公司宣传册设计样本怎么排版长春网络推广seo
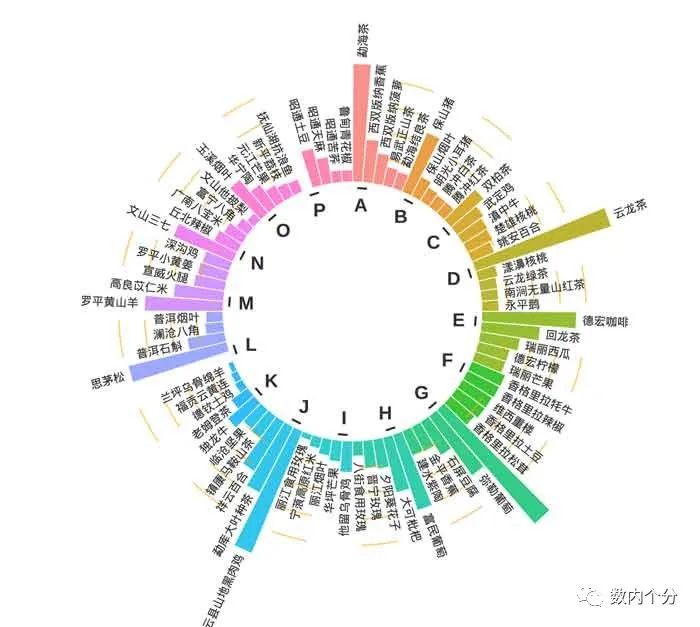
从理念上看,本质就是增加了圆环弧度的条形图。如上图2。
需要以下步骤:
数据处理,将EXCEL中的数据做成3*N的表格导入系统,代码如下:library(tidyverse)
library(stringr)library(ggplot2)library(viridis)stuper <- read.csv("C:/Users/user1/Desktop/20230828/huanbar1.csv")> head(stuper)group individual value id1 A 勐海茶 90.14129 12 A 西双版纳香蕉 32.59547 23 A 西双版纳菠萝 23.19559 34 A 易武正山茶 14.17019 45 A 勐海结良茶 13.01186 56 B 保山猪 48.85315 6
将数据预处理为环形图能够识别的格式,代码如下:
empty_bar <- 3to_add <- data.frame(matrix(NA, empty_bar*nlevels(stuper$group), ncol(stuper)))to_add$group <- rep(levels(stuper$group), each=empty_bar)#为数据表添加分组变量stuper <- rbind(stuper, to_add) # 合并两个数据stuper <- stuper %>% arrange(group) # 将数据根据分组进行排序stuper$id <- seq(1, nrow(stuper))# 获取每个样本的名称在y轴的位置和倾斜角度label_data <- stupernumber_of_bar <- nrow(label_data) # 计算条的数量## 每个条上标签的轴坐标的倾斜角度angle <- 90 - 360 * (label_data$id-0.5) /number_of_barlabel_data$hjust <- ifelse( angle < -90, 1, 0) # 调整标签的对其方式label_data$angle <- ifelse(angle < -90, angle+180, angle) ## 标签倾斜角度## 为数据准备基础弧线的数据base_data <- stuper %>% group_by(group) %>%summarize(start=min(id), end=max(id) - empty_bar) %>%rowwise() %>% mutate(title=mean(c(start, end)))# 为网格标尺准备数据grid_data <- base_datagrid_data$end <- grid_data$end[c(nrow(grid_data), 1:nrow(grid_data)-1)] + 1grid_data$start <- grid_data$start - 1grid_data <- grid_data[-1,]
数据梳理清楚后,就可以直接画图:
p1 <- ggplot(stuper)+## 添加条形图geom_bar(aes(x=as.factor(id), y=value, fill=group),stat="identity",alpha=0.8) +##为条形图添加一些划分等级的线(20/40/60/80)(按比例添加是因为知道满分100)geom_segment(data=grid_data, aes(x = end, y = 80, xend = start, yend = 80),colour = "orange", alpha=0.5, linewidth=0.5 ,inherit.aes = FALSE)+geom_segment(data=grid_data, aes(x = end, y = 60, xend = start, yend = 60),colour = "orange", alpha=0.5, linewidth=0.5 ,inherit.aes = FALSE )+geom_segment(data=grid_data, aes(x = end, y = 40, xend = start, yend = 40),colour = "orange", alpha=0.5, linewidth=0.5 , inherit.aes = FALSE )+geom_segment(data=grid_data, aes(x = end, y = 20, xend = start, yend = 20),colour = "orange", alpha=0.5, linewidth=0.5 , inherit.aes = FALSE )+# 添加文本表示(20/40/60/80)表示每条线的大小annotate("text", x = rep(max(stuper$id),4), y = c(20, 40, 60, 80),label = c("20", "40", "60", "80") , color="black", size=3,angle=0, hjust=1) +ylim(-100,120) + ## 设置y轴坐标表的取值范围,可流出更大的圆心空白## 设置使用的主题并使用极坐标系可视化条形图theme_minimal() +theme(legend.position = "none", # 不要图例axis.text = element_blank(),# 不要x轴的标签axis.title = element_blank(), # 不要坐标系的名称panel.grid = element_blank(), # 不要网格线plot.margin = unit(rep(-1,4), "cm"))+ ## 整个图与周围的边距coord_polar() + ## 极坐标系## 为条形图添加文本geom_text(data=label_data,aes(x=id, y=value+5, label=individual,hjust=hjust),color="black",fontface="bold",alpha=0.8, size=2.5,angle= label_data$angle, inherit.aes = FALSE) +# 为图像添加基础线的信息geom_segment(data=base_data, aes(x = start, y = -5, xend = end, yend = -5),colour = "black", alpha=0.8, size=0.6 , inherit.aes = FALSE )+## 添加分组文本信息geom_text(data=base_data, aes(x = title, y = -18, label=group),alpha=0.8,colour = "black", size=4,fontface="bold", inherit.aes = FALSE)p1
加上汉字的正常显示:
library(showtext)## 使用Windows自带字体font_add("heiti", "simhei.ttf")font_add("constan", "constan.ttf", italic = "constani.ttf"