个人域名可以建公司网站吗wordpress评论回复通知
一、本文介绍
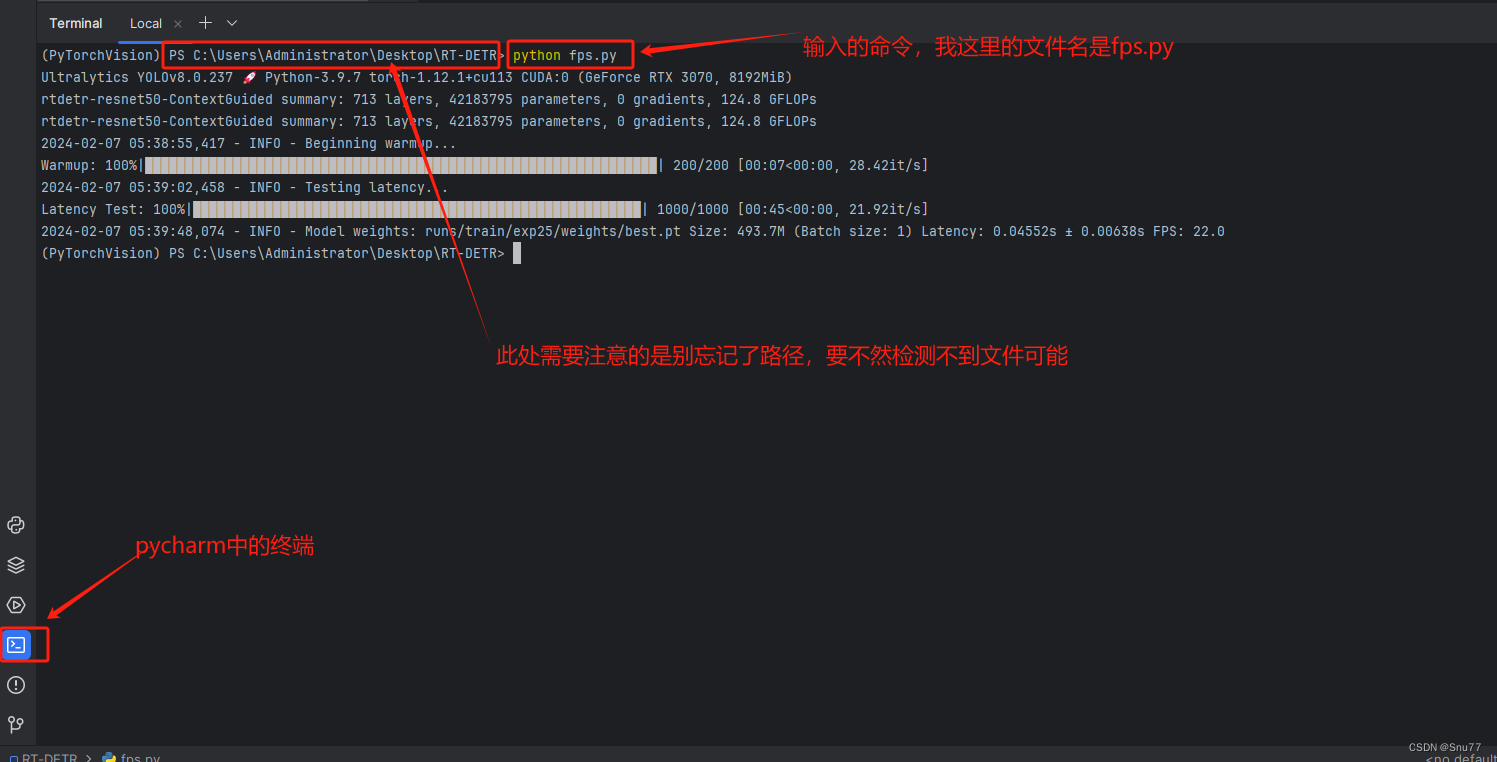
本文给大家带来的改进机制是利用我们训练好的权重文件计算FPS,同时打印每张图片所利用的平均时间,模型大小(以MB为单位),同时支持batch_size功能的选择,对于轻量化模型的读者来说,本文的内容对你一定有帮助,可以清晰帮你展示出模型速度性能的提升以及轻量化的效果(模型大小),对于以提高精度为目的的读者本文也能够帮助大家展示出现阶段的模型速度指标。所以本文的内容是十分有用的机制,对于大家发表论文来说,下面的图片为运行后的效果可以看到,该有的指标均已打印(本文内容为我独家创新,全网无第二份)。
欢迎大家订阅我的专栏一起学习YOLO!
目录