网站便宜建设现在如何进行网上推广
电子价签应用简介
在全球零售业受到电商冲击、劳动力成本和周转率上升、消费者需求改变的行业背景下,电子价签、AI货架监控系统、自助结账设备、相关的方案将零售行业的发展带上智能化数字化的发展道路上。为企业与客户带来的更高效更便捷的消费体验。
蓝牙电子价签的角色
蓝牙电子价签应用本质上是一个无线通信网络,包含两个角色,一个是作为管理者和信息控制中心的访问点(Access Point, 简称AP),另一个是作为被管理的信息显示终端,即电子价签。每个电子价签网络由一个位于中心的访问点设备和数千个电子价签组成,访问点设备可以是电脑或智能手机。
电子价签网络中的访问点设备负责发起与电子价签的连接、发现电子价签的能力并配置电子价签上显示的信息。
电子价签作为GATT服务端设备支持电子价签服务,作为GATT客户端的访问点设备通过电子价签服务中包含的特征实现对电子价签的管理和信息更新。
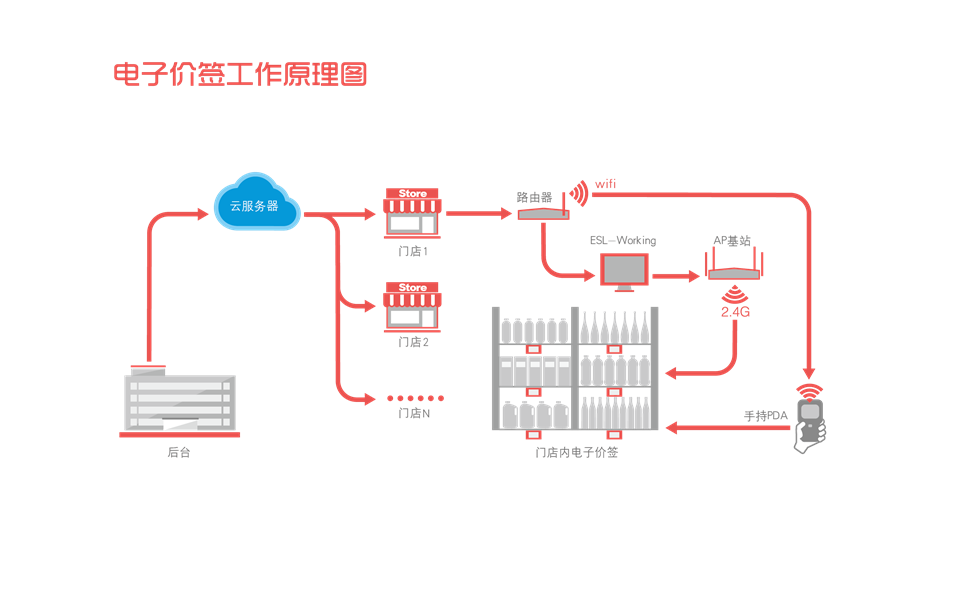
那么小编今天要带大家了解的是我们国产蓝牙芯片OM6626在这个领域起到的重要作用.
OM6626 是一款超低功耗的蓝牙soc
主要特性:
- 支持BLE5.3
- 支持SIG Mesh
- 支持2.4G长包
- 主频64Mhz,80KB RAM
- 主要应用在esl电子价签,IoT模组、CGM、高报告率HID设备
PUM特点
- 1.71~3.6v供电电压
- 1秒间隔广播平均电流:9uA;1秒间隔连接平均电流:7uA
- 峰值电流:TX@0dB:4mA,RX@1Mbps:3mA
BLE特点
- 支持SIG Mesh
- 支持主从一体
2.4G传输特点
- 灵活可配的包格式,可以与多个厂商实现互联互通
- 支持低速率,传输速率可以从25Kbps to 2Mpbs
- 65535字节的Payload
射频性能特点
- 发射功耗: max 10dBm
- 接受灵敏度@1Mbps:-99dBm(整数频点与非整数频点≤±3dBm)
- 射频转换时间:30~40us(可实现4K报告率)
SDK代码
- 射频底层代码开放,可灵活配置(除了蓝牙协议栈)
- 协议栈代码优化,RAM占用29KB,flash占用149KB

目前电子价签ESL的主流解决方案如下
1.价格管控:电子价签保障实体店、网上商城以及APP端的商品价格等信息保持实时高度同步,解决线上频繁促销线下无法同步进行以及部分商品短时间内频繁变价的难题。
2.高效陈列:电子价签与店内陈列管理系统集成,将店内陈列位置有效固化,指导店员进行商品陈列的同时也给总部进行陈列核检提供便利,且全程无纸化操作,高效、准确、绿色。
3.门店配送拣货:通过后台系统与硬件结合满足O2O拣货场景,结合陈列布局图为门店人员提供可视化最优拣货路线,优化门店拣货流程,高效提升拣货效率。
4.智慧生鲜:电子价签解决门店重点生鲜部分变价频繁的难题,并能显示库存信息,完成单品高效盘点、门店出清流程优化,出清数据监测监控等。
5.精准营销:完成对用户进行多维度行为数据收集,剖析数据为用户贴上标签,完善用户画像模型,便于后期针对消费者的偏好,通过多渠道精准推送相应的营销广告或服务信息。
新品预告
OM6628在OM6626上做了升级支持USB2.0 full Speed
特性:
- 支持BLE 5.4
- 超低功耗蓝牙soc
- M33内核,主频96Mhz,128KB RAM
- 超高精度40Ksps 16-bit ADC
- 44GPIOs ,USB2.0 Full Speed,CAN FD,Audio ACD
- 支持Secure Boot
主要应用在蓝牙语音遥控,高报告率三模键鼠,高集成度CGM等
sill:18025398187 获取:DEMO,SDK,技术支持等