帝国网站数据库配置文件网站点击量设计
1. OBS 与区域录屏
实际上 OBS 的使用场景可谓是与区域录屏格格不入的。
虽然我们依旧有一些办法在 OBS 中达到区域录屏的目的,但其操作实在过于繁琐,还不如直接使用 QQ 或者 Windows 最新的自带截屏录屏来进行区域录屏来的方便实在。
但若非常强烈的想使用 OBS 进行区域录屏,本文的方法确实是一种可行手段。
2. 操作过程
首先我们添加一个完整的“显示器采集”,并对其右键->调整输出大小(源大小)。此时 OBS 的输出大小便调整为了“显示器采集”的源大小。
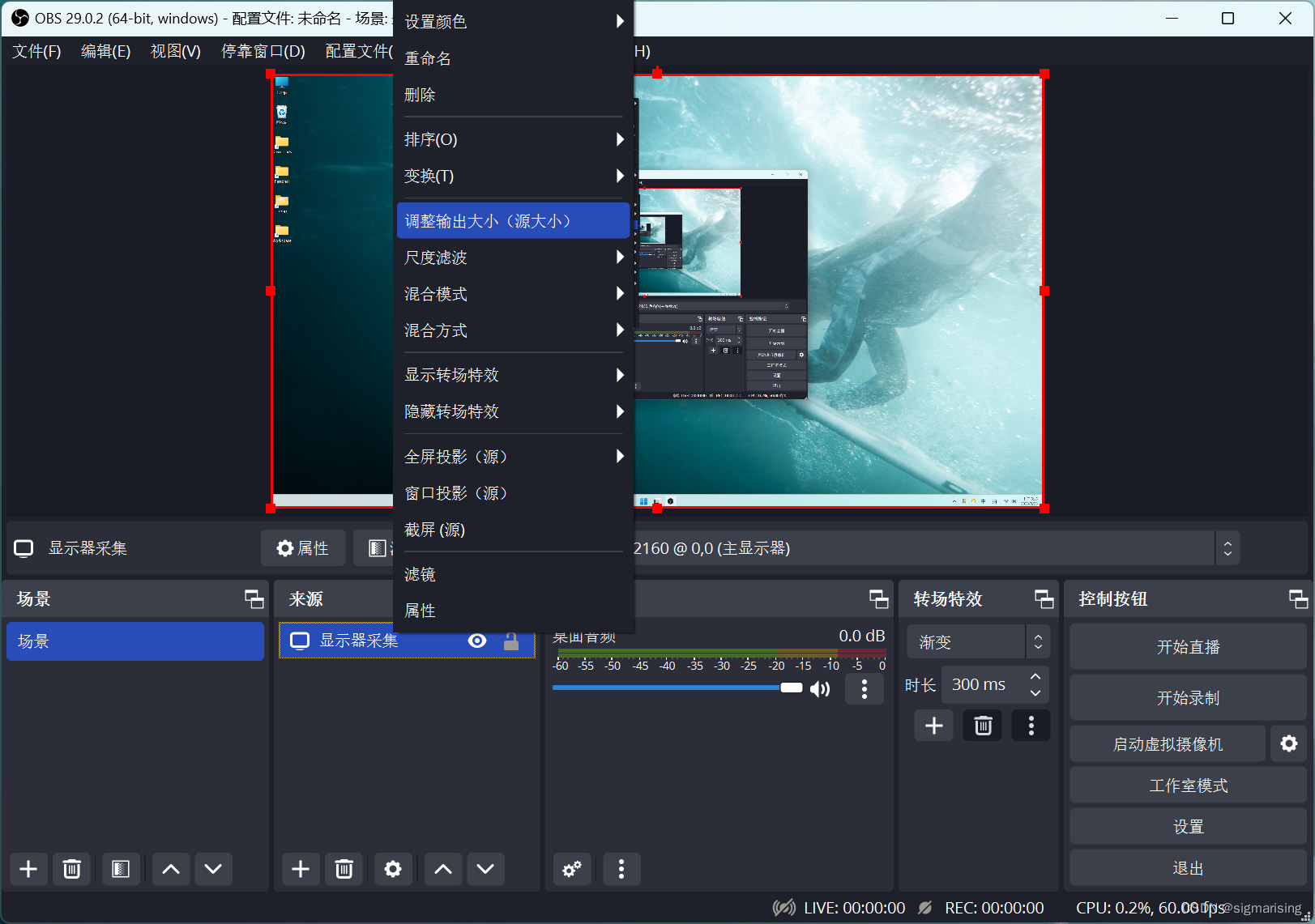
接下来我们添加一个“色源”,可以直接拖拽移动其位置,并在属性对话框中直接编辑其宽度和高度,使这个“色源”的大小恰好相当于想要进行区域录屏的位置。
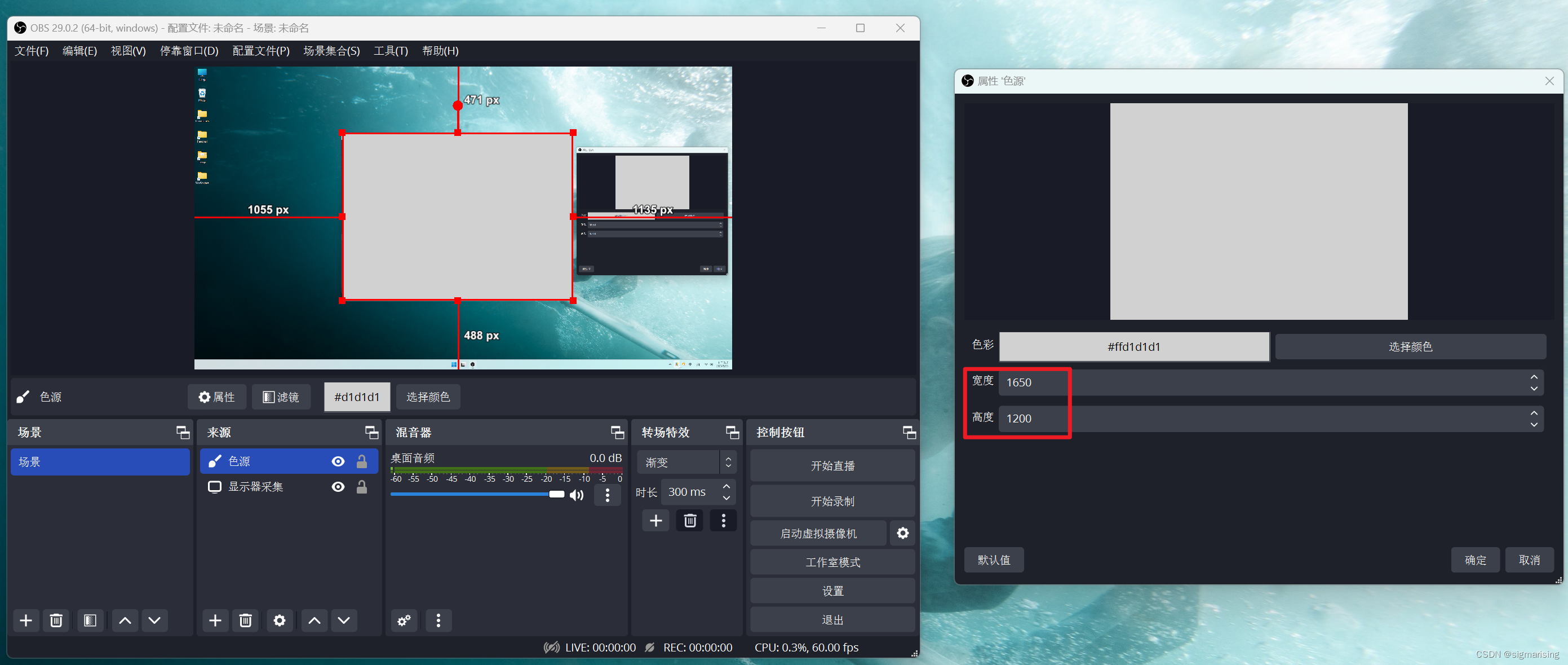
注意:不要拖动或按住 Alt 后拖动“色源”的四角来进行缩放或裁切,这些操作并不会改变“色源”的源大小。很多现有的网络教程均采用这种方法来进行 OBS 区域录屏的教学,但这实际上是不正确的,因为 OBS 输出大小并不会被调整。
接下来在“色源”上右键->调整输出大小(源大小)。这时 OBS 输出大小已经成为了最终想要进行区域录屏的大小了(可以将“色源”显示层级拖动到最后,避免遮挡“显示器采集”)。
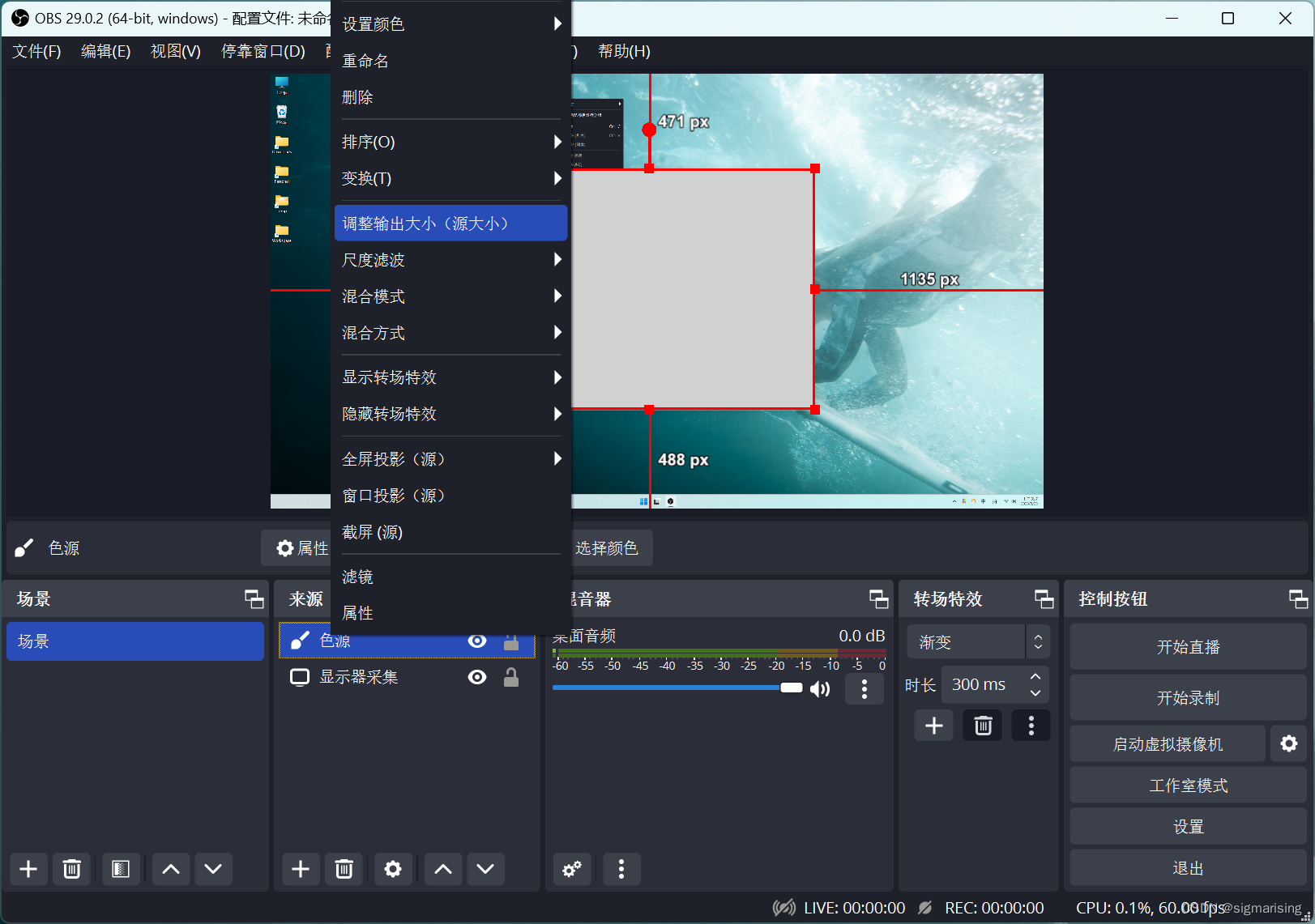
然后我们可以拖拽移动“显示器采集”,使我们想要采集的内容刚好处于画布上即可。
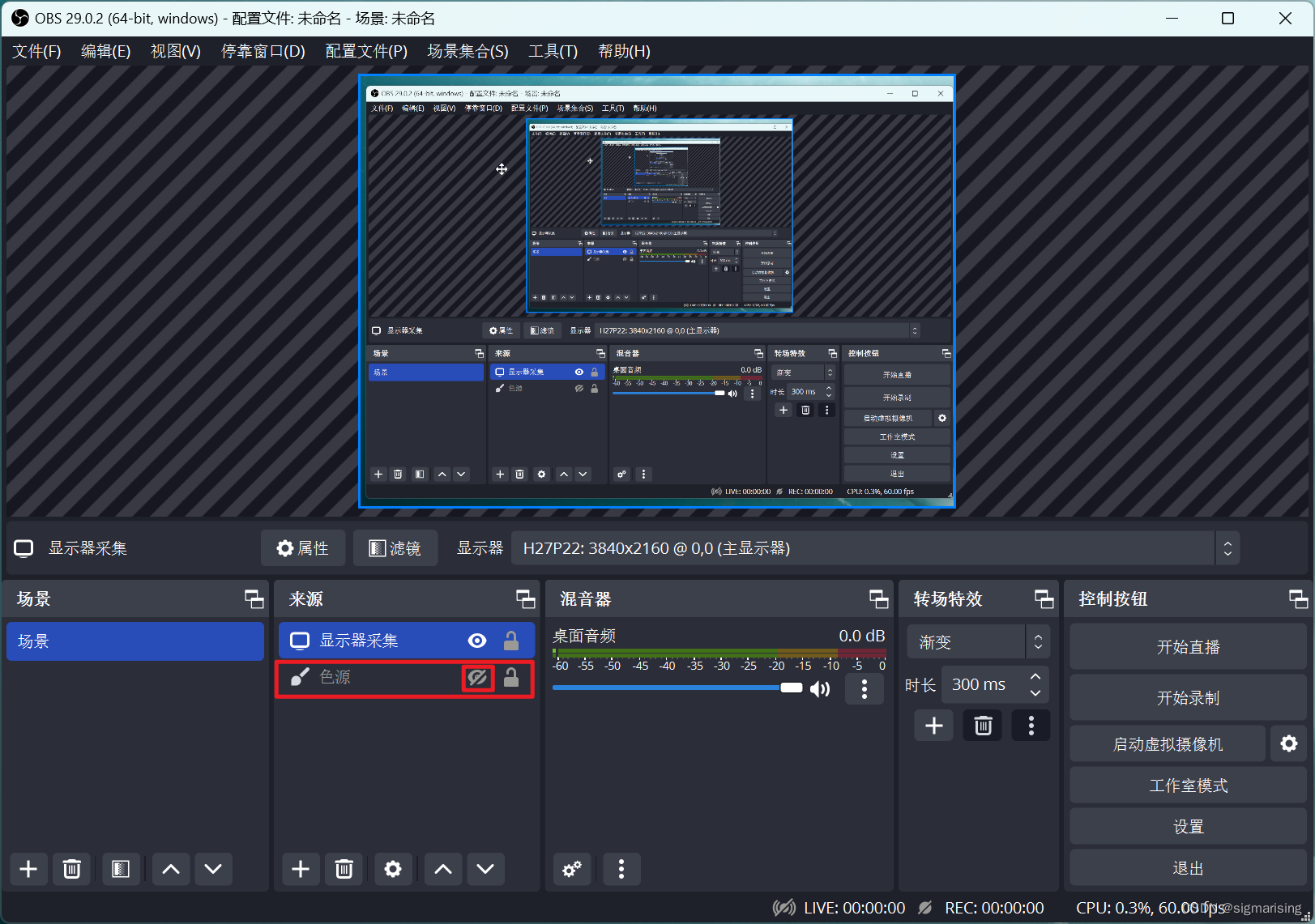
最后进行录制和输出即可。