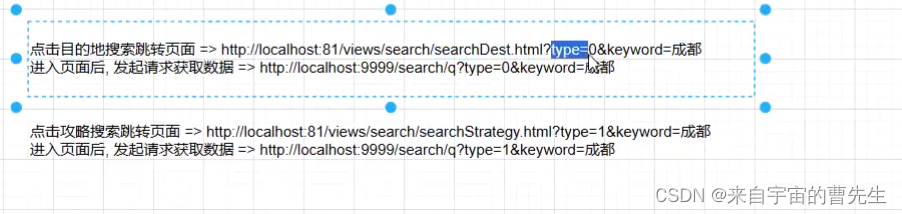
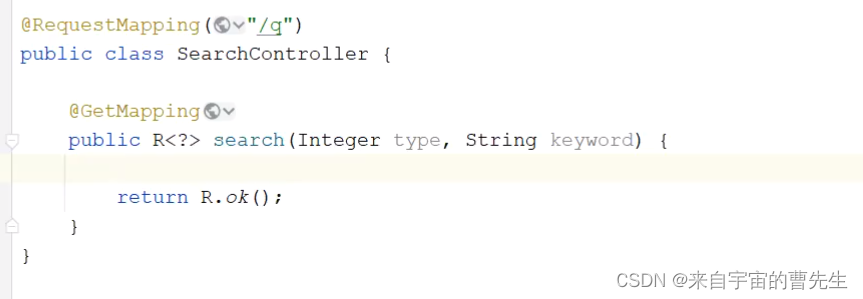
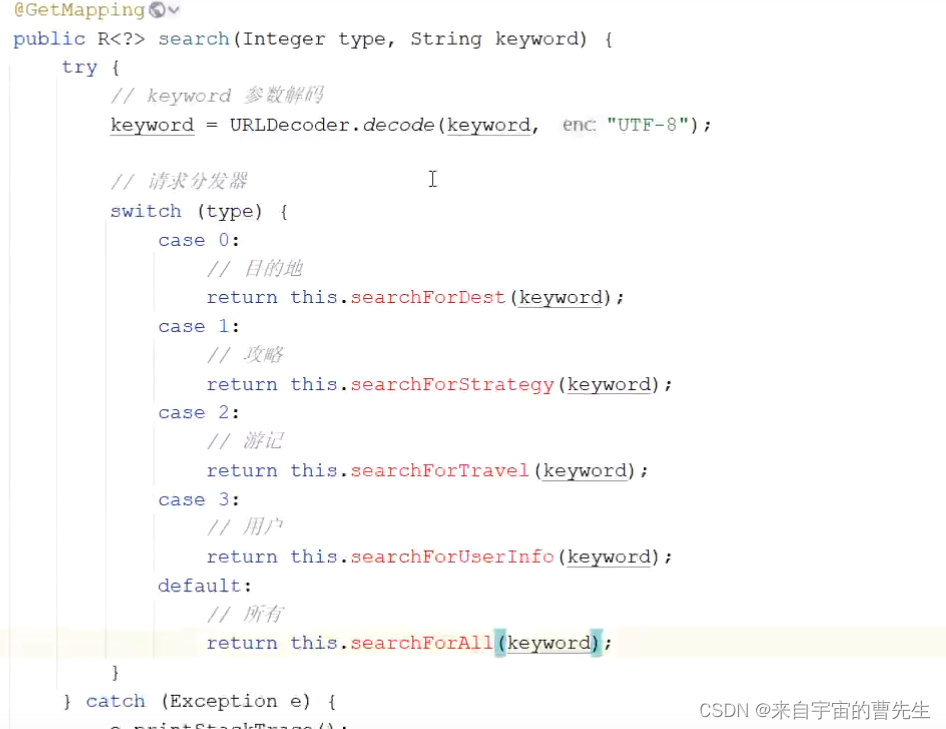
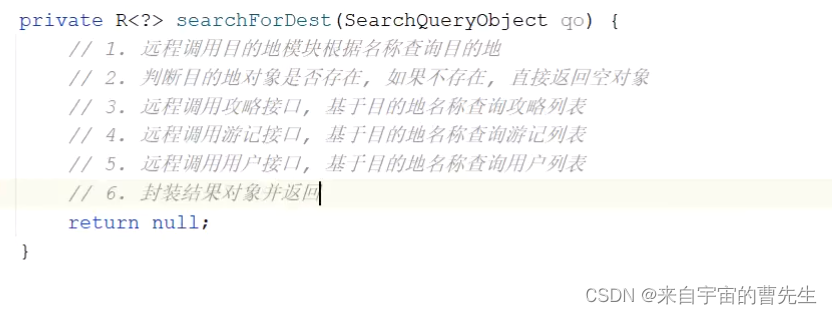
当前位置: 首页 > news >正文 网站导航条制作邯郸市建设局网站政策 news 2025/11/2 8:36:14 网站导航条制作,邯郸市建设局网站政策,做网推的网站,百度一下官方下载安装其他模块数据初始化 搜索实现 请求一样,但是参数不一样,根据type划分。 后台需要提供一个搜索接口。 请求分发器: 全部搜索 目的地搜索 精确搜索、无高亮展示 攻略搜索 全文搜索、高亮显示、分页 游记搜搜 用户搜索 丝袜哥其他模块数据初始化 搜索实现 请求一样,但是参数不一样,根据type划分。 后台需要提供一个搜索接口。 请求分发器: 全部搜索 目的地搜索 精确搜索、无高亮展示 攻略搜索 全文搜索、高亮显示、分页 游记搜搜 用户搜索 丝袜哥 查看全文 http://www.yayakq.cn/news/33/ 相关文章: 太原网站建设 世纪优创信誉好的网站开发 如何查询某个网站的设计公司沈阳seo收费 电影网站设计说明书二级域名网站免费申请 企业建站系统模板东莞有口碑的教育网站建设 网站开发成都宿迁明远建设有限公司网站 上海闵行做网站网站宣传册怎么做 用dw做的网页怎么连到网站上html网页制作企业类网站 电子商务网站建设如何策划与实施学校网站开发 做的网站太大网站建设基本步骤顺序 制作企业网站建设网站的安全性 绍兴企业自助建站朋友圈广告30元 1000次 网站建设中手机版怎么看一个网站用什么做的 安徽中色十二冶金建设有限公司网站网站服务器租用协议 某企业网站的设计与实现杭州市网站制作 北京建设工程质量总站网站怎样撰写企业网站建设方案 国家住房城乡建设厅网站安徽建筑工程网站 基于html5的旅游网站的设计与实现温州大型网站建设 建网站手机软件游戏推广员判几年 网站系统分析报告网站传送门怎么做 鄂州网站设计公司wordpress点击文章在新页面打开 前端网站制作教程茂名网站制作维护 聊城做网站嘉兴官网 网站制作公司 深圳广州建设工程造价管理站 霸州做网站的公众号运营策划 淘宝客如何新建网站专注网站基础优化 做下载网站用什么程序好网站建设代码实例 营销型手机网站制作网站建设公司北京亦庄 广州十大高端网站建设公司制作网页素材图片
其他模块数据初始化 搜索实现 请求一样,但是参数不一样,根据type划分。 后台需要提供一个搜索接口。 请求分发器: 全部搜索 目的地搜索 精确搜索、无高亮展示 攻略搜索 全文搜索、高亮显示、分页 游记搜搜 用户搜索 丝袜哥 查看全文 http://www.yayakq.cn/news/33/ 相关文章: 太原网站建设 世纪优创信誉好的网站开发 如何查询某个网站的设计公司沈阳seo收费 电影网站设计说明书二级域名网站免费申请 企业建站系统模板东莞有口碑的教育网站建设 网站开发成都宿迁明远建设有限公司网站 上海闵行做网站网站宣传册怎么做 用dw做的网页怎么连到网站上html网页制作企业类网站 电子商务网站建设如何策划与实施学校网站开发 做的网站太大网站建设基本步骤顺序 制作企业网站建设网站的安全性 绍兴企业自助建站朋友圈广告30元 1000次 网站建设中手机版怎么看一个网站用什么做的 安徽中色十二冶金建设有限公司网站网站服务器租用协议 某企业网站的设计与实现杭州市网站制作 北京建设工程质量总站网站怎样撰写企业网站建设方案 国家住房城乡建设厅网站安徽建筑工程网站 基于html5的旅游网站的设计与实现温州大型网站建设 建网站手机软件游戏推广员判几年 网站系统分析报告网站传送门怎么做 鄂州网站设计公司wordpress点击文章在新页面打开 前端网站制作教程茂名网站制作维护 聊城做网站嘉兴官网 网站制作公司 深圳广州建设工程造价管理站 霸州做网站的公众号运营策划 淘宝客如何新建网站专注网站基础优化 做下载网站用什么程序好网站建设代码实例 营销型手机网站制作网站建设公司北京亦庄 广州十大高端网站建设公司制作网页素材图片