福州做网站外包成都网络营销
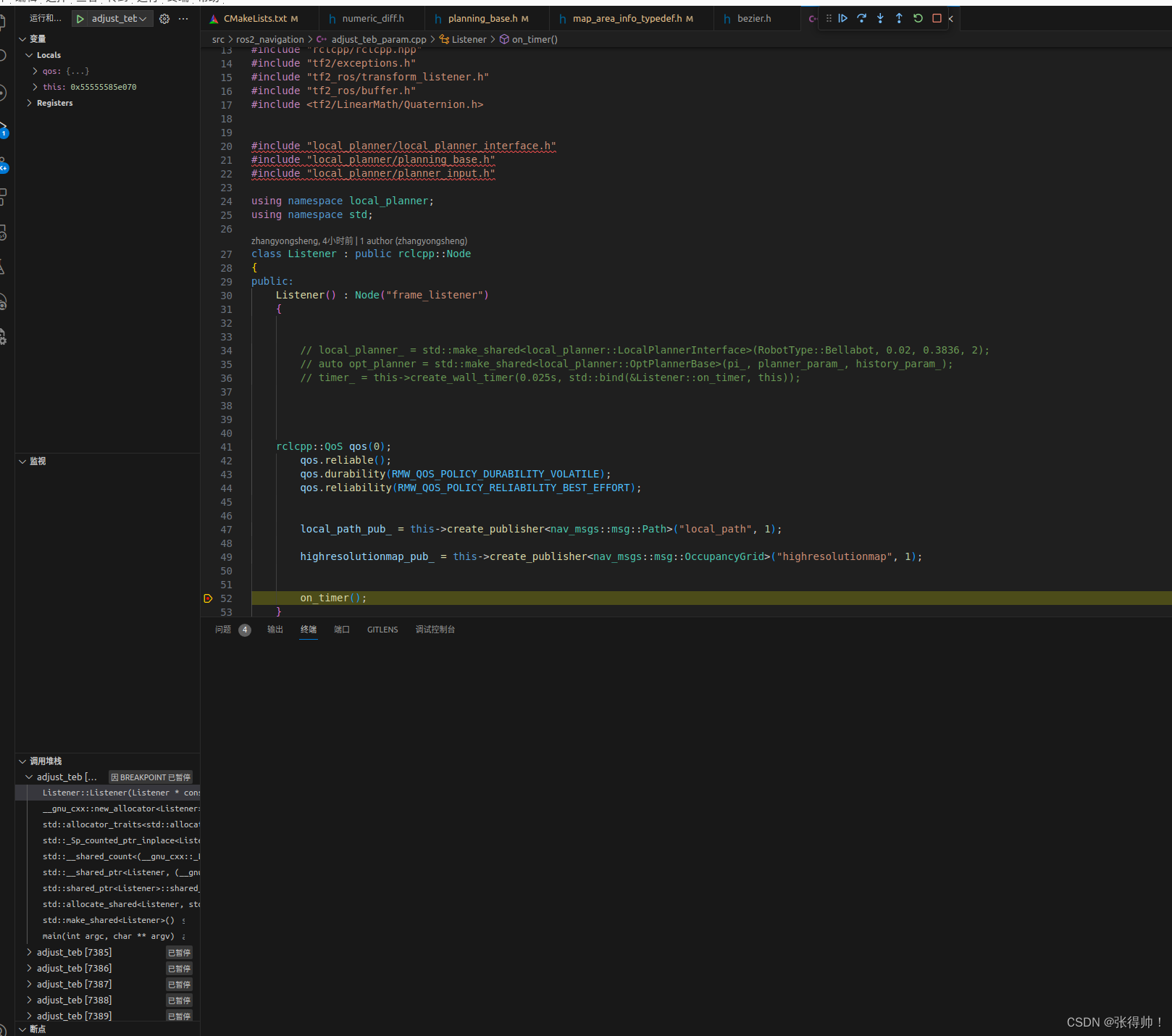
1、在下列目录同层级找到.vscode文件夹
.
├── build
├── install
├── log
└── src
2、 安装ros插件

3、创建tasks.json文件,添加下列内容
//代替命令行进行编译
{"version": "2.0.0","tasks": [{"label": "catkin_make", //代表提示的描述性信息"type": "shell", //可以选择shell或者process,如果是shell代码是在shell里面运行一个命令,如果是process代表作为一个进程来运行// "command": "catkin_make",//这个是我们需要运行的命令"command": "colcon build --cmake-args -DCMAKE_BUILD_TYPE=Debug", //这个是我们需要运行的命令// "command": "catkin_make -DCMAKE_TYPE=Release",//这个是我们需要运行的命令"args": [], //如果需要在命令后面加一些后缀,可以写在这里,比如-DCATKIN_WHITELIST_PACKAGES=“pac1;pac2”"group": {"kind": "build","isDefault": true},"presentation": {"reveal": "always" //可选always或者silence,代表是否输出信息},"problemMatcher": "$msCompile"}]
}4、创建launch.json文件,添加下列内容,主要把program对应的文件改成自己的
//debug
{"version": "0.2.0","configurations": [{"name": "adjust_teb","type": "cppdbg","request": "launch",//改成自己的要编译的文件// "program": "${workspaceFolder}/install/ros2_navigation/lib/ros2_navigation/ros_navigation","program": "${workspaceFolder}/build/ros2_navigation/adjust_teb","args": [],"stopAtEntry": false,"cwd": "${fileDirname}","environment": [],"externalConsole": false,"MIMode": "gdb","setupCommands": [{"description": "为 gdb 启用整齐打印","text": "-enable-pretty-printing","ignoreFailures": true},{"description": "将反汇编风格设置为 Intel","text": "-gdb-set disassembly-flavor intel","ignoreFailures": true}]}]
}5、CMakeList.txt 增加debug编译模式
set(CMAKE_BUILD_TYPE debug)#debug模式,程序不会被优化,速度非常慢6、编译 ctrl+shift+B 编译
7、在这个界面,选择自己的launch.json 文件中的调试文件名,然后点击运行即可

8、即可停在自己打断点的位置