西安竞价托管公司网站优化排名易下拉用法
前两天有读者想我资讯:
我是一名软件测试工程师,工作已经四年多快五年了。现在正在找工作,由于一直做的都是外包的项目。技术方面都不是很深入,现在找工作都是会问一些,测试框架,自动化测试,感觉不懂的东西太多了,现在很迷茫,但是我知道至少不能再找这种外包形式的了!下一份工作应该找一个怎么样的?有同事建议我去一个互联网公司学习学习!但是互联网公司的要求确实高一些,不知道你怎么看?
这张图可以回答“下一份工作应该找一个怎么样的”这个问题。
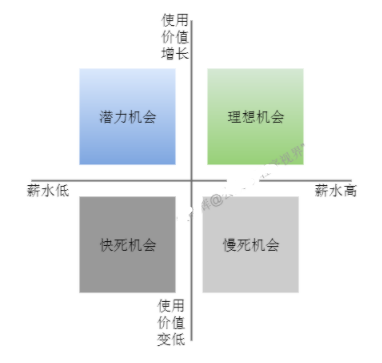
有一个软件测试技术从业者必须意识到的现实:
如果在某个技术栈上没有深入积累,技术能力一直停留在“别人安排事情、分解好任务、不动脑地执行”的程度,那你的使用价值会随着年龄增长而降低,再找工作就很难找到好的机会。
所以我们在找工作的时候,一定要关注“个人能力的成长性”,也就是要以前面那张图中的潜力机会和理想机会为目标,不要轻易进入只会消耗你价值的平台,即便它给的薪水比较高(慢死机会)——因为你会失去未来。
放在你的身上,在找工作时,一定要考虑清楚几件事情:
我想在哪个技术栈上持续积累
我想做什么产品(业务)
我可以接受的最低薪水是多少
明确了产品方向和技术方向之后,只要某个机会可以让你提升技术变得越来越有价值,只要某个机会符合你对产品(业务)的偏好(或者不相悖),你就可以去尝试,因为你的使用价值会因为这份工作而增长,哪怕当下薪水低一些(潜力机会),将来也有资本加薪或找到薪水更高的机会。
理想的工作变更,是在潜力机会和理想机会之间来回切换,螺旋上升。所以,请多多思考,什么样的事情、什么样的机会,能让你成长,能让你越来越值钱。然后,以此为原则来选择工作。
绵薄之力
我也是个爱学习的人,我觉得学习是测试员工作中长久不变的主题。为了助力大家跳槽面试、升职加薪、职业困境,提高自己的技术,我给大家整理了一份全栈软件测试学习路线图,希望能帮助到大家。
这可能是2023年最全的软件测试工程师发展方向知识架构体系图。
一、测试基础
了解测试的基础技能,掌握主流缺陷管理工具的使用,熟练测试环境的操作与运维

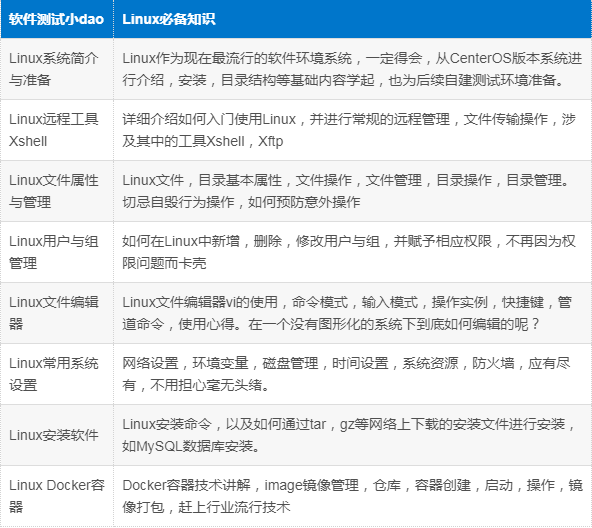
二、Linux必备知识
Linux作为现在最流行的软件环境系统,一定需要掌握,目前的招聘要求都需要有Linux能力。
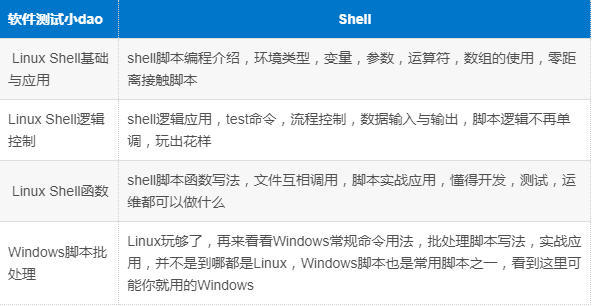
三、Shell脚本
掌握Shell脚本:包括Shell基础与运用、Shell逻辑控制、Shell逻辑函数
四、互联网程序原理
自动化必经之路:前端开发基础知识以及互联网网络必备知识四、互联网程序原理

五、MySQL数据库
软件测试工程师必备MySQL数据库知识,不仅仅停留在基本的“增删改查”。

六、抓包工具
Fiddler,Wireshark,Sniffer,Tcpdump各种抓包工具适用于各种项目,总有一款适合你的

七、接口测试工具
接口测试神器,你绕不开的强大工具:Jmeter。小巧灵活:Postman

八、Web自动化测试Java&Python
了解自动化的目的,熟练掌握TestNG&unittest自动化框架,以及断言与日志处理

九、接口与移动端自动化
专业接口调用、测试解决方案。组建完整的web和接口自动化框架,Appium整体使用

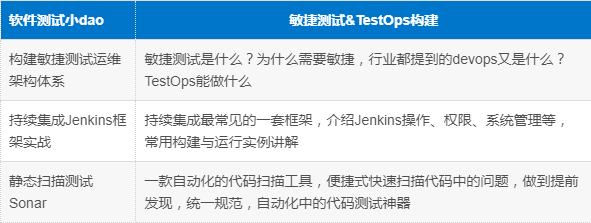
十、敏捷测试&TestOps构建
揭开TestOps的神秘面纱,持续集成Jenkins框架烂熟于心
十一、性能测试&安全测试
软件测试的彼岸:性能测试和安全测试,选个方向努力爬坑吧!

希望大家能照着这个体系在1-2年内完成这样一个体系的构建。
可以说,这个过程会让你痛不欲生,但只要你熬过去了。以后的生活就轻松很多。正所谓万事开头难,只要迈出了第一步,你就已经成功了一半,等到完成之后再回顾这一段路程的时候,你肯定会感慨良多。
作为一位过来人也是希望大家少走一些弯路,如果你不想再体验一次学习时找不到资料,没人解答问题,坚持几天便放弃的感受的话,在这里我给大家分享一些自动化测试的学习资源,希望能给你前进的路上带来帮助。【保证100%免费】

视频文档获取方式:
这份文档和视频资料,对于想从事【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!以上均可以分享,点下方小卡片即可自行领取。