企业免费做网站wordpress轻物语主题
本节内容开始,我们正式学习TCP协议中具体的一些原理。首先,最重要的内容仍然是这个协议的封装结构和首部格式,因为这里面牵扯到一些环环相扣的知识点,例如ACK、SYN等等,如果这些内容不能很好的理解,那么后续学习中的连接建立、流量控制等知识就没办法学习下去了。
TCP报文的组成
经过前面的学习,我们至少已经知道了两件事情,一是TCP是具有可靠传输特性的传输层协议;二是使用TCP协议的传输层,其PDU是报文段(为什么是段,而不是整个的报文,我们后面学完UDP之后,会出一个对比和总结,此处先简单的把 报文段=报文 理解就可)。
TCP的报文段从整体来看,和IP数据包一样,也是首部+数据部分的格式,这里的首部自然就是TCP的协议首部,数据部分是上面的应用层传递下来的数据,如下图所示:
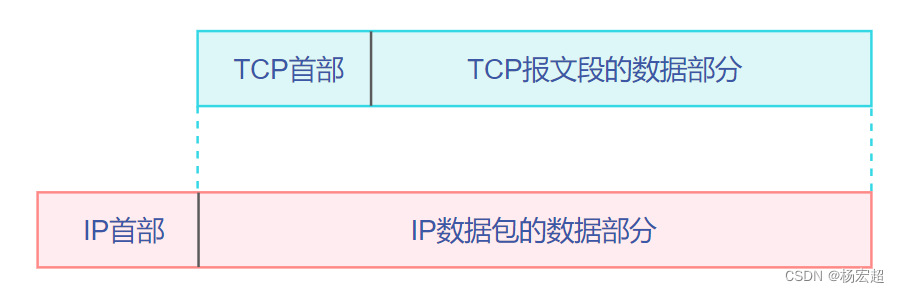
TCP首部结构
经过前面的数据链路层、网络层等协议封装格式的学习,就会发现一个规律:基本上每个协议所具有的功能都体现在其首部的各个字段当中。TCP协议也是不例外的,所以我们需要详细学习TCP的首部字段,不过限于篇幅,本节先学习其中的一部分。
首先来看TCP首部里面都包含哪些字段:
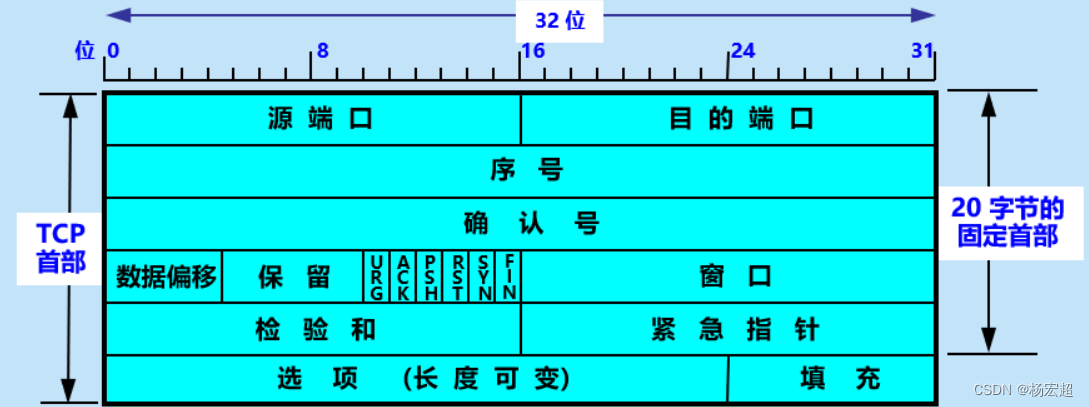
从图中可以看出,TCP报文的首部和IP数据包的首部有相似的地方,同样在最上方标注着每个字段占的长度是多少,例如第一个字段——源端口,长度为16个二进制位。另外,和IP首部一样,TCP也有20个字节的固定首部长度,也是最小首部长度,因为“选项”和“填充”两个字段是可选的,可以根据需要而增加。
首先第一个和第二个字段,也就是源端口和目的端口,前面学过了端口号,在这里就好理解了。这两个字段的值指出了发送方自己的端口号和对方的端口号,比如一台主机的浏览器想要通过HTTP协议访问一个服务器的网址,那么其TCP首部中的源端口就是自己主机浏览器程序的随机端口号,目的端口就是HTTP的熟知端口80。
源端口和目的端口的字段长度都是16位,所以端口号的取值范围就是0—(2^16)-1,也就是0~65535,对应了我们前面学到的端口号范围。
下面一个字段叫“序号”,也叫“报文段序号”,这个字段的值表示本报文段的数据部分的第一个字节的编号。前面我们学过给报文编号,主要是为了让接收方能够区分开一个报文段是新发送的还是重传的,以便接收端进行报文的确认。在TCP协议中,一个报文段的序号就是其数据部分的第一个字节的编号,意思就是说:假设一个TCP报文的数据部分有100个字节,这些数据的编号是1~100,这就说明这个报文段的首部中“序号”值是1;同理,如果这些数据的编号要是101~200,那就说明这个报文段的首部中“序号”值是101。总之应当记住,“序号”字段的值是本报文段的数据部分的第一个字节的编号。
当然上面这些只是举例子为了方便理解,在实际当中的“序号”字段的值没有这么“随便”,不过序号字段的值确实是随机的,当通信双方应用程序建立TCP连接的时候,双方都会自动生成一个随机数作为初始序号,也就是说第一个字节的序号不一定必须是1。
然后我们看到,“序号”字段的长度是32位,也就意味着序号的取值范围是0—(2^32)-1,大概四千多万个。虽然有这么大的取值范围,但毕竟是有限的,在使用高速网络时有可能会出现序号重复使用的情况。如果出现序号重复,就会导致接收方区别不了一个报文段是新到达的还是由于网络拥堵而"迟到"的,为了解决这种问题,在TCP首部的“选项”字段中可以选择加上时间戳选项,时间戳的一个重要功能就是防止序号绕回(PAWS)。
“序号”字段下面紧接着是“确认号”字段,确认号的意思是:期望收到对方下一个报文的序号。要理解确认号,就要特别注意“期望”这两个字。比如说,还是上面的例子,发送方A把序号为101,数据部分有100个字节的报文段发送过来,接收方B接收下来以后,那么B就“期望着”后面的数据到来,于是B将会在发送给A的确认报文中,将首部中的“确认号”字段设置成201。这就是告诉发送方A:“到序号200为止的字节我都已经收到,现在我期望收到200后面的201号字节”。
“确认号”在后面走,是4位长度的“数据偏移”字段,数据偏移指的是本报文段中的数据部分距离报文首部开始有多少个字节,其实也就可以理解为“首部长度”。因为TCP虽然有固定首部20字节,但是如果加入了长度可变的“选项”字段,首部长度就不固定了,所以通过一个字段来指出首部的长度是有必要的。
另外需要知道的是,TCP的首部也有一个最大长度,和IP一样,都是60字节。因为“数据偏移”字段长度有4位,4个二进制位能表示的最大数是1111,也就是十进制的15,而且这里也是以4个字节为单位,15×4(字节)=60(字节),这就是TCP的首部最大长度。
“数据偏移”字段后面是6位的“保留”字段,保留为今后使用,其值在目前应设置为0。
本节关于TCP首部先学习到这里,下一节继续学习后面的字段。
参考教材:谢希仁《计算机网络》第八版