动态手机网站上海app开发外包
背景
记得在刚学C语言时,写了一篇栈实现计算器-CSDN博客文章。偶然间看到了文章的阅读量以及评论,居然有1.7w的展现和多条博友的点评,反馈。
现在回过头来看,的确有许多不严谨的地方,毕竟当时分享文章时,还未毕业。理论和思维还不够严谨。但是我还依稀记得,班级上当时写出这个程序的同学,稀疏可数。所以在当时,还是有骄傲的资本的。本着对技术精益求精的态度,再通过本篇文章希望能够帮助刚接触C语言的朋友,也是给过去的自己一个满意的答复~
规则
对于一个表达式,我们应该如何去识别它呢?当时,老师和我们说,按照如下规则进行解析即可。

当时我们并不懂这个规则的由来,只知道按照这个规则去编程即可。再后来的工作中,因为考《软件设计师》资格证,了解到上述的规则,其实就是后缀表达式。同理还有前缀表达式,中缀表达式。
中缀表达式
中缀表达式就是我们常用的一种算数表示方式。它的特点是操作符以中缀的方式处于操作数中间。但是中缀表达比较适合人类计算,对于计算机而言过于复杂。前缀表达式和后缀表达式对于计算机而言,更加友好。
因此,我们想用程序实现计算器功能,有两种方式:
中缀表达式--> 前缀表达式-->计算
中缀表达式--> 后缀表达式-->计算
前缀表达式
前缀表达式的运算符位于两个操作数之前,又称为前缀记法或波兰式。比如表达式(中缀)5+4,前缀表达式+ 5 4。因此使用前缀表达式进行计算,需要两个步骤。
-
如何将中缀表达式转换为前缀表达式
-
计算机如何识别前缀表达式并计算
中缀表达式转换前缀表达式
根据文中描述,中缀表达式转换为前缀表达式的规则如下:
-
初始化两个栈:运算符栈S1和存储中间结果的栈S2;
-
从右至左扫描中缀表达式;
-
遇到操作数时,将其压入S2;
-
遇到运算符时,比较其与S1栈顶运算符的优先级;
-
如果S1为空,或栈顶运算符为右括号
),则将此运算符入栈; -
否则,若优先级比栈顶运算符的较高或相等,也将运算符压入S1;
-
否则,将S1栈顶的运算符弹出并压入到S2,再次转到
4.1与S1中新的栈顶运算符相比较;
-
-
遇到括号时:
-
如果是右括号
),则直接压入S1; -
如果是左括号
(,则依次弹出S1栈顶的运算符,并压入S2,直到遇到右括号为止,此时将这一对括号丢弃;
-
-
重复步骤
2至5,直到表达式的最左边; -
将S1中剩余的运算符依次弹出并压入S2;
-
依次弹出S2中的元素并输出,结果即为中缀表达式对应的前缀表达式。
虽然规则很复杂,但是编码难度并不是很大,大家可以按照自己的技术能力尝试一下。
分析思路
我们以表达式1+(2+3)*4-5举例。
1. 因为输入表达式是字符串,后续我们需要从右往左扫描表达式,因此首先需要将字符串表达式中的运算符和操作数进行区分,可以用整型数组如下图:

2. 根据2至5规则,进行分析。


3. 弹出S2中的数据元素:- + 1 * + 2 3 4 5;
代码示例
我的代码示例如下:
#include<stdlib.h>
#include<stdio.h>
#include<string.h>
#include<stdint.h>
#include<stdbool.h>#define STACK_LEN 1024/** 中缀表达式栈*/
static int32_t g_infix_expression[1024] = {0};/** 前缀表达式栈*/
static int32_t g_prefix_expression[1024] = {0};/** 后缀表达式栈*/
static int32_t g_suffix_expression[1024] = {0};/*** @brief 将输入的字符串表达式转换为中缀表达式** @param [in] expression 字符串表达式* @return int 0 成功 non-0 失败* */
int expression2infix(const char* expression)
{if(expression == NULL){printf("input error\n");return -1;}int dataTmp = 0; //表达式中的操作数bool dataFlag = false; // 操作数标识,表示当前是否有数据需要入栈const char* ptr = expression;int32_t* infix_index = g_infix_expression;printf("expression = %s\n",expression);while(*ptr != '\0'){/** 字符为数字*/if('0' <= *ptr && *ptr <= '9'){dataTmp = dataTmp*10 +(*ptr - '0');dataFlag = true;}/**字符为操作符或括号*/else if(*ptr == '+' || *ptr == '-' || *ptr == '*' || *ptr == '/' || *ptr == '(' || *ptr == ')'){if(dataFlag == true){*(infix_index++) = dataTmp;dataFlag = false;dataTmp = 0;}*(infix_index++) = *ptr;}else{printf("wrong exptrssion\n");return -1;}ptr++;}/**将最后一个操作数,入栈*/if(dataFlag == true){*(infix_index++) = dataTmp;dataFlag = false;dataTmp = 0;}return 0;
}/*** @brief 将中缀表达式转换为前缀表达式** @return int 0 成功 non-0 失败* */
int infix2prefixExpression()
{/**初始化运算符栈和中间结果栈*/int32_t stack_s1[STACK_LEN] = {0};int32_t stack_s1_top = 0;int32_t stack_s2[STACK_LEN] = {0};int32_t stack_s2_top = 0; int32_t * index = g_infix_expression;/**获取中缀表达式最右侧操作数*/while(*(index+1) != 0){index++;}while(index != g_infix_expression){/** 操作符*/if(*index == '+' || *index == '-' || *index == '*' || *index == '/'){while(true){/**S1为空,或栈顶运算符为右括号),则将此运算符入栈*/if(stack_s1_top == 0 || stack_s1[stack_s1_top-1] == ')' || stack_s1[stack_s1_top-1] == '-'|| stack_s1[stack_s1_top-1] == '+'){stack_s1[stack_s1_top++] = *index;break;}stack_s2[stack_s2_top++] = stack_s1[stack_s1_top-1];stack_s1[stack_s1_top-1] = 0;stack_s1_top = stack_s1_top -1;}}/**左括号* 则依次弹出S1栈顶的运算符,并压入S2,直到遇到右括号为止*/else if(*index == '('){while(true){/**异常*/if(stack_s1_top == 0){printf("infix experssion worong\n");return -1;}/**遇到右括号,丢弃括号*/if(stack_s1[stack_s1_top-1] == ')'){stack_s1[stack_s1_top-1] = 0;stack_s1_top = stack_s1_top -1;break;}/**其它符号需要入栈S2*/else{stack_s2[stack_s2_top++] = stack_s1[stack_s1_top-1];stack_s1[stack_s1_top-1] = 0;stack_s1_top--;}}}/**右括号* 直接入运算符栈s1*/else if(*index == ')'){stack_s1[stack_s1_top++] = *index;}/** 操作数* 直接加入栈s2*/else{stack_s2[stack_s2_top++] = *index;}index--;
#if 0printf("==============\n");printf("stack_s1=");for(int i = 0 ; i < stack_s1_top; i++){(stack_s1[i] > 9) ? (printf("%c ",stack_s1[i])):(printf("%d ",stack_s1[i]));}printf("\n");printf("stack_s2=");for(int i = 0 ; i < stack_s2_top; i++){(stack_s2[i] > 9) ? (printf("%c ",stack_s2[i])):(printf("%d ",stack_s2[i]));}printf("\n");
#endif }/**将最左侧操作数压入s2*/stack_s2[stack_s2_top++] = *index;/**将s1中的符号压入s2*/for(int i = stack_s1_top - 1; i >= 0; i-- ){stack_s2[stack_s2_top++] = stack_s1[i];stack_s1[i] = 0; }/**将s2中的数据弹出,放入前缀表达式栈中*/for(int i = 0 ; stack_s2_top > 0; i++,stack_s2_top--){g_prefix_expression[i] = stack_s2[stack_s2_top-1];}return 0;
}int main(int argc,char* argv[])
{if(argc != 2){printf("please input experssion\n");return -1;}int32_t iRet = 0;iRet = expression2infix(argv[1]);if(iRet == 0){for(int i = 0 ; i < STACK_LEN && g_infix_expression[i] != 0; i++){if(g_infix_expression[i] == '+' || g_infix_expression[i] == '-' || g_infix_expression[i] == '*' || g_infix_expression[i] == '/'){printf("%c ",g_infix_expression[i]);}else{printf("%d ",g_infix_expression[i]);}}printf("\n");}iRet = infix2prefixExpression();if(iRet == 0){for(int i = 0 ; i < STACK_LEN && g_prefix_expression[i] != 0; i++){if(g_infix_expression[i] == '+' || g_infix_expression[i] == '-' || g_infix_expression[i] == '*' || g_infix_expression[i] == '/'){printf("%c ",g_infix_expression[i]);}else{printf("%d ",g_infix_expression[i]);}}printf("\n");}prefixExpressionCaculate();return 0;
}
前缀表达式计算
前缀表达式的计算规则如下:
-
从右至左扫描表达式;
-
遇到数字,压入栈中;
-
遇到运算符,弹出栈顶的两个数,并用运算符对这两个数做相应的计算,并将结果入栈;
-
重复上述
2,3步骤,直到表达式最左端,最后的值为表达式的结果。
分析思路
以上述后缀表达式举例:- + 1 * + 2 3 4 5。

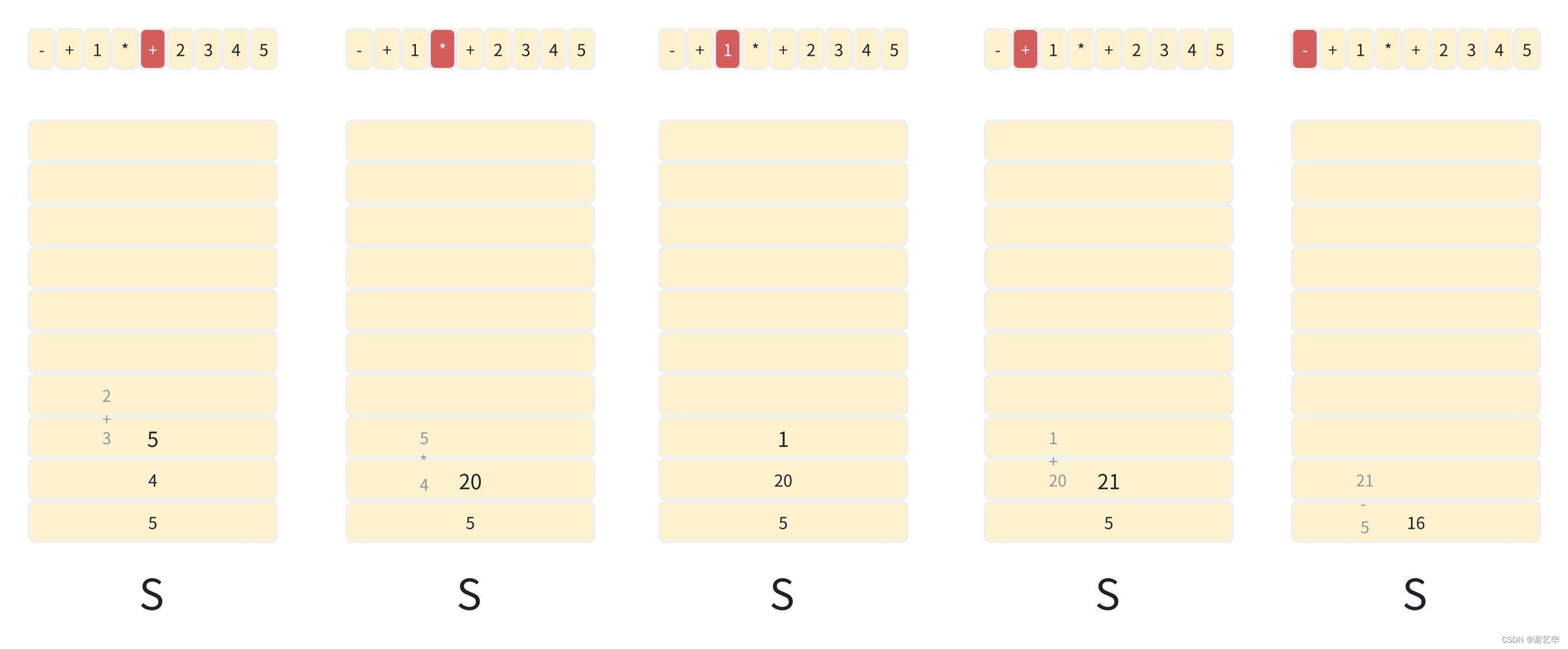
得出结果为16。
代码示例
新增prefixExpressionCaculate接口。代码如下:
/*** @brief 将前缀表达式进行计算** @return int 0 成功 non-0 失败* */
int prefixExpressionCaculate()
{/**结果栈*/int32_t stack[1024] = {0};int32_t stack_len = 0;/**临时结果*/int32_t tmpResult = 0;int32_t data1 = 0;int32_t data2 = 0;/**获取后缀表达式的最右侧操作数*/int32_t* index = g_prefix_expression;while(*(index+1) != 0){index++;}while(index >= g_prefix_expression){/**弹出栈顶的两个数,并用运算符对这两个数做相应的计算,并将结果入栈*/if(*index == '+' || *index == '-' || *index == '*' || *index == '/'){data1 = stack[stack_len-1];data2 = stack[stack_len-2];if(*index == '+'){tmpResult = data1 + data2;}else if(*index == '-'){tmpResult = data1 - data2;}else if(*index == '*'){tmpResult = data1 * data2;}else if(*index == '/'){tmpResult = data1 / data2;}else{printf("worng prefixExperssion\n");return -1;}stack[stack_len-1] = 0;stack[stack_len-2] = tmpResult;stack_len --;}/**遇到数字,压栈*/else{stack[stack_len] = *index;stack_len ++;}index --;}printf("result = %d\n",stack[0]);return 0;
}演示

后缀表达式
后缀表达式与前缀表达式类似,只是运算符位于两个相应操作数之后,后缀表达式也称为后缀记法或逆波兰式。同样,我们需要解决两个问题。
-
如何将中缀表达式转换为后缀表达式
-
后缀表达式的计算规则
中缀表达式转后缀表达式
根据文中描述,中缀表达式转换为后缀表达式的规则如下:
-
初始化两个栈:运算符栈S1和存储中间结果的栈S2;
-
从左至右扫描中缀表达式;
-
遇到操作数时,将其压入S2;
-
遇到运算符时,比较其与S1栈顶运算符的优先级;
-
如果S1为空,或栈顶运算符为左括号
(,则将此运算符入栈; -
否则,若优先级比栈顶运算符的高,也将运算符压入S1;(注意是必须为高,相同或低于都不行)
-
否则,将S1栈顶的运算符弹出并压入到S2,再次转到
4.2与S1中新的栈顶运算符相比较;
-
-
遇到括号时:
-
如果是左括号
(,则直接压入S1; -
如果是右括号
),则依次弹出S1栈顶的运算符,并压入S2,直到遇到左括号为止,此时将这一对括号丢弃;
-
-
重复步骤
2至5,直到表达式的最右边; -
将S1中剩余的运算符依次弹出并压入S2;
-
依次弹出S2中的元素并输出,结果即为中缀表达式对应的后缀表达式。
后缀表达式计算规则
后缀表达式的计算规则如下:
-
从左至右扫描表达式;
-
遇到数字,压入栈中;
-
遇到运算符,弹出栈顶的两个数,并用运算符对这两个数做相应的计算,并将结果入栈;
-
重复上述
2,3步骤,直到表达式最右端,最后的值为表达式的结果。
后缀表达式的代码示例可以参考前缀表达式的分析思路和代码,大家可以尝试编写。
总结
时间流逝,在竞争激烈的社会背景下,我们的身处IT行业,不断逼迫自己去学习,去成长。但是总会觉得自己做的还不够。为什么总是赶不上别人的脚步,陷入怀疑自我的处境。
朋友们,偶尔回头看看来时路上的自己,你会发现,你一直在成长,你的努力一直是正向反馈着你,不要轻视自己的努力。感谢csdn给予记录成长的平台,也感谢一直努力的自己。共勉~

参考文档
前缀表达式、中缀表达式和后缀表达式 - 乘月归 - 博客园
数据结构和算法(六):前缀、中缀、后缀表达式