB();
$client->useProduct($factoryB); // Output: Product B operation
《完结》