刷赞网站空间网站创建方案怎么写
文章目录
- 一、创建VirtualHost类
- 二、初始化
- 三、API
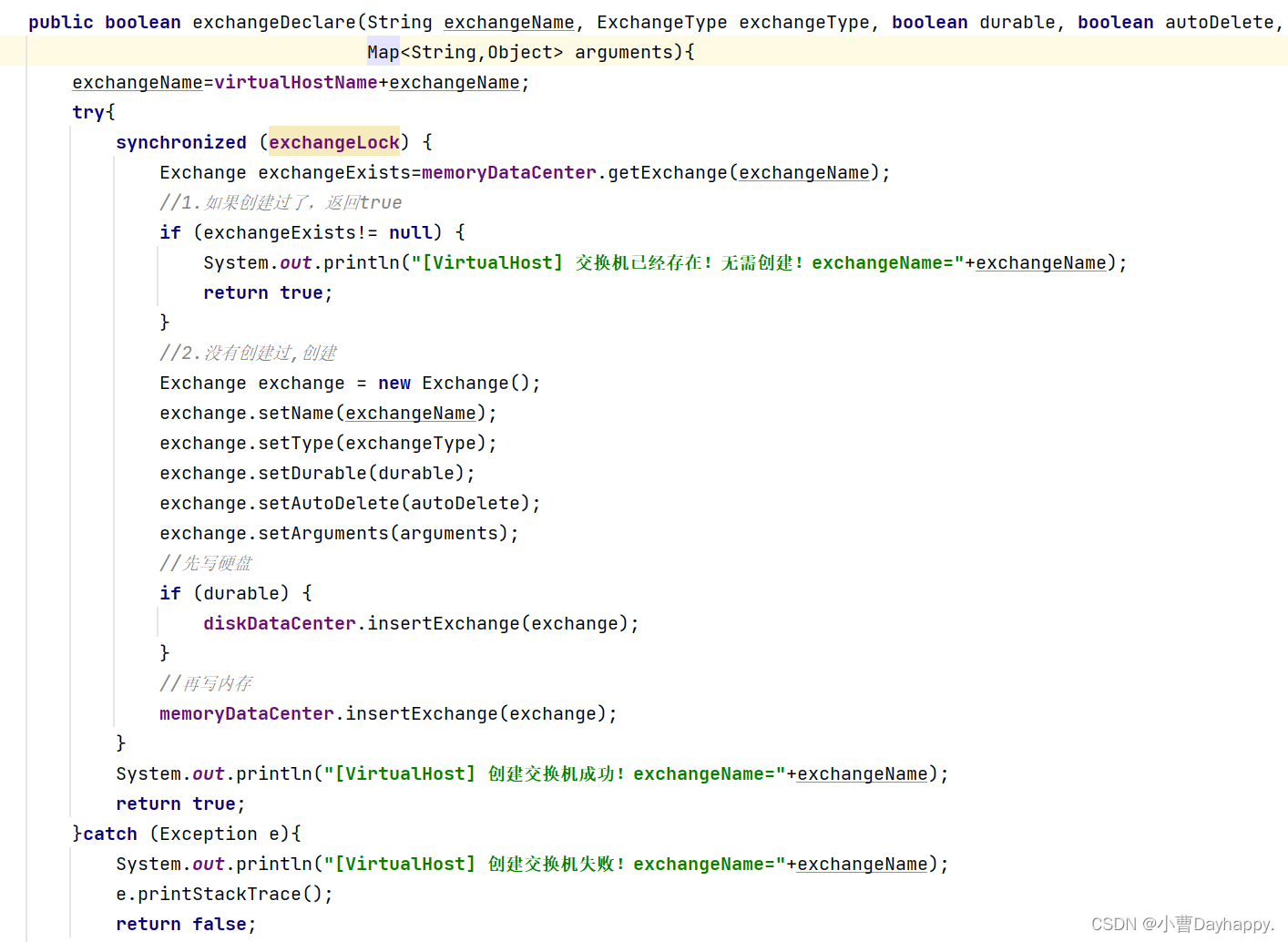
- 1.创建交换机
- 2.删除交换机
- 3.创建队列
- 4.删除队列
- 5.创建绑定
- 6.删除绑定
- 7.发送消息
- 转发规则
- 8.订阅消息
- 1.消费者管理
- 2.推送消息给消费者
- 3.添加一个消费者管理ConsumerManager
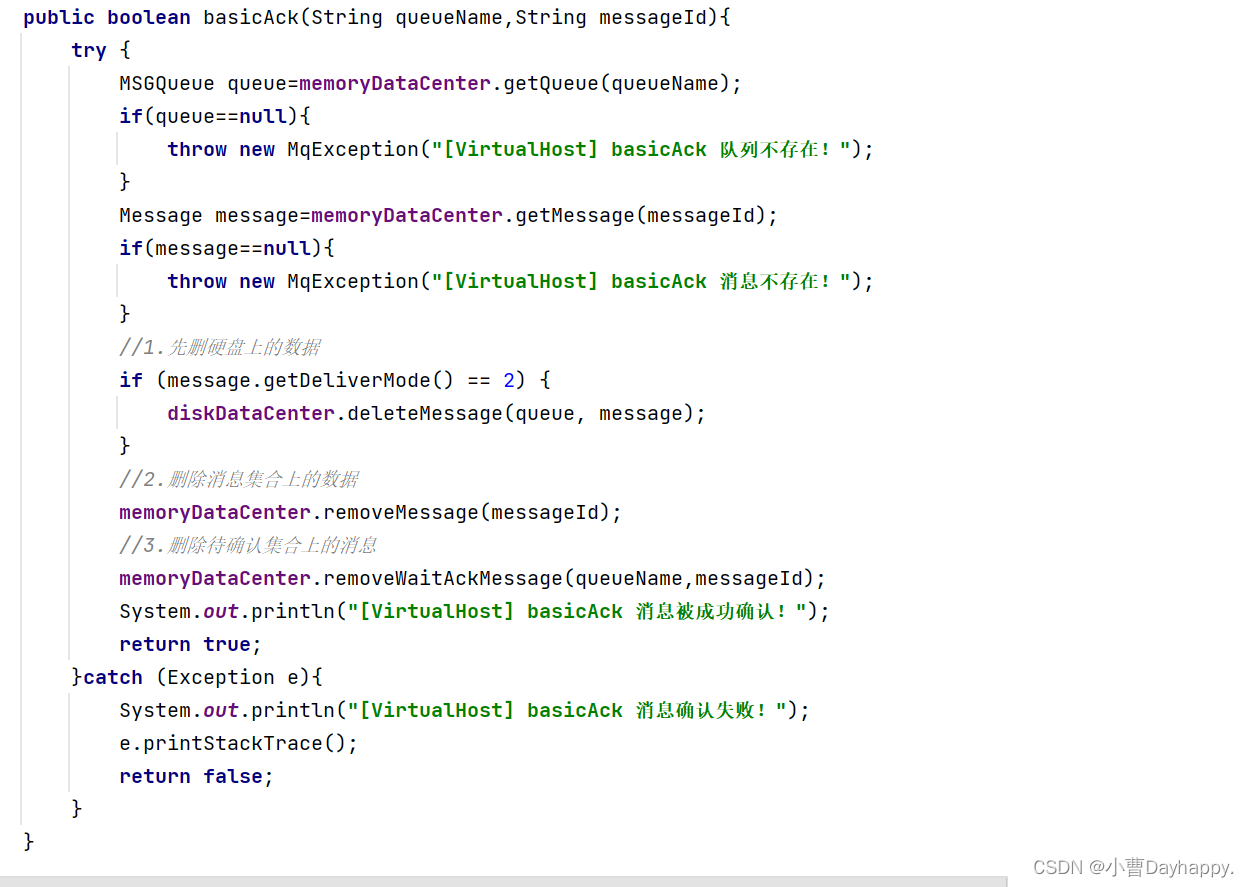
- 9.确认消息
创建VirtualHost类。
1.串起内存和硬盘的数据。
2.通过在队列名、交换机名前面加上虚拟主机的名字来隔离不同组的业务。
3.实现API
4.实现转发规则
一、创建VirtualHost类

二、初始化
- 初始化硬盘
- 加载硬盘数据到内存

三、API
1.创建交换机
- 创建过了 return true
- 没有创建过,创建
- 先写硬盘、后写内存
2.删除交换机
- 检查交换机是否存在,不存在,抛异常
- 存在,删除交换机
- 先删硬盘、再删内存

3.创建队列
- 检查队列是否存在,存在,return true
- 不存在,创建
- 先写硬盘、再写内存

4.删除队列
- 检查队列是否存在,不存在,抛异常
- 存在,删除队列
- 先删硬盘、再删内存

5.创建绑定

- 检查绑定是否存在,存在,抛异常
- 不存在,检查bindingKey是否合法,不合法,抛异常
- 检查交换机和队列是否存在,不存在,抛异常
- 存在,创建绑定
- 先写硬盘,再写内存

6.删除绑定
- 检查绑定是否存在,不存在,抛异常
- (省略检查)删除绑定
- 先删硬盘、再删内存

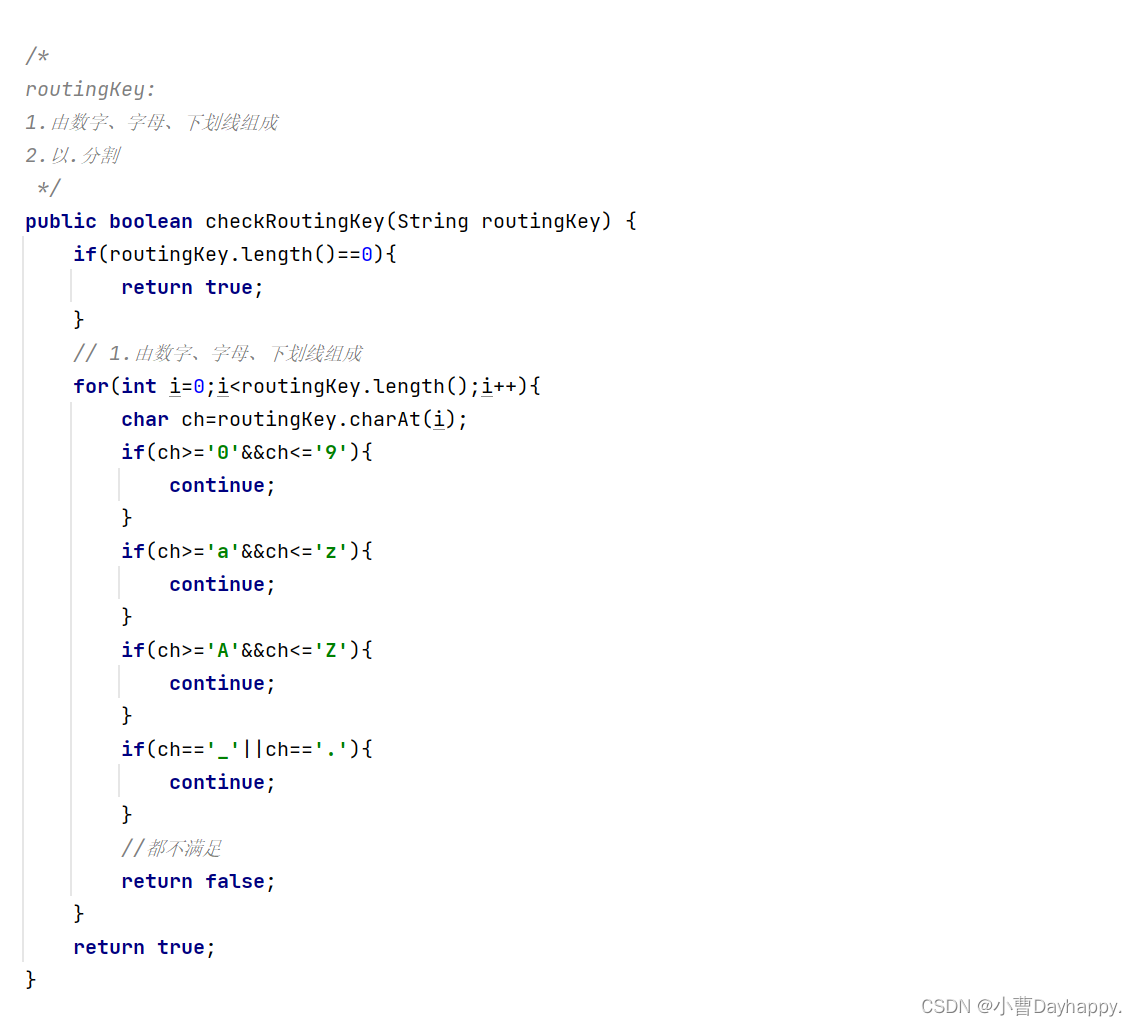
7.发送消息
- 检查交换机是否存在,不存在,抛异常
- 检查routingKey是否合法
- 合法,根据交换机规则转发消息
DIRECT(直接交换机) 队列名就是routingKey,根据routingKey找对应的队列
FANOUT(扇出交换机)往交换机绑定的所有队列转发消息
TOPIC(主题交换机)遍历交换机绑定的所有队列,根据routingKey能匹配的上的bindingKey对应的队列
转发规则
- 检查binfdingKey是否合法

- 检查routingKey是否合法
- 根据交换机类型匹配不同的转发规则
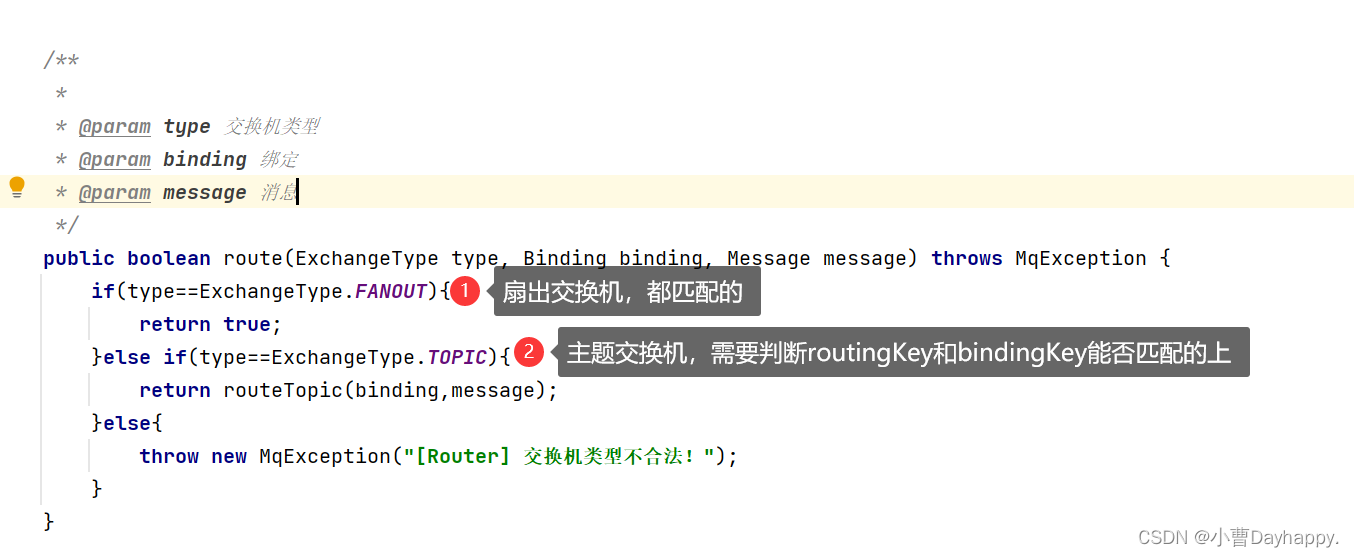
- 主题交换机的匹配规则

=========================================
- 发送消息
- 先写硬盘、再写内存
- 通知消费者可以消费数据了


8.订阅消息
- 往指定队列添加订阅者(消费者),队列收到消息后推送消息给订阅者(消费者)
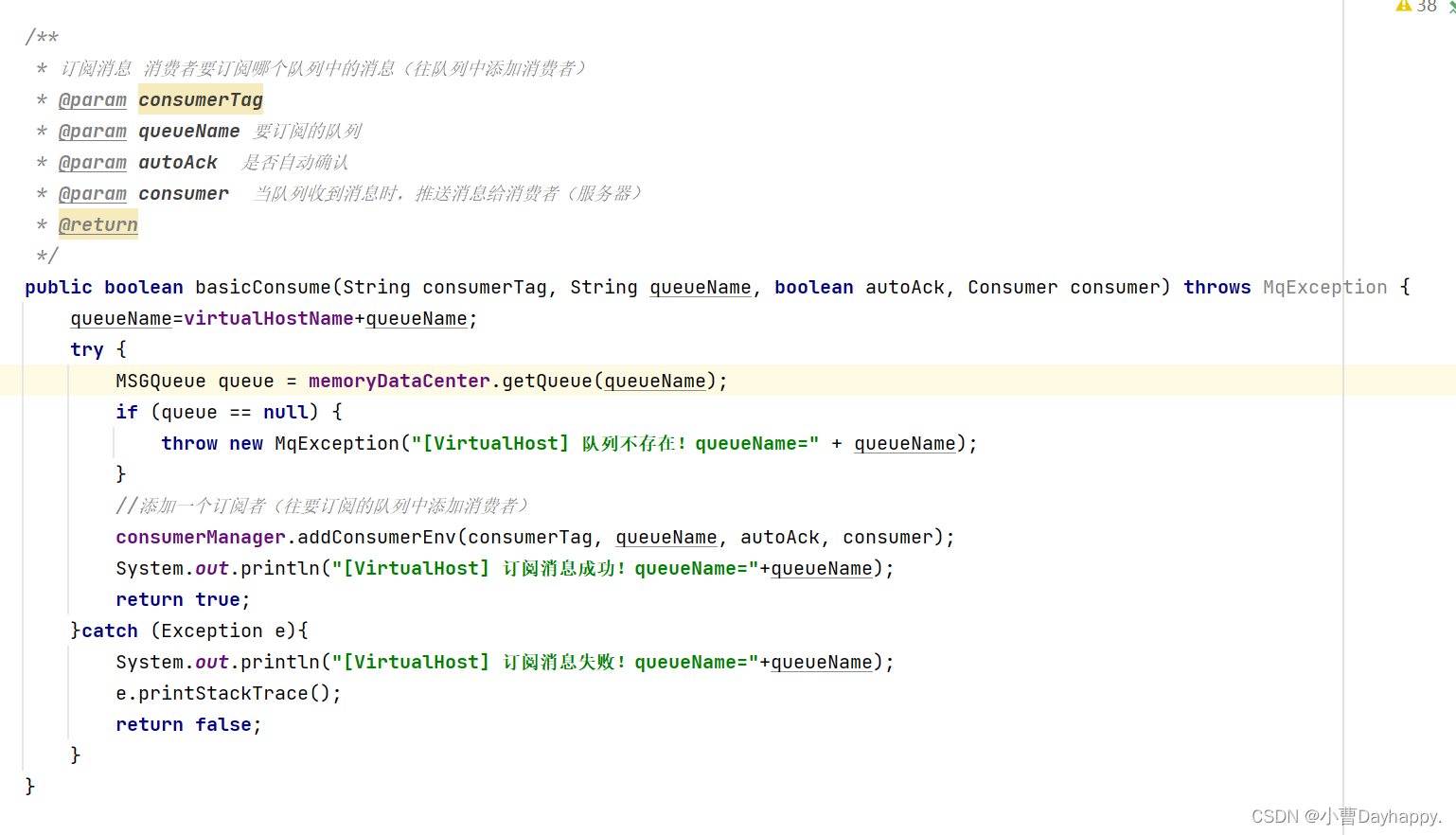
- Consumer
一个函数式接口,用来实现回调函数。当队列收到消息后调用的。
服务器通过此接口,实现把消息推送给客户端
客户端通过此接口,实现收到消息后进行消费

1.消费者管理
-
添加一个ConsumerEnv类,表示一个消费者。

-
在MSGQueue中添加一个属性 List,里面存放订阅了该队列的消费者。

-
实现添加消费者
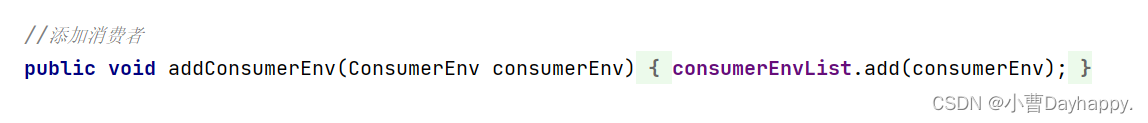
-
以轮询的方式,挑选消费者

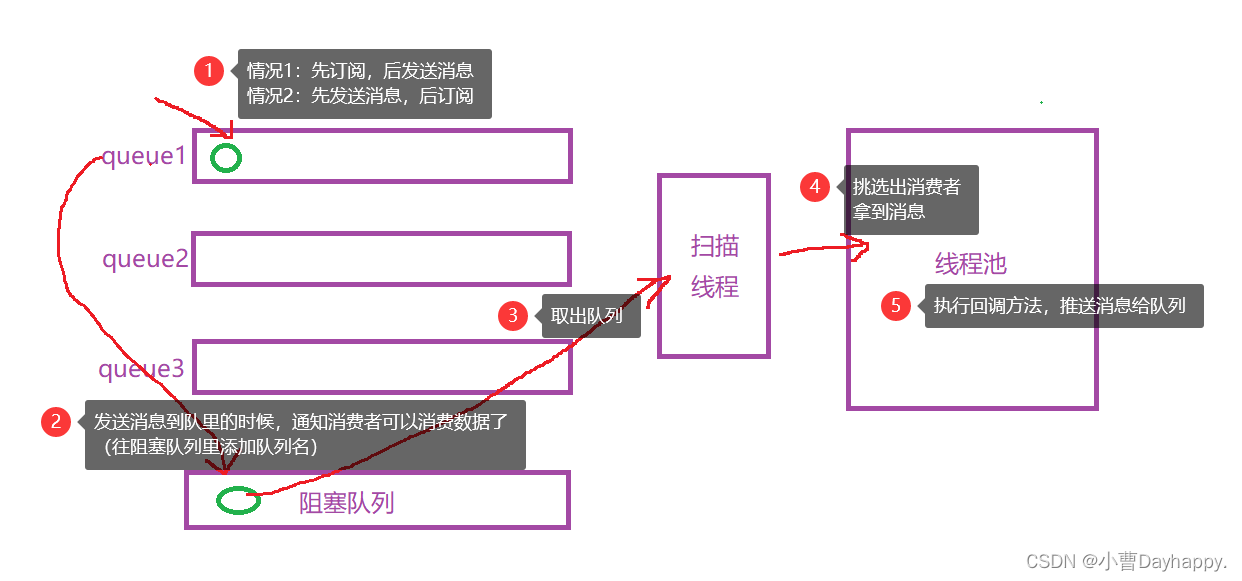
2.推送消息给消费者
核心方法其实就是调用回调方法,但是为了调用次回调方法,需要做很多前期准备
- 添加一个阻塞队列,当队列收到消息,把队列名添加到阻塞队列中(相当于令牌)
(前面发送消息的时候,有一个通知消费者可以消费了,这个方法其实就是把队列名添加到阻塞队列中) - 添加一个扫描线程,不停的扫描阻塞队列,拿到令牌通知线程池执行回调
- 挑选出对应队列的消费者,使用线程池执行回调方法,推送消息给该消费者
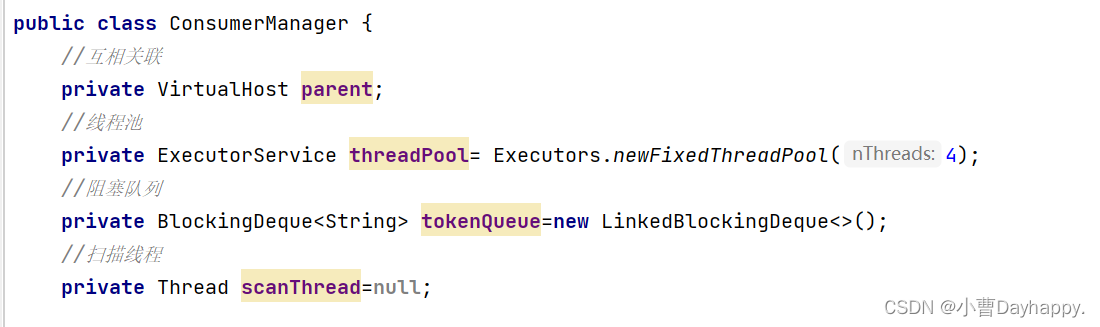
3.添加一个消费者管理ConsumerManager
管理消费者和推送消息给消费者的功能
-
属性
-
往阻塞队列中添加队列名(发送消息的时候调用,通知消费者可以消费消息了)

-
往队列中添加订阅者(如果此时有消息了,需要立即消费掉)
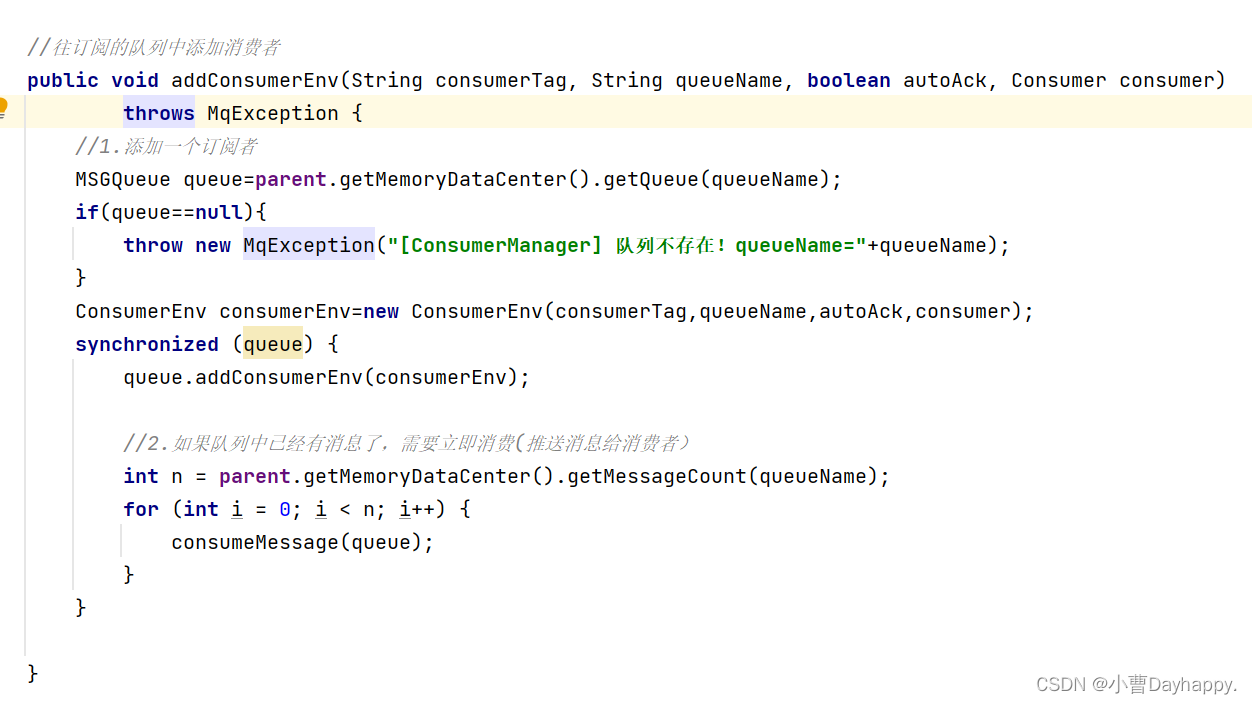
-
扫描线程
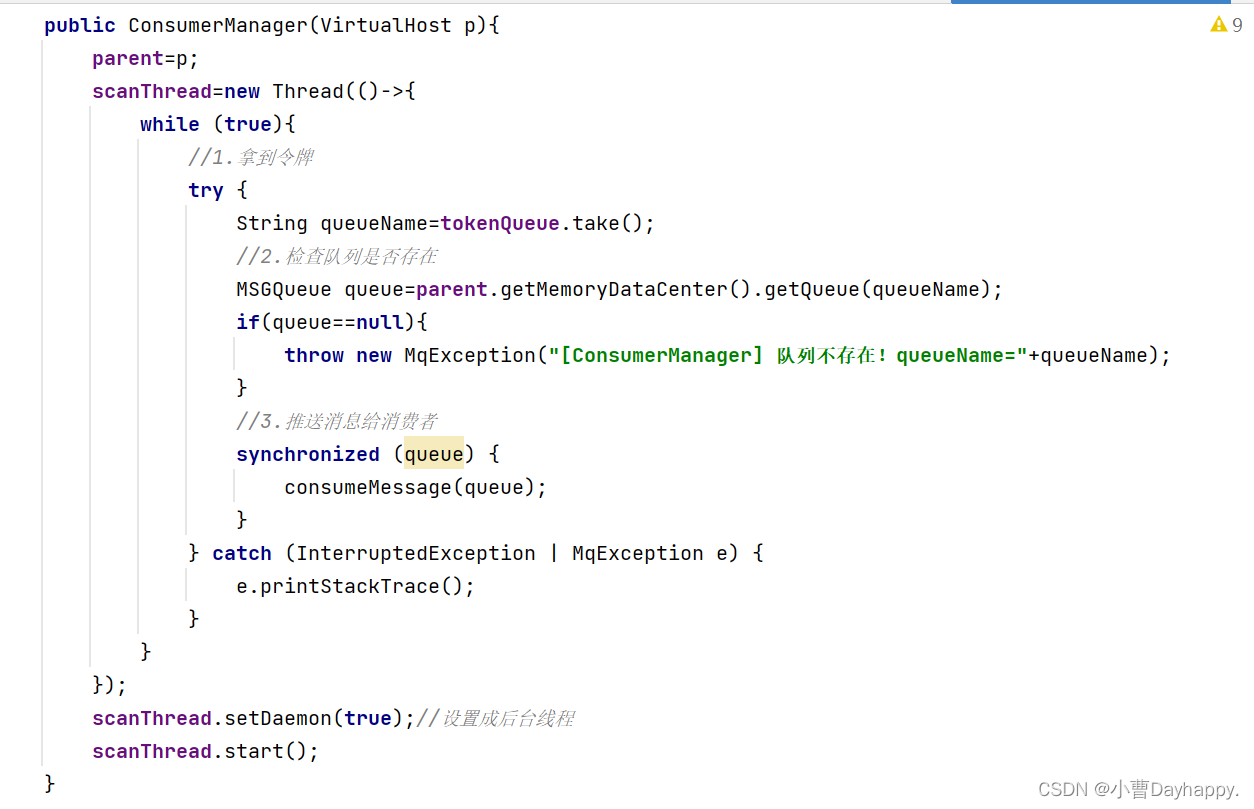
-
推送消息给消费者
- 挑选消费者
- 从队列取出消息
- 线程池执行回调,在执行回调前,将消息放入待确认消息集合
- 如果是自动确认,需要在此时删除消息(把消息从硬盘、消息集合、待确认消息集合删除)
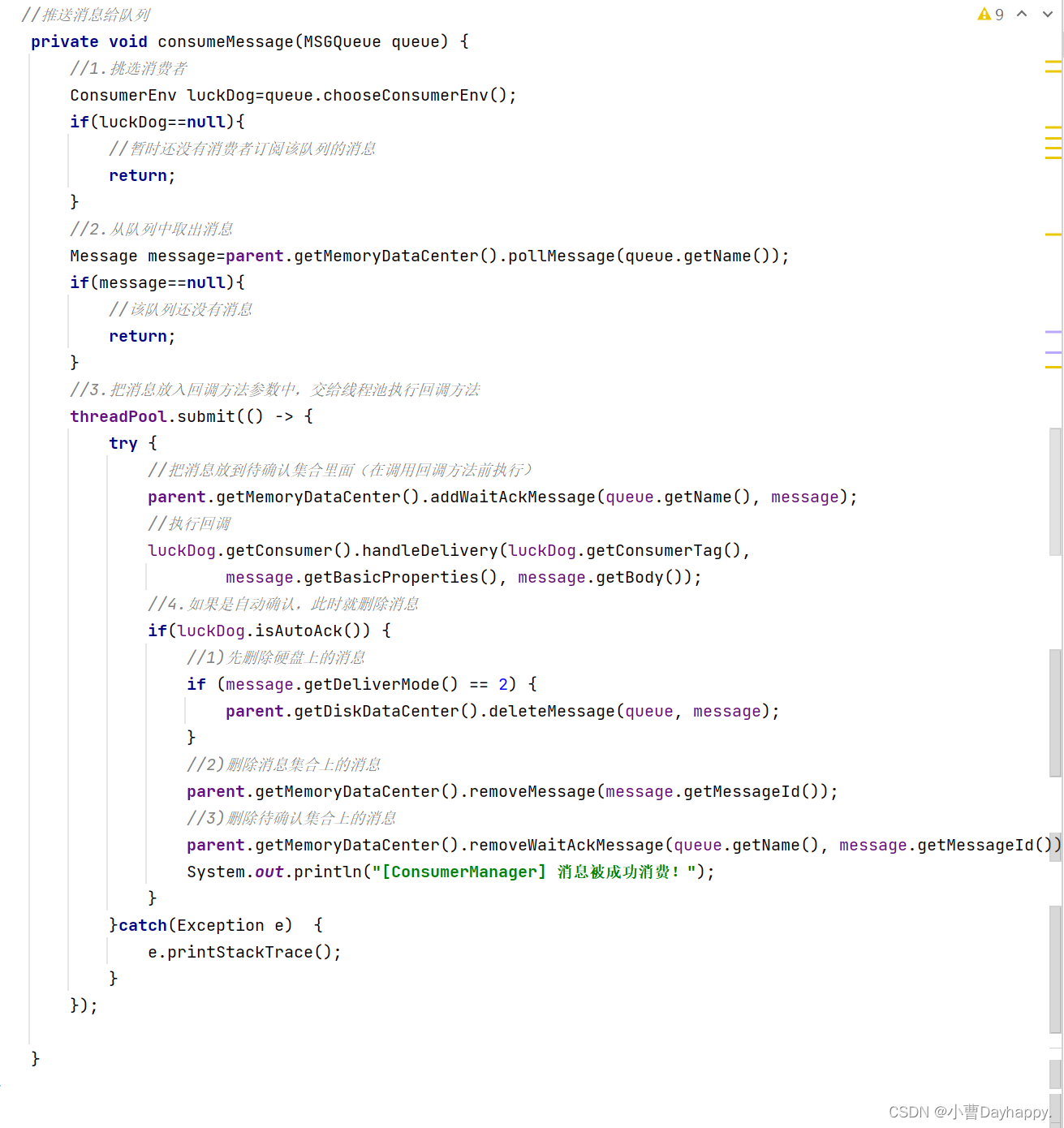
9.确认消息
消费者收到消息后,调用次方法,手动确认收到消息。
- 检查队列和消息是否存在
- 把消息从硬盘、消息集合、待确认消息集合删除