百度论坛首页大型网站和小企业站优化思路
- 二叉搜索树(Binary Search Tree,简称 BST)是一种数据结构,用于存储具有可比较键(通常是数字或字符串)的元素
1 结构特点
- 节点结构:每个节点都有一个键和两个子节点(左子节点和右子节点)。
- 排序特性:
- 若左子树不空,则左子树上所有节点的值都小于根节点的值
-
若右子树不空,则右子树上所有节点的值都大于根节点的值;
- 左子树和右子树也分别是二叉搜索树。
这样的特性使得二叉搜索树能高效地支持多种查找和动态集合操作。
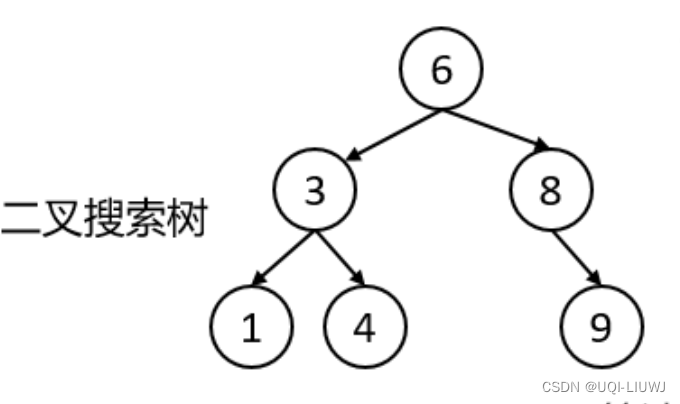
二叉搜索树有一个重要特性就是他的中序遍历结果一定是有序的
2 二叉搜索树的查找
-
如果当前节点为空,则搜索失败。
-
否则,如果当前节点的值等于要查找的值,则直接返回。
-
否则,如果要查找的值比当前节点小,就往当前节点的左子树找。如果要查找的值比当前节点值大,就往当前节点的右子树找。

3 二叉搜索树的插入
首先找到他需要插入的位置,然后再插入
-
如果当前节点为空,直接创建一个新的节点返回。
-
如果要插入的值比当前节点小,就往当前节点的左子树查找插入的位置。
-
如果要插入的值比当前节点大,就往当前节点的右子树查找插入的位置。

4 二叉搜索树的删除
- 如果删除的是叶子节点,则直接删除
- 如果删除的节点只有一个子节点,让这个仅有的子节点替代他
- 如果删除的节点有两个子节点,就需要考虑删除当前节点后子节点该怎么存放
- 删除有两种实现方式,一种是直接删除需要删除的节点,一种是使用移形换位法
- 直接删除有个缺点就是会导致树严重不平衡
- AVL 树和红黑树都是移形换位法
- 删除有两种实现方式,一种是直接删除需要删除的节点,一种是使用移形换位法
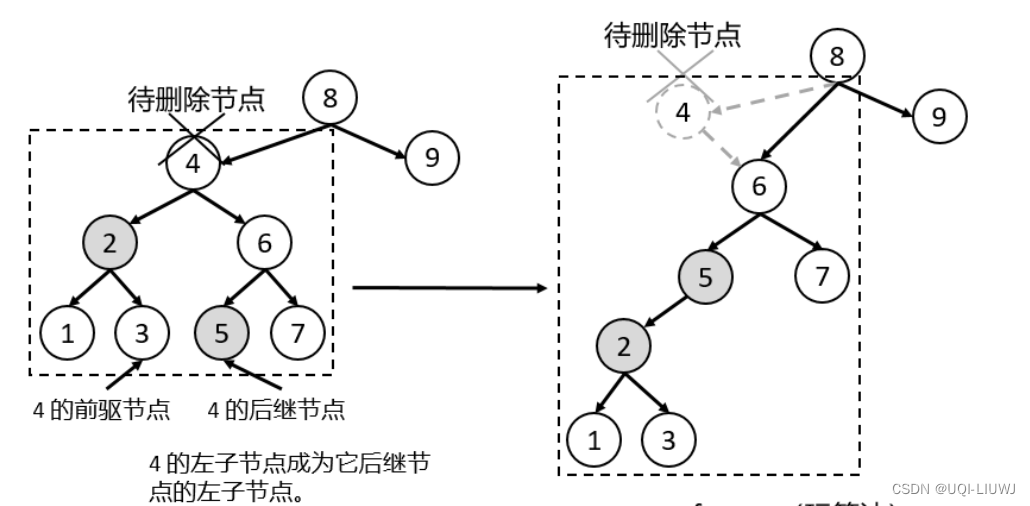
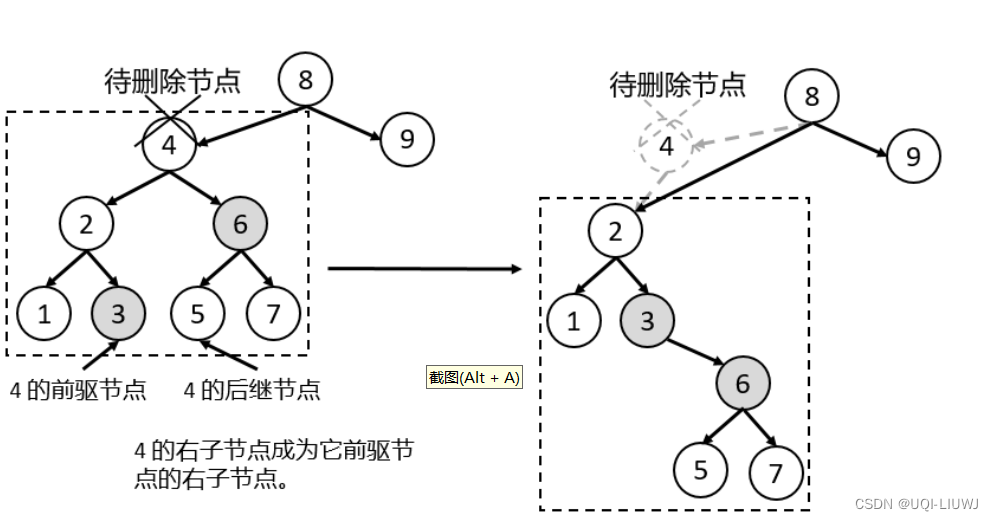
4.1 前驱节点和后驱节点
- 前驱节点:对一棵二叉树进行中序遍历,遍历后的结果中,当前节点的前一个节点为该节点的前驱节点;
- 后继节点:对一棵二叉树进行中序遍历,遍历后的结果中,当前节点的后一个节点为该节点的后继节点;
- 当然,查找一个节点的前驱节点和后继节点不一定需要打印二叉树的中序遍历结果这么麻烦
- 一个节点的前驱节点是他左子树中的最大节点,这个节点就是他左子树往右一直走下去的节点
- 一个节点的后继节点就是他右子树的最小节点,这个节点就是他右子树往左一直走下去的节点
4.2 直接删除
直接删除的缺点就是会严重破坏树的平衡性
4.2.1 方法1:让待删除节点的右子节点成为他前驱节点的右子节点
4.2.2 方法2:让待删除节点的左子节点成为他后继节点的左子节点