汽车之家网站是谁做的一流的品牌网站建设
OpenFeign 万字教程详解
目录
-
一、概述
-
- 1.1.OpenFeign是什么?
- 1.2.OpenFeign能干什么
- 1.3.OpenFeign和Feign的区别
- 1.4.@FeignClient
-
二、OpenFeign使用
-
- 2.1.OpenFeign 常规远程调用
- 2.2.OpenFeign 微服务使用步骤
- 2.3.OpenFeign 超时控制
- 2.4.OpenFeign 日志打印
- 2.5.OpenFeign 添加Header
- 2.6.手动创建 Feign 客户端
- 2.7.Feign 继承支持
- 2.8.Feign 和Cache集成
- 2.9.OAuth2 支持
一、概述
1.1.OpenFeign是什么?
Feign是一个声明式的Web服务客户端(Web服务客户端就是Http客户端),让编写Web服务客户端变得非常容易,只需创建一个接口并在接口上添加注解即可。
cloud官网介绍Feign: https://docs.spring.io/spring-cloud-openfeign/docs/current/reference/html/
OpenFeign源码: https://github.com/OpenFeign/feign
1.2.OpenFeign能干什么
Java当中常见的Http客户端有很多,除了Feign,类似的还有Apache 的 HttpClient 以及OKHttp3,还有SpringBoot自带的RestTemplate这些都是Java当中常用的HTTP 请求工具。
什么是Http客户端?
❝
当我们自己的后端项目中 需要 调用别的项目的接口的时候,就需要通过Http客户端来调用。在实际开发当中经常会遇到这种场景,比如微服务之间调用,除了微服务之外,可能有时候会涉及到对接一些第三方接口也需要使用到 Http客户端 来调用 第三方接口。
❞
所有的客户端相比较,Feign更加简单一点,在Feign的实现下,我们只需创建一个接口并使用注解的方式来配置它(以前是Dao接口上面标注Mapper注解,现在是一个微服务接口上面标注一个Feign注解即可),即可完成对服务提供方的接口绑定。
1.3.OpenFeign和Feign的区别
Feign:
Feign是Spring Cloud组件中的一个轻量级RESTful的HTTP服务客户端,Feign内置了Ribbon,用来做客户端负载均衡,去调用服务注册中心的服务。Feign的使用方式是:使用Feign的注解定义接口,调用这个接口,就可以调用服务注册中心的服务。
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-feign</artifactId>
</dependency>
OpenFeign:
OpenFeign是Spring Cloud 在Feign的基础上支持了SpringMVC的注解,如@RequesMapping等等。OpenFeign的@FeignClient可以解析SpringMVC的@RequestMapping注解下的接口,并通过动态代理的方式产生实现类,实现类中做负载均衡并调用其他服务。
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
Feign是在2019就已经不再更新了,通过maven网站就可以看出来,随之取代的是OpenFeign,从名字上就可以知道,他是Feign的升级版。
1.4.@FeignClient
使用OpenFeign就一定会用到这个注解,@FeignClient属性如下:
- **name:**指定该类的容器名称,类似于@Service(容器名称)
- url: url一般用于调试,可以手动指定@FeignClient调用的地址
- *decode404:*当发生http 404错误时,如果该字段位true,会调用decoder进行解码,否则抛出FeignException
- configuration: Feign配置类,可以自定义Feign的Encoder、Decoder、LogLevel、Contract
- fallback: 定义容错的处理类,当调用远程接口失败或超时时,会调用对应接口的容错逻辑,fallback指定的类必须实现@FeignClient标记的接口
- fallbackFactory: 工厂类,用于生成fallback类示例,通过这个属性我们可以实现每个接口通用的容错逻辑,减少重复的代码
- path: 定义当前FeignClient的统一前缀,当我们项目中配置了server.context-path,server.servlet-path时使用
下面这两种本质上没有什么区别:
他们都是一个作用就是将FeignClient注入到spring容器当中
@FeignClient(name = "feignTestService", url = "http://localhost/8001")
public interface FeignTestService {
}
@Component
@FeignClient(url = "http://localhost/8001")
public interface PaymentFeignService{
}
远程调用接口当中,一般我们称提供接口的服务为提供者,而调用接口的服务为消费者。而OpenFeign一定是用在消费者上。
二、OpenFeign使用
2.1.OpenFeign 常规远程调用
所谓常规远程调用,指的是对接第三方接口,和第三方并不是微服务模块关系,所以肯定不可能通过注册中心来调用服务。
第一步:导入OpenFeign的依赖
第二步:启动类需要添加@EnableFeignClients
第三步:提供者的接口
@RestController
@RequestMapping("/test")
public class FeignTestController {@GetMapping("/selectPaymentList")public CommonResult<Payment> selectPaymentList(@RequestParam int pageIndex, @RequestParam int pageSize) {System.out.println(pageIndex);System.out.println(pageSize);Payment payment = new Payment();payment.setSerial("222222222");return new CommonResult(200, "查询成功, 服务端口:" + payment);}@GetMapping(value = "/selectPaymentListByQuery")public CommonResult<Payment> selectPaymentListByQuery(Payment payment) {System.out.println(payment);return new CommonResult(200, "查询成功, 服务端口:" + null);}@PostMapping(value = "/create", consumes = "application/json")public CommonResult<Payment> create(@RequestBody Payment payment) {System.out.println(payment);return new CommonResult(200, "查询成功, 服务端口:" + null);}@GetMapping("/getPaymentById/{id}")public CommonResult<Payment> getPaymentById(@PathVariable("id") String id) {System.out.println(id);return new CommonResult(200, "查询成功, 服务端口:" + null);}
}
第四步:消费者调用提供者接口
@FeignClient(name = "feignTestService", url = "http://localhost/8001")
public interface FeignTestService {@GetMapping(value = "/payment/selectPaymentList")CommonResult<Payment> selectPaymentList(@RequestParam int pageIndex, @RequestParam int pageSize);@GetMapping(value = "/payment/selectPaymentListByQuery")CommonResult<Payment> selectPaymentListByQuery(@SpringQueryMap Payment payment);@PostMapping(value = "/payment/create", consumes = "application/json")CommonResult<Payment> create(@RequestBody Payment payment);@GetMapping("/payment/getPaymentById/{id}")CommonResult<Payment> getPaymentById(@PathVariable("id") String id);
}
@SpringQueryMap注解
❝
spring cloud项目使用feign的时候都会发现一个问题,就是get方式无法解析对象参数。其实feign是支持对象传递的,但是得是Map形式,而且不能为空,与spring在机制上不兼容,因此无法使用。spring cloud在2.1.x版本中提供了@SpringQueryMap注解,可以传递对象参数,框架自动解析。
❞
2.2.OpenFeign 微服务使用步骤
微服务之间使用OpenFeign,肯定是要通过注册中心来访问服务的。提供者将自己的ip+端口号注册到注册中心,然后对外提供一个服务名称,消费者根据服务名称去注册中心当中寻找ip和端口。
第一步:导入OpenFeign的依赖
第二步:启动类需要添加@EnableFeignClients
第三步:作为消费者,想要调用提供者需要掌握以下
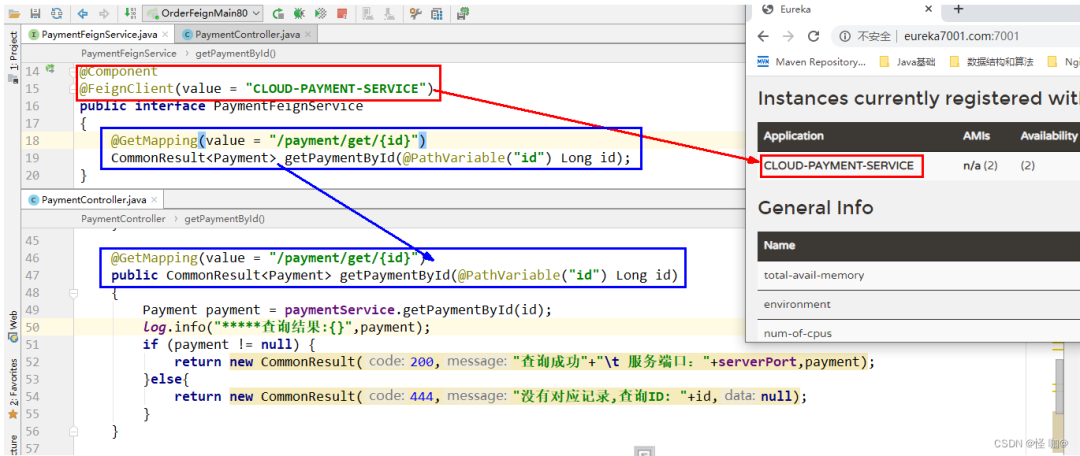
CLOUD-PAYMENT-SERVICE是提供者的服务名称。消费者要想通过服务名称来调用提供者,那么就一定需要配置注册中心当中的服务发现功能。假如提供者使用的是Eureka,那么消费者就需要配置Eureka的服务发现,假如是consul就需要配置consul的服务发现。
@Component
@FeignClient(value = "CLOUD-PAYMENT-SERVICE")
public interface PaymentFeignService {@GetMapping(value = "/payment/get/{id}")CommonResult<Payment> getPaymentById(@PathVariable("id") Long id);
}
第四步:提供者的接口,提供者可以是集群
@RestController
@Slf4j
public class PaymentController {@Autowiredprivate PaymentMapper paymentMapper;@Value("${server.port}")private String serverPort;@GetMapping(value = "/payment/get/{id}")public CommonResult<Payment> getPaymentById(@PathVariable("id") Long id) {Payment payment = paymentMapper.selectById(id);log.info("*****查询结果:{}", payment);if (payment != null) {return new CommonResult(200, "查询成功, 服务端口:" + serverPort, payment);} else {return new CommonResult(444, "没有对应记录,查询ID: " + id + ",服务端口:" + serverPort, null);}}
}
第五步:然后我们启动注册中心以及两个提供者服务,启动后浏览器我们进行访问
他不仅限于和Eureka注册中心使用,我这里是基于Eureka来进行使用的,需要了解Eureka注册中心的搭建可以看这篇文章:
❝
https://blog.csdn.net/weixin_43888891/article/details/125325794
❞
使用OpenFeign,假如是根据服务名称调用,OpenFeign他本身就集成了ribbon自带负载均衡。
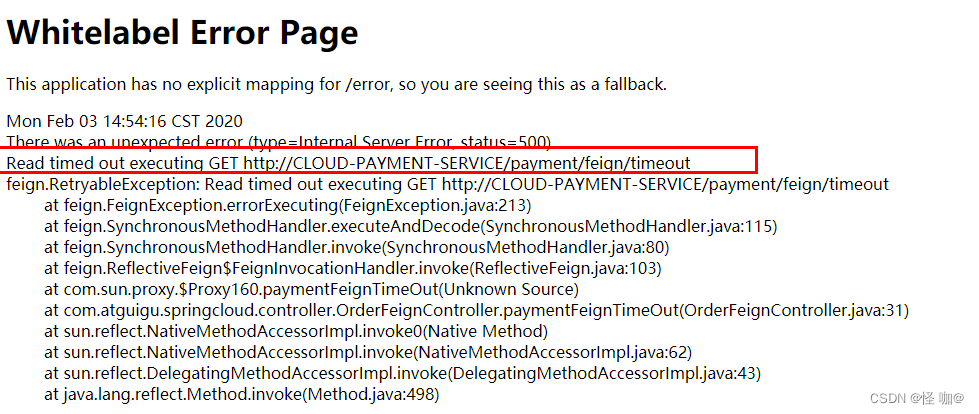
2.3.OpenFeign 超时控制
第一步:提供方接口,制造超时场景
@GetMapping(value = "/payment/feign/timeout")
public String paymentFeignTimeOut() {System.out.println("*****paymentFeignTimeOut from port: " + serverPort);//暂停几秒钟线程try {TimeUnit.SECONDS.sleep(3);} catch (InterruptedException e) {e.printStackTrace();}return serverPort;
}
第二步:消费方接口调用
@Component
@FeignClient(value = "CLOUD-PAYMENT-SERVICE")
public interface PaymentFeignService{@GetMapping(value = "/payment/feign/timeout")String paymentFeignTimeOut();
}
当消费方调用提供方时候,OpenFeign默认等待1秒钟,超过后报错
第三步:在消费者添加如下配置
#设置feign客户端超时时间(OpenFeign默认支持ribbon)
ribbon:#指的是建立连接所用的时间,适用于网络状况正常的情况下,两端连接所用的时间ReadTimeout: 5000#指的是建立连接后从服务器读取到可用资源所用的时间ConnectTimeout: 5000
在openFeign高版本当中,我们可以在默认客户端和命名客户端上配置超时。OpenFeign 使用两个超时参数:
- connectTimeout:防止由于服务器处理时间长而阻塞调用者。
- readTimeout:从连接建立时开始应用,在返回响应时间过长时触发。
2.4.OpenFeign 日志打印
Feign 提供了日志打印功能,我们可以通过配置来调整日志级别,从而了解 Feign 中 Http 请求的细节。
说白了就是对Feign接口的调用情况进行监控和输出
日志级别:
- NONE:默认的,不显示任何日志;
- BASIC:仅记录请求方法、URL、响应状态码及执行时间;
- HEADERS:除了 BASIC 中定义的信息之外,还有请求和响应的头信息;
- FULL:除了 HEADERS 中定义的信息之外,还有请求和响应的正文及元数据。
配置日志Bean:
import feign.Logger;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class FeignConfig {@BeanLogger.Level feignLoggerLevel() {return Logger.Level.FULL;}
}
YML文件里需要开启日志的Feign客户端
logging:level:# feign日志以什么级别监控哪个接口com.gzl.cn.service.PaymentFeignService: debug
后台日志查看:

2.5.OpenFeign 添加Header
以下提供了四种方式:
- 在@RequestMapping中添加,如下:
@FeignClient(name="custorm",fallback=Hysitx.class)
public interface IRemoteCallService {@RequestMapping(value="/custorm/getTest",method = RequestMethod.POST,headers = {"Content-Type=application/json;charset=UTF-8"})List<String> test(@RequestParam("names") String[] names);
}
- 在方法参数前面添加@RequestHeader注解,如下:
@FeignClient(name="custorm",fallback=Hysitx.class)
public interface IRemoteCallService {@RequestMapping(value="/custorm/getTest",method = RequestMethod.POST,headers = {"Content-Type=application/json;charset=UTF-8"})List<String> test(@RequestParam("names")@RequestHeader("Authorization") String[] names);
}
设置多个属性时,可以使用Map,如下:
@FeignClient(name="custorm",fallback=Hysitx.class)
public interface IRemoteCallService {@RequestMapping(value="/custorm/getTest",method = RequestMethod.POST,headers = {"Content-Type=application/json;charset=UTF-8"})List<String> test(@RequestParam("names") String[] names, @RequestHeader MultiValueMap<String, String> headers);
}
- 使用@Header注解,如下:
@FeignClient(name="custorm",fallback=Hysitx.class)
public interface IRemoteCallService {@RequestMapping(value="/custorm/getTest",method = RequestMethod.POST)@Headers({"Content-Type: application/json;charset=UTF-8"})List<String> test(@RequestParam("names") String[] names);
}
- 实现RequestInterceptor接口(拦截器),如下:
❝
只要通过FeignClient访问的接口都会走这个地方,所以使用的时候要注意一下。
❞
@Configuration
public class FeignRequestInterceptor implements RequestInterceptor {@Overridepublic void apply(RequestTemplate temp) {temp.header(HttpHeaders.AUTHORIZATION, "XXXXX");}
}
2.6.手动创建 Feign 客户端
@FeignClient无法支持同一service具有多种不同配置的FeignClient,因此,在必要时需要手动build FeignClient。
@FeignClient(value = “CLOUD-PAYMENT-SERVICE”)
以这个为例,假如出现两个服务名称为CLOUD-PAYMENT-SERVICE的FeignClient,项目直接会启动报错,但是有时候我们服务之间调用的地方较多,不可能将所有调用都放到一个FeignClient下,这时候就需要自定义来解决这个问题!
官网当中也明确提供了自定义FeignClient,以下是在官网基础上对自定义FeignClient的一个简单封装,供参考!
首先创建FeignClientConfigurer类,这个类相当于build FeignClient的工具类
import feign.*;
import feign.codec.Decoder;
import feign.codec.Encoder;
import feign.slf4j.Slf4jLogger;
import org.springframework.cloud.openfeign.FeignClientsConfiguration;
import org.springframework.context.annotation.Import;@Import(FeignClientsConfiguration.class)
public class FeignClientConfigurer {private Decoder decoder;private Encoder encoder;private Client client;private Contract contract;public FeignClientConfigurer(Decoder decoder, Encoder encoder, Client client, Contract contract) {this.decoder = decoder;this.encoder = encoder;this.client = client;this.contract = contract;}public RequestInterceptor getUserFeignClientInterceptor() {return new RequestInterceptor() {@Overridepublic void apply(RequestTemplate requestTemplate) {// 添加header}};}public <T> T buildAuthorizedUserFeignClient(Class<T> clazz, String serviceName) {return getBasicBuilder().requestInterceptor(getUserFeignClientInterceptor())//默认是Logger.NoOpLogger.logger(new Slf4jLogger(clazz))//默认是Logger.Level.NONE(一旦手动创建FeignClient,全局配置的logger就不管用了,需要在这指定).logLevel(Logger.Level.FULL).target(clazz, buildServiceUrl(serviceName));}private String buildServiceUrl(String serviceName) {return "http://" + serviceName;}protected Feign.Builder getBasicBuilder() {return Feign.builder().client(client).encoder(encoder).decoder(decoder).contract(contract);}
}
使用工具类的方法创建多个FeignClient配置
import com.gzl.cn.service.FeignTest1Service;
import feign.Client;
import feign.Contract;
import feign.codec.Decoder;
import feign.codec.Encoder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class FeignClientConfiguration extends FeignClientConfigurer {public FeignClientConfiguration(Decoder decoder, Encoder encoder, Client client, Contract contract) {super(decoder, encoder, client, contract);}@Beanpublic FeignTest1Service feignTest1Service() {return super.buildAuthorizedUserFeignClient(FeignTest1Service.class, "CLOUD-PAYMENT-SERVICE");}// 假如多个FeignClient在这里定义即可
}
其中,super.buildAuthorizedUserFeignClient()方法中,第一个参数为调用别的服务的接口类,第二个参数为被调用服务在注册中心的service-id。
public interface FeignTest1Service {@GetMapping(value = "/payment/get/{id}")CommonResult<Payment> getPaymentById(@PathVariable("id") Long id);
}
使用的时候正常注入使用即可
@Resource
private FeignTest1Service feignTest1Service;
2.7.Feign 继承支持
Feign 通过单继承接口支持样板 API。这允许将常用操作分组到方便的基本接口中。
UserService.java
public interface UserService {@RequestMapping(method = RequestMethod.GET, value ="/users/{id}")User getUser(@PathVariable("id") long id);
}
UserResource.java
@RestController
public class UserResource implements UserService {
}
UserClient.java
package project.user;@FeignClient("users")
public interface UserClient extends UserService {}
2.8.Feign 和Cache集成
如果@EnableCaching使用注解,CachingCapability则创建并注册一个 bean,以便您的 Feign 客户端识别@Cache*其接口上的注解:
public interface DemoClient {@GetMapping("/demo/{filterParam}")@Cacheable(cacheNames = "demo-cache", key = "#keyParam")String demoEndpoint(String keyParam, @PathVariable String filterParam);
}
您还可以通过 property 禁用该功能feign.cache.enabled=false
❝
注意feign.cache.enabled=false只有在高版本才有
❞
2.9.OAuth2 支持
可以通过设置以下标志来启用 OAuth2 支持:
feign.oauth2.enabled=true
当标志设置为 true 并且存在 oauth2 客户端上下文资源详细信息时,将OAuth2FeignRequestInterceptor创建一个类 bean。在每个请求之前,拦截器解析所需的访问令牌并将其作为标头包含在内。有时,当为 Feign 客户端启用负载平衡时,您可能也希望使用负载平衡来获取访问令牌。
为此,您应该确保负载均衡器位于类路径 (spring-cloud-starter-loadbalancer) 上,并通过设置以下标志显式启用 OAuth2FeignRequestInterceptor 的负载均衡:
feign.oauth2.load-balanced=true
ring keyParam, @PathVariable String filterParam);
}
您还可以通过 property 禁用该功能feign.cache.enabled=false> ❝
>
> 注意feign.cache.enabled=false只有在高版本才有
>
> ❞#### 2.9.OAuth2 支持可以通过设置以下标志来启用 OAuth2 支持:feign.oauth2.enabled=true
当标志设置为 true 并且存在 oauth2 客户端上下文资源详细信息时,将OAuth2FeignRequestInterceptor创建一个类 bean。在每个请求之前,拦截器解析所需的访问令牌并将其作为标头包含在内。有时,当为 Feign 客户端启用负载平衡时,您可能也希望使用负载平衡来获取访问令牌。为此,您应该确保负载均衡器位于类路径 (spring-cloud-starter-loadbalancer) 上,并通过设置以下标志显式启用 OAuth2FeignRequestInterceptor 的负载均衡:feign.oauth2.load-balanced=true
注意feign.cache.enabled=false只有在高版本才有