网站app的意义嘉兴seo网站建设
若依Linux集群部署
- 1. 若依
- 2.MYSQL Linux环境安装
- 2.1 MYSQL数据库部署和安装
- 2.2 解压MYSQL安装包
- 2.3 创建MYSQL⽤户和⽤户组
- 2.4 修改MYSQL⽬录的归属⽤户
- 2.5 准备MYSQL的配置⽂件
- 2.6 正式开始安装MYSQL
- 2.7 复制启动脚本到资源⽬录
- 2.8 设置MYSQL系统服务并开启⾃启
- 2.9 启动MYSQLD
- 2.10 将 MYSQL 的 BIN ⽬录加⼊ PATH 环境变量
- 2.11 ⾸次登陆MYSQL
- 2.12 设置远程主机登录
- 2.2 Redis部署
- 2.2.1 查看REDIS服务启动情况
- 2.2.2 设置允许远程连接
- 2.2.2 设置访问密码
- 3. 代码部分
- 3.1 本地调通
- 4. Linux小集群部署
- 4.1 前段代码(华为云)
- 4.2 后端代码(天翼云、腾讯云)
- n.Docker部署(todo)
- 3.1 Docker安装Mysql
- 3.2 录制快照
- 附录
1. 若依
- 若依前后端分离项目地址:https://gitee.com/y_project/RuoYi-Vue
- 若依Linux集群部署课程
- 若依官网
2.MYSQL Linux环境安装
2.1 MYSQL数据库部署和安装
这⾥下载的是 mysql-5.7.30-linux-glibc2.12-x86_64.tar.gz 安装包,并将其直接放在了 root⽬录下
卸载系统⾃带的MARIADB(如果有)
如果系统之前⾃带 Mariadb ,可以先卸载之。
⾸先查询已安装的 Mariadb 安装包:
rpm -qa|grep mariadb
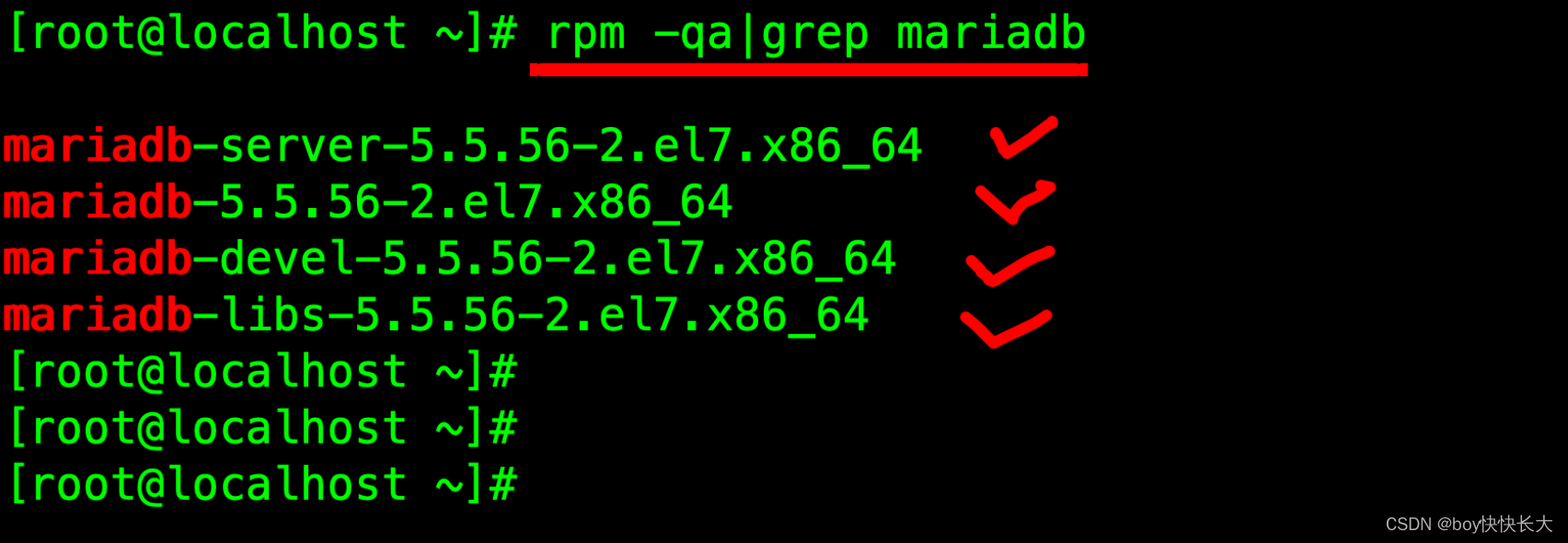
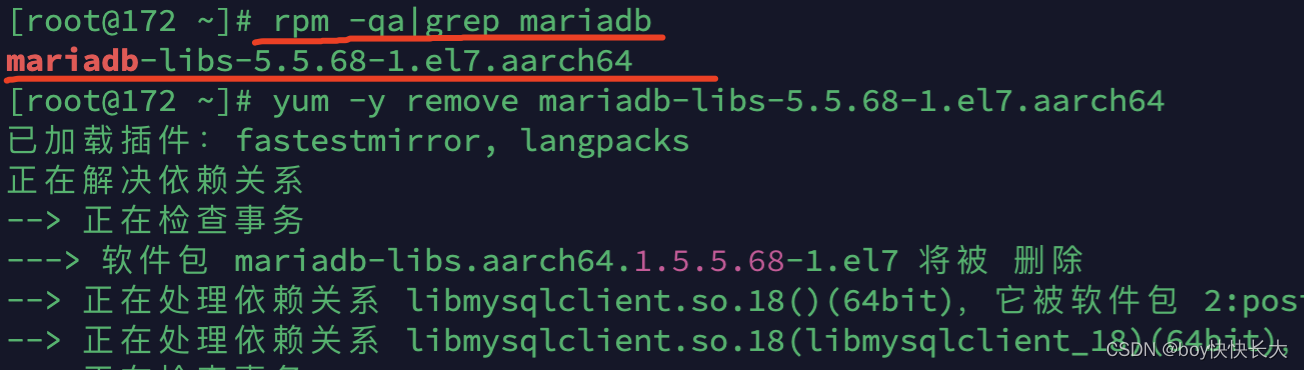
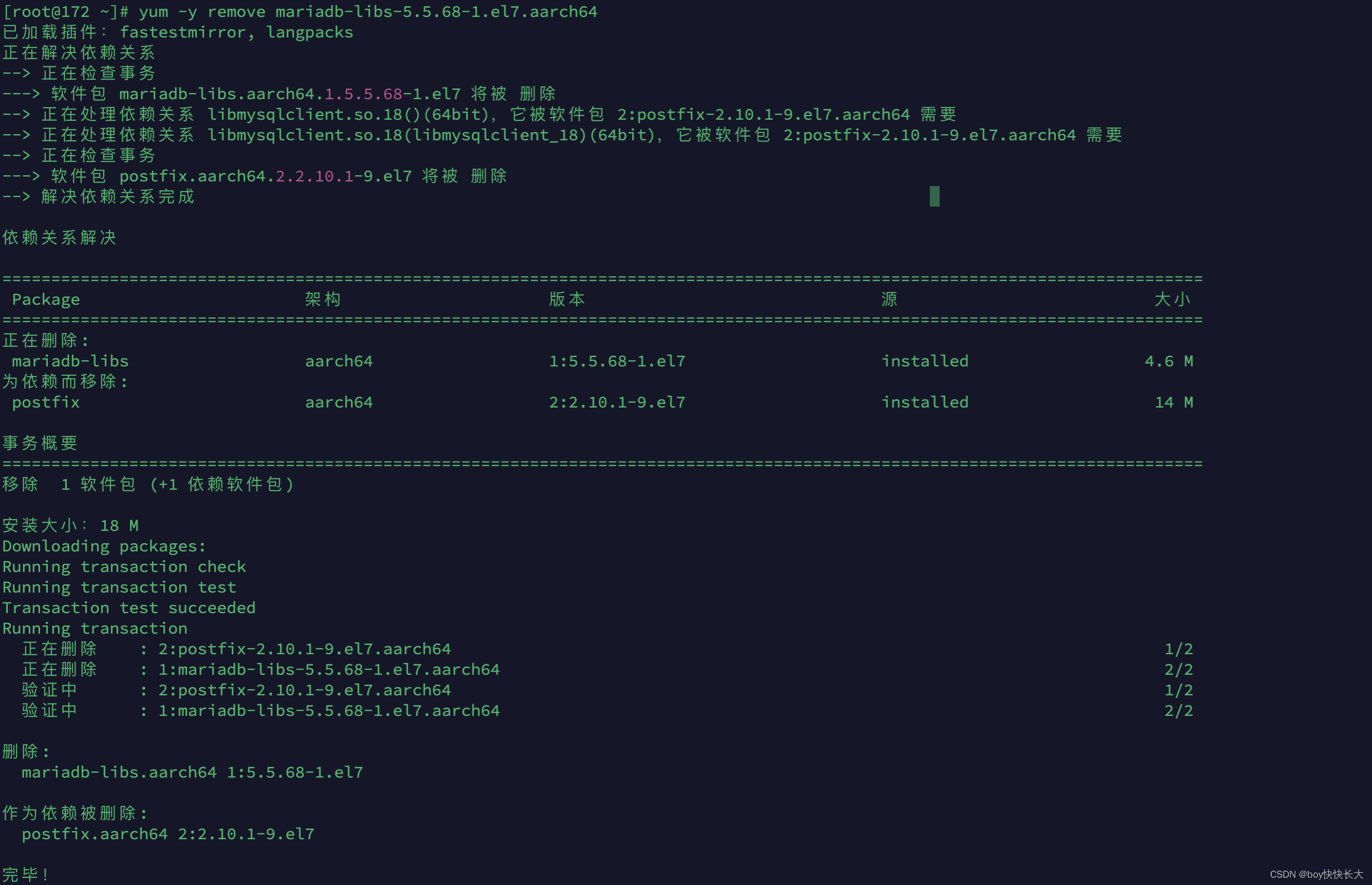
将其均卸载之:
yum -y remove mariadb-server-5.5.56-2.el7.x86_64
yum -y remove mariadb-5.5.56-2.el7.x86_64
yum -y remove mariadb-devel-5.5.56-2.el7.x86_64
yum -y remove mariadb-libs-5.5.56-2.el7.x86_64
这里我使用的是mac系统安装的虚拟机,所以命令有所不一样
2.2 解压MYSQL安装包
将上⾯准备好的 MySQL 安装包解压到 /usr/local/ ⽬录,并重命名为 mysql
tar -zxvf /root/mysql-5.7.30-linux-glibc2.12-x86_64.tar.gz -C /usr/local/ mv mysql-5.7.30-linux-glibc2.12-x86_64 mysql
2.3 创建MYSQL⽤户和⽤户组
groupadd mysql
useradd -g mysql mysql
同时新建 /usr/local/mysql/data ⽬录,后续备⽤
2.4 修改MYSQL⽬录的归属⽤户
[root@localhost mysql]# chown -R mysql:mysql ./
2.5 准备MYSQL的配置⽂件
在 /etc ⽬录下新建 my.cnf ⽂件
写⼊如下简化配置:
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
socket=/var/lib/mysql/mysql.sock
[mysqld]
skip-name-resolve
#设置3306端⼝
port = 3306
socket=/var/lib/mysql/mysql.sock
# 设置mysql的安装⽬录
basedir=/usr/local/mysql
# 设置mysql数据库的数据的存放⽬录
datadir=/usr/local/mysql/data
# 允许最⼤连接数
max_connections=200
# 服务端使⽤的字符集默认为8⽐特编码的latin1字符集
character-set-server=utf8
# 创建新表时将使⽤的默认存储引擎
default-storage-engine=INNODB
lower_case_table_names=1
max_allowed_packet=16M
同时使⽤如下命令创建 /var/lib/mysql ⽬录,并修改权限:
mkdir /var/lib/mysql
chmod 777 /var/lib/mysql
2.6 正式开始安装MYSQL
执⾏如下命令正式开始安装:
cd /usr/local/mysql
./bin/mysqld --initialize --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data
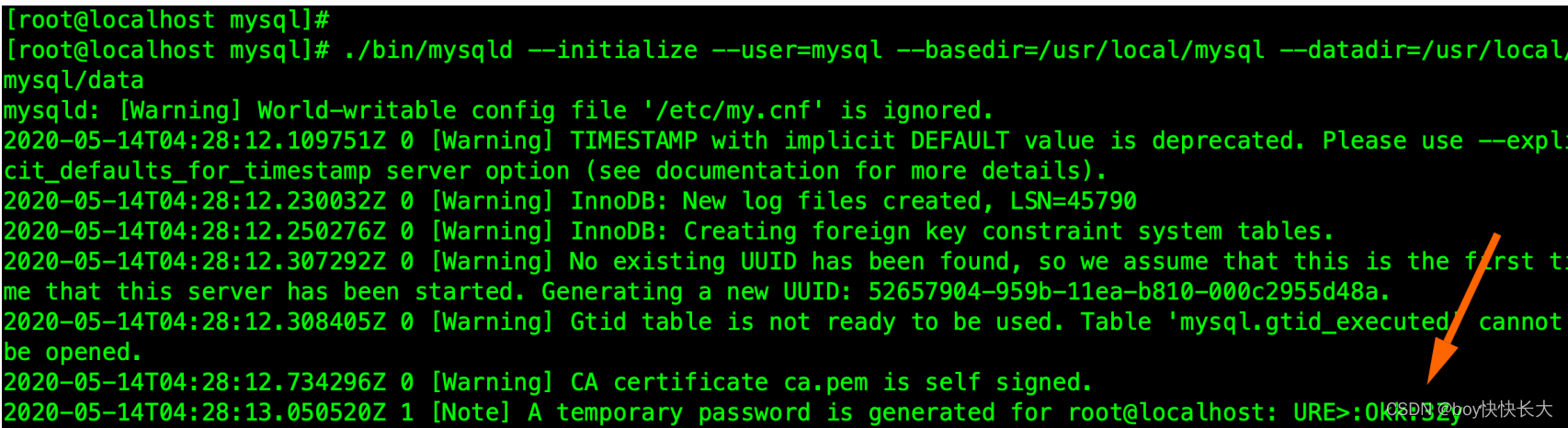
注意:记住上⾯打印出来的 root 的密码,后⾯⾸次登陆需要使⽤
这里因为我需要aarch结构的文件才能执行,M系列芯片不能运行x86-64得Mysql bin所以后续我将用Docker来实现

2.7 复制启动脚本到资源⽬录
执⾏如下命令复制:
[root@localhost mysql]# cp ./support-files/mysql.server
/etc/init.d/mysqld
并修改 /etc/init.d/mysqld ,修改其 basedir 和 datadir 为实际对应⽬录:
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data
2.8 设置MYSQL系统服务并开启⾃启
⾸先增加 mysqld 服务控制脚本执⾏权限:
chmod +x /etc/init.d/mysqld
同时将 mysqld 服务加⼊到系统服务:
chkconfig --add mysqld
最后检查 mysqld 服务是否已经⽣效即可:
chkconfig --list mysqld
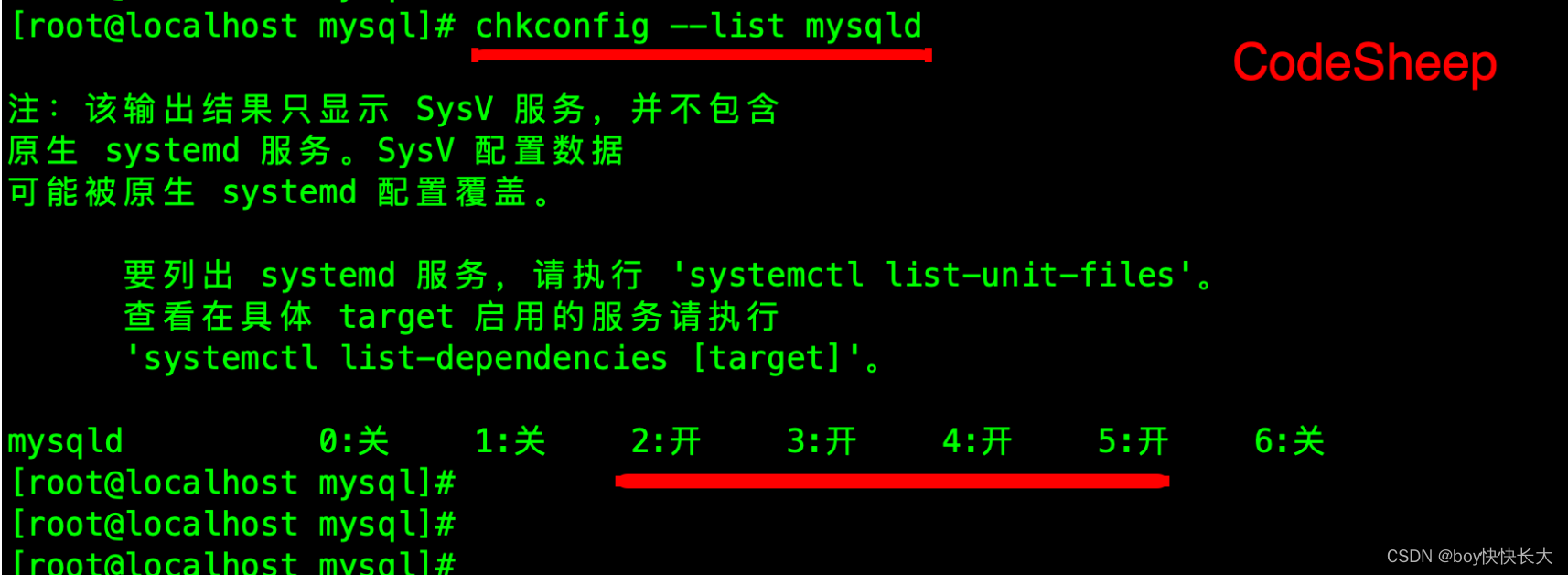
这样就表明 mysqld 服务已经⽣效了,在2、3、4、5运⾏级别随系统启动⽽⾃动启动,以后可以直接使⽤ service 命令控制 mysql 的启停。
2.9 启动MYSQLD
直接执⾏:
service mysqld start
2.10 将 MYSQL 的 BIN ⽬录加⼊ PATH 环境变量
这样⽅便以后在任意⽬录上都可以使⽤ mysql 提供的命令。
编辑 ~/.bash_profile ⽂件,在⽂件末尾处追加如下信息:
export PATH=$PATH:/usr/local/mysql/bin
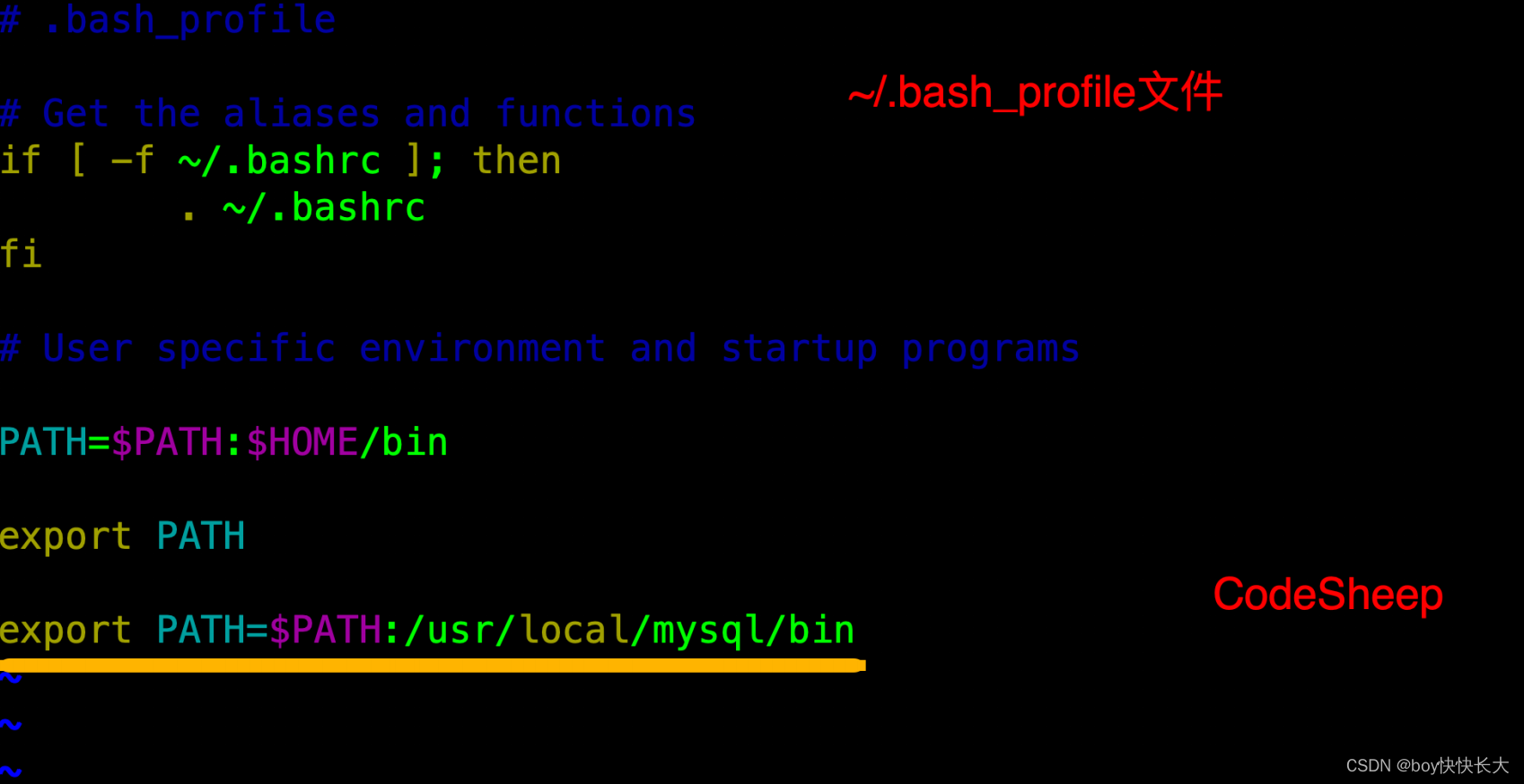
最后执⾏如下命令使环境变量⽣效
source ~/.bash_profile
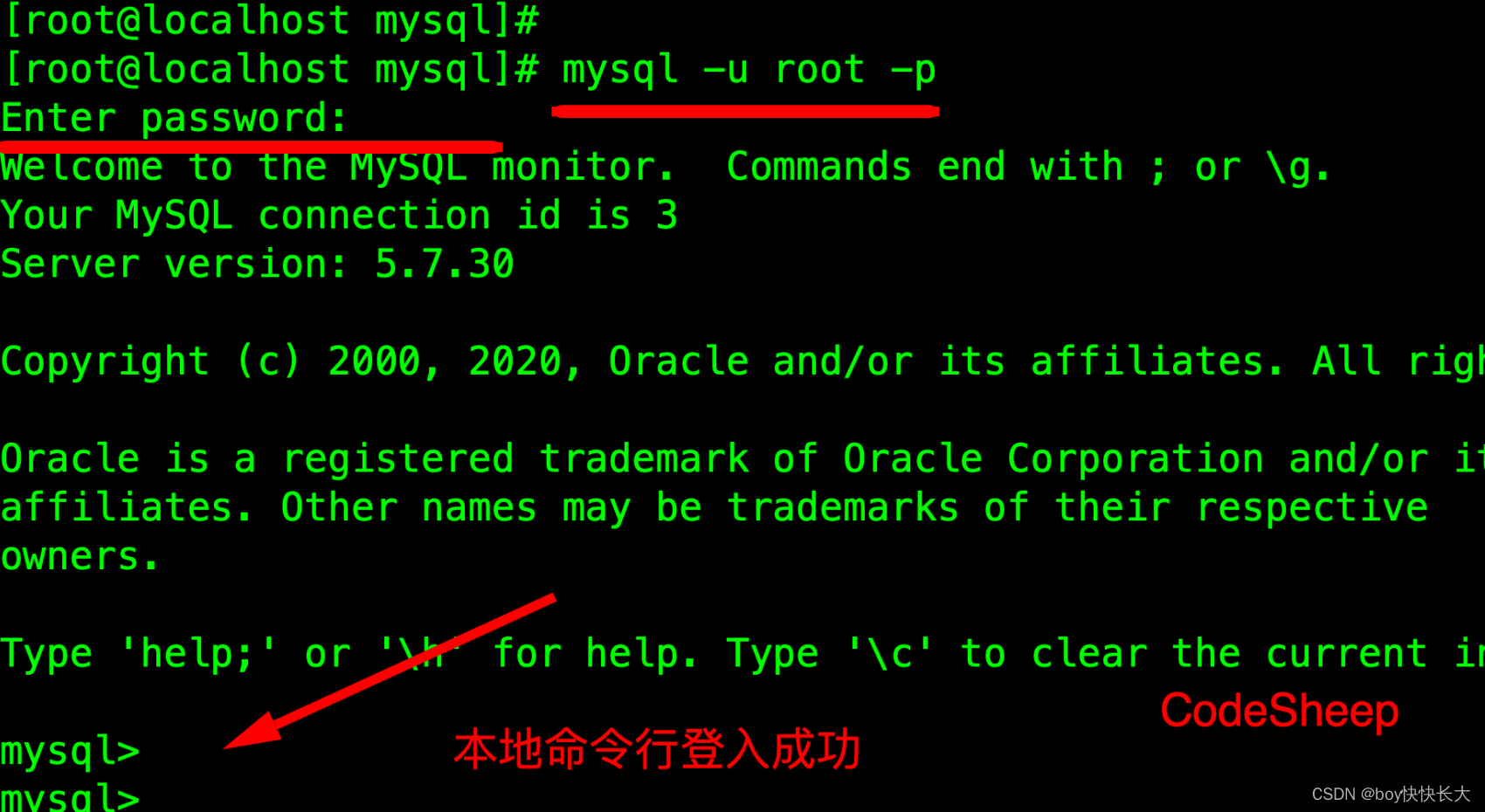
2.11 ⾸次登陆MYSQL
以 root 账户登录 mysql ,使⽤上⽂安装完成提示的密码进⾏登⼊
mysql -u root -p
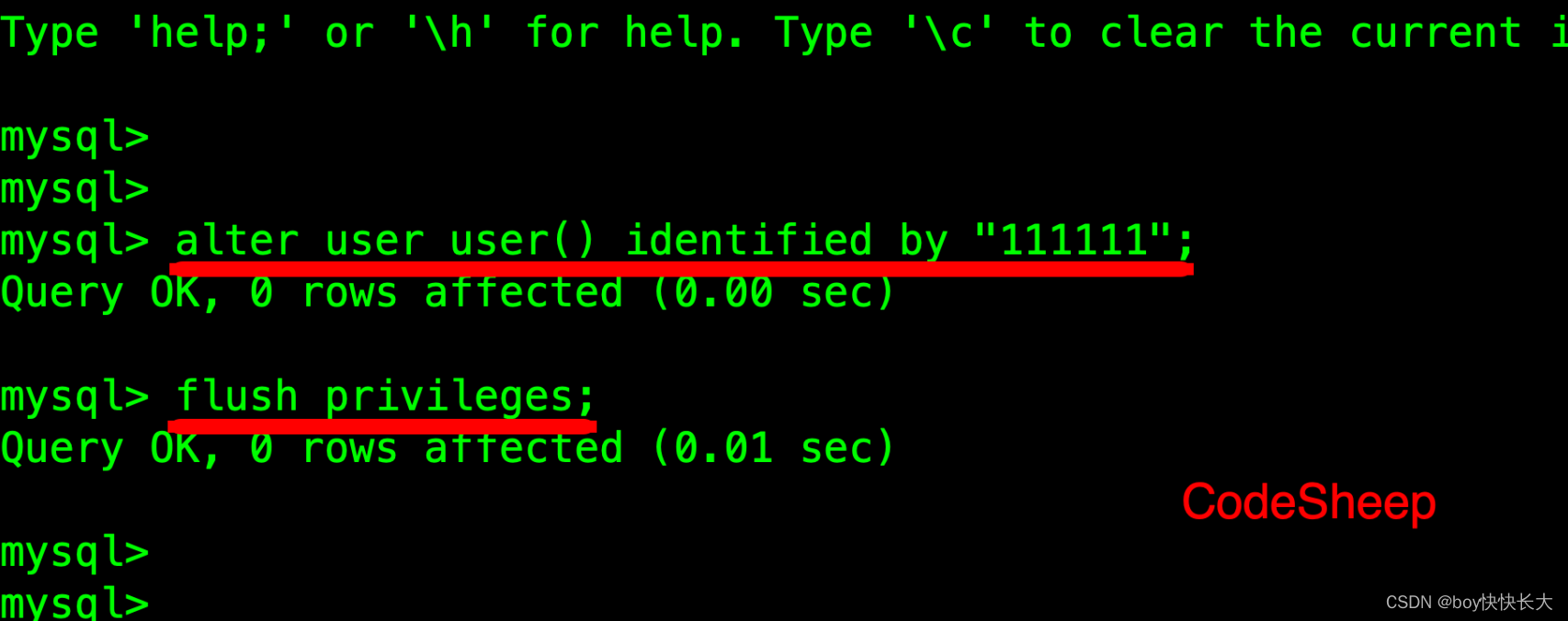
接下来修改ROOT账户密码
在mysql的命令⾏执⾏如下命令即可,密码可以换成你想⽤的密码即可:
mysql>alter user user() identified by "111111";
mysql>flush privileges;
2.12 设置远程主机登录
mysql> use mysql;
mysql> update user set user.Host='%' where user.User='root';
mysql> flush privileges;
2.2 Redis部署
这⾥下载的是 redis-5.0.8.tar.gz 安装包,并将其直接放在了 root ⽬录下
解压安装包
cd /usr/local/
mkdir redis
cd redis
将 Redis 安装包解压到 /usr/local/redis 中即可
[root@localhost redis]# tar zxvf /root/redis-5.0.8.tar.gz -C ./
解压完之后, /usr/local/redis ⽬录中会出现⼀个 redis-5.0.8 的⽬录
编译并安装
cd redis-5.0.8/
make && make install
将 REDIS 安装为系统服务并后台启动
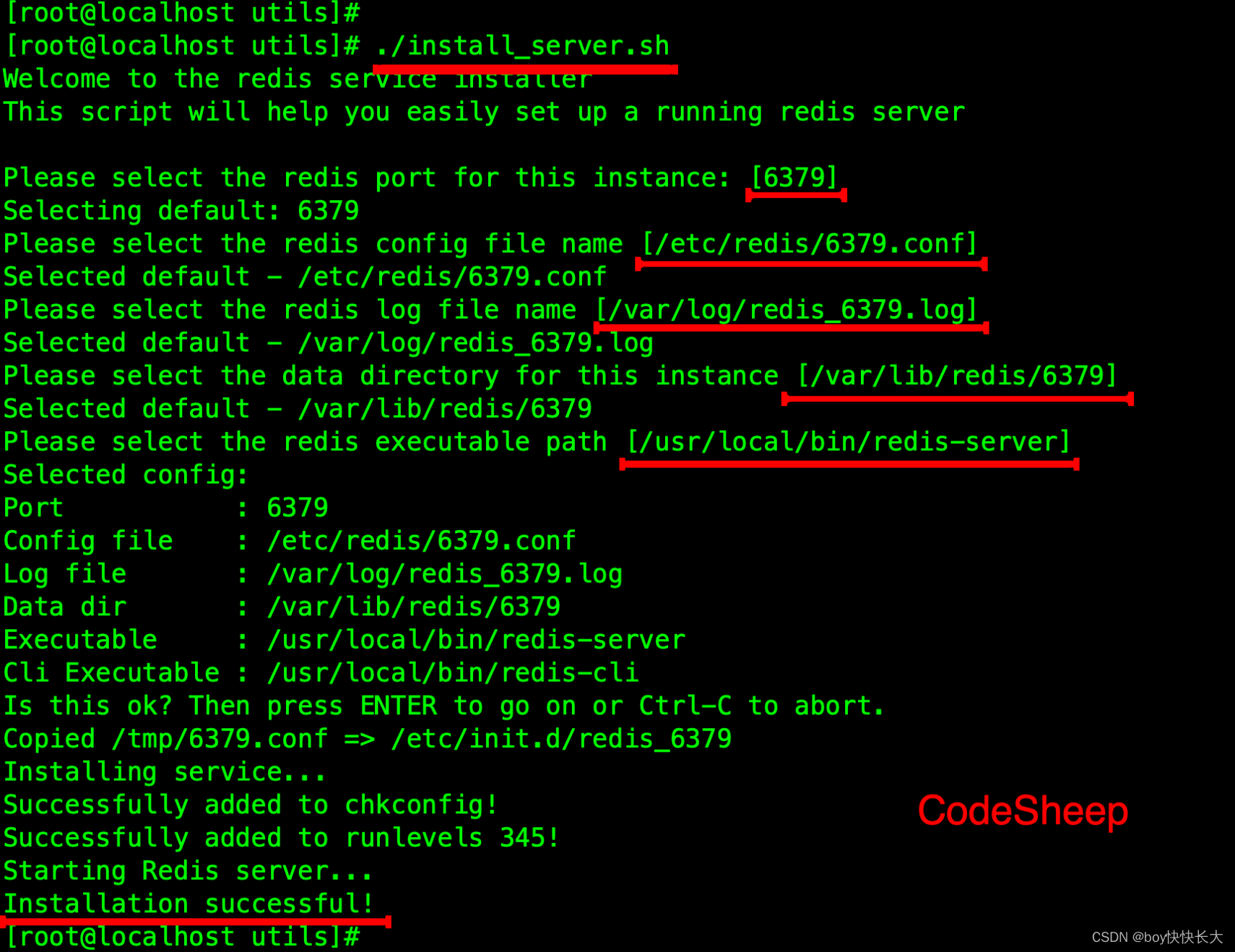
进⼊ utils ⽬录,并执⾏如下脚本即可:
[root@localhost redis-5.0.8]# cd utils/
[root@localhost utils]# ./install_server.sh
此处我全部选择的默认配置即可,有需要可以按需定制
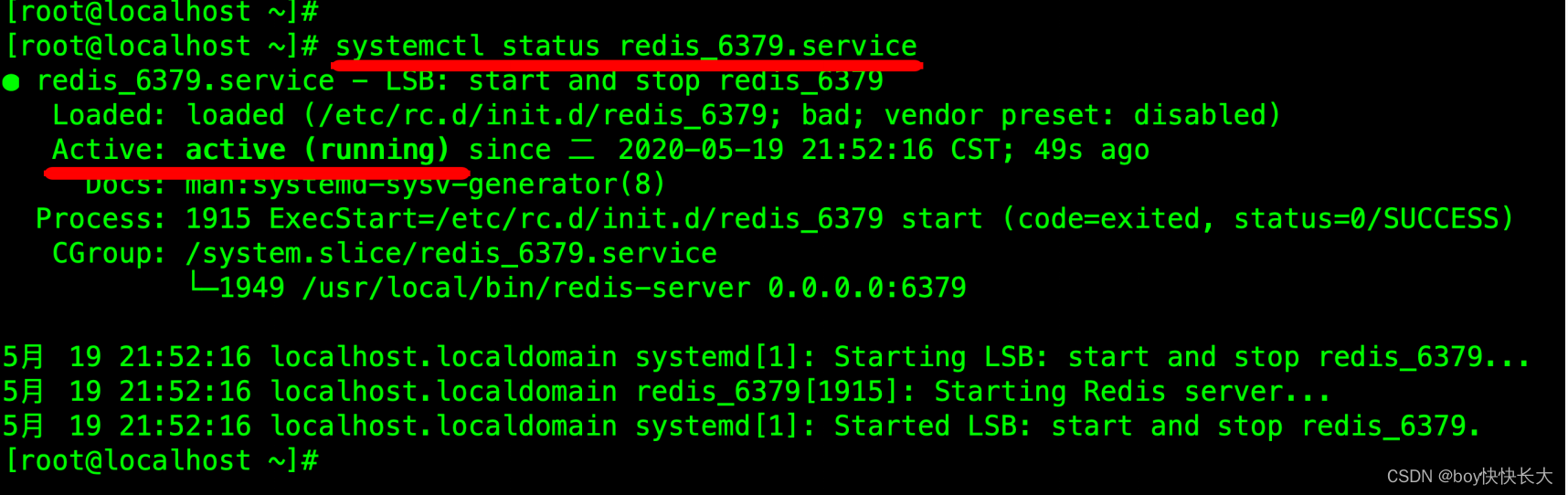
2.2.1 查看REDIS服务启动情况
直接执⾏如下命令来查看Redis的启动结果:
systemctl status redis_6379.service
启动REDIS客户端并测试
启动⾃带的 redis-cli 客户端,测试通过:
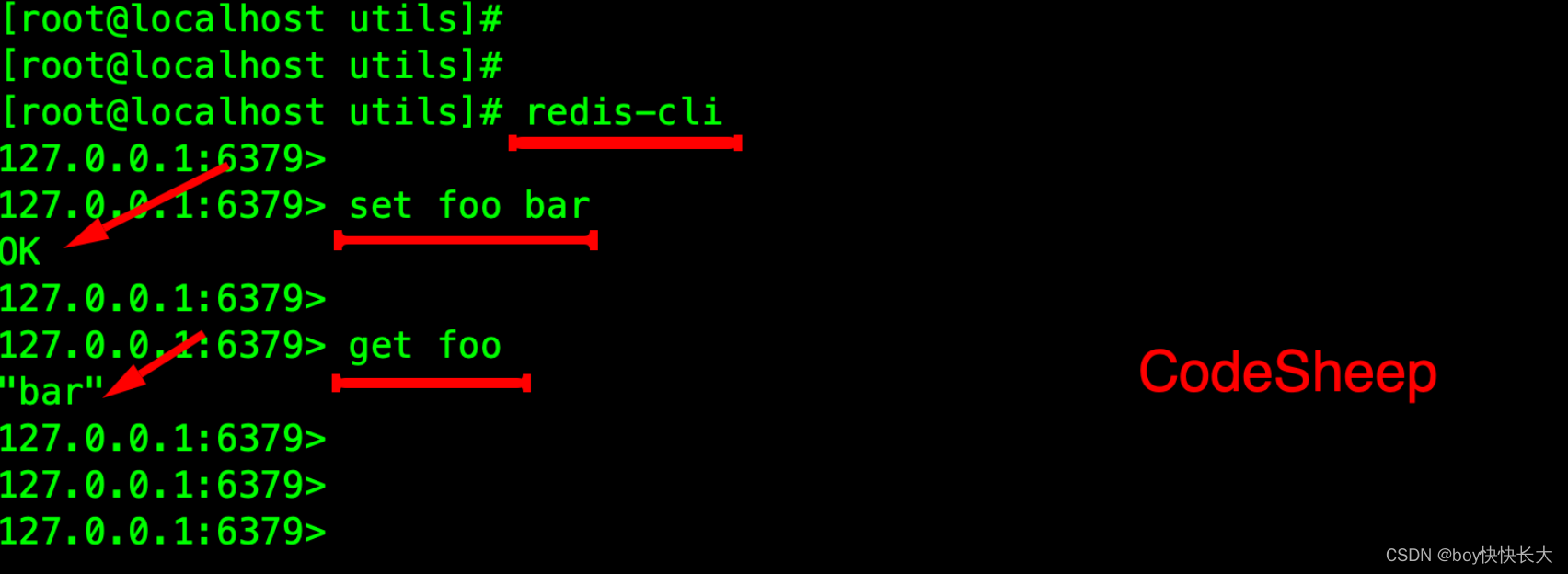
但是此时只能在本地访问,⽆法远程连接,因此还需要做部分设置
2.2.2 设置允许远程连接
编辑 redis 配置⽂件
vim /etc/redis/6379.conf
将 bind 127.0.0.1 修改为 0.0.0.0
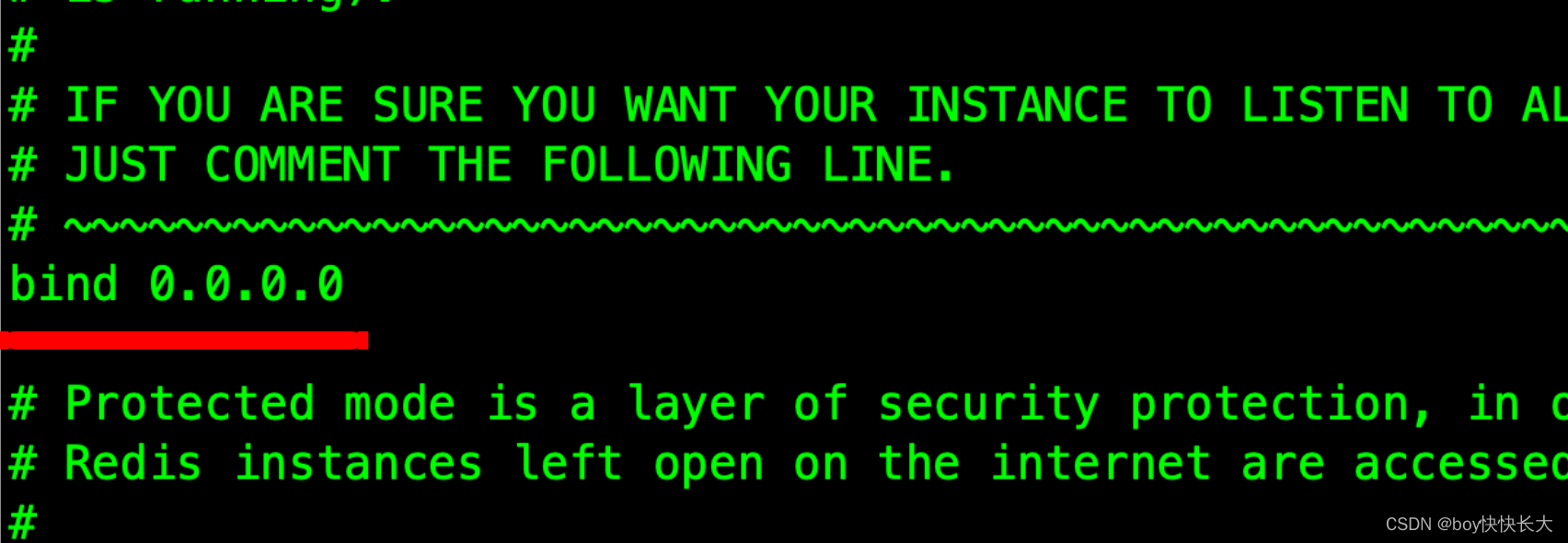
然后重启 Redis 服务即可:
systemctl restart redis_6379.service
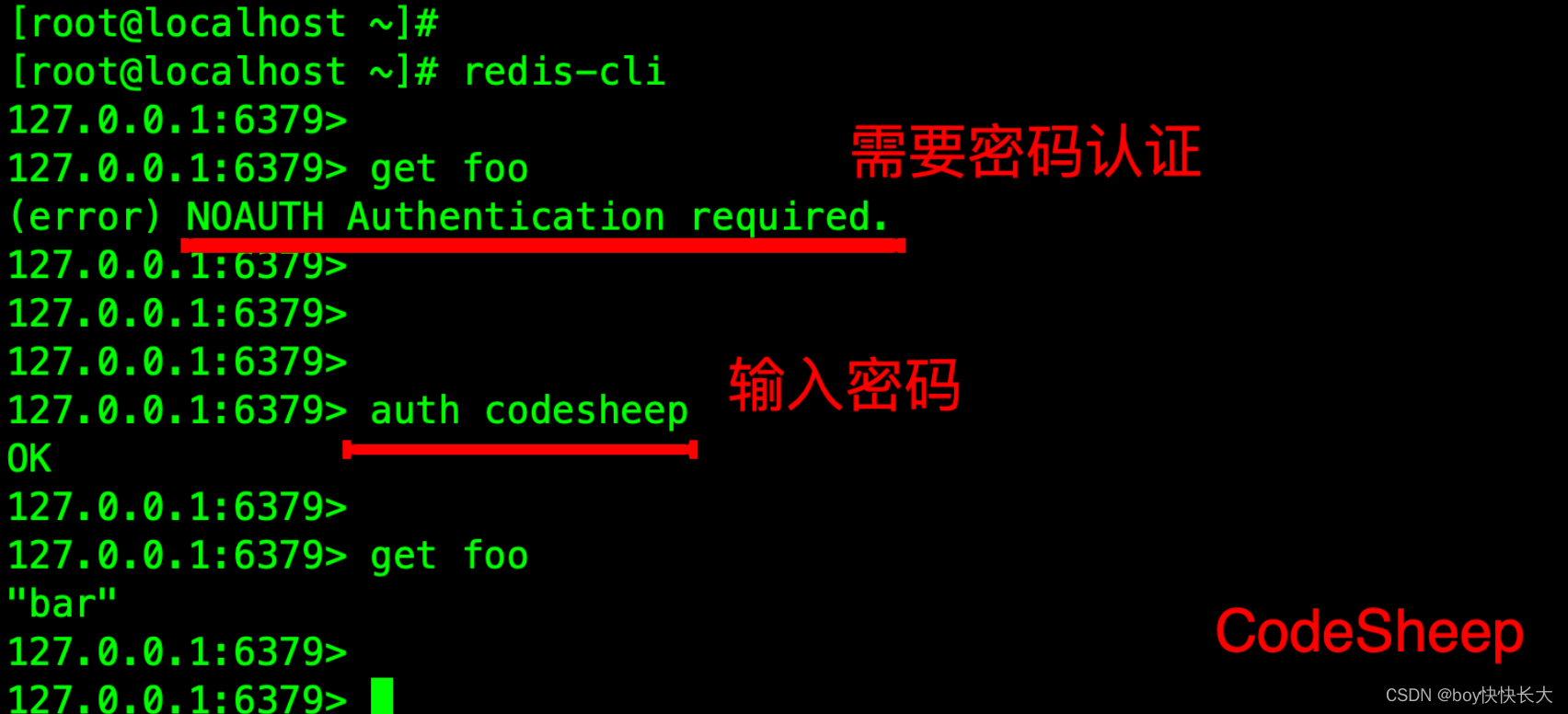
2.2.2 设置访问密码
编辑 redis配置⽂件
vim /etc/redis/6379.conf
找到如下内容:
#requirepass foobared
去掉注释,将 foobared 修改为⾃⼰想要的密码,保存即可。
requirepass codesheep
保存,重启 Redis 服务即可
systemctl restart redis_6379.service
这样后续的访问需要先输⼊密码认证通过⽅可:
3. 代码部分
代码仓库https://gitee.com/y_project/RuoYi-Vue 这是一个若依前后端分离项目。
3.1 本地调通
在本地数据库新建一个库,ry-vue
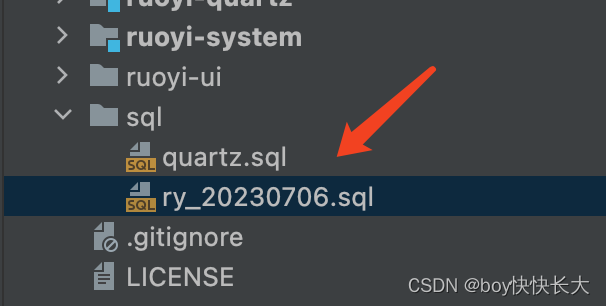
在图形化界面中执行若依项目中的两个SQL文件

在本地新建一个log文件夹,并将若依的日志指向调整为新建的目录
这里插入一个Homebrew的安装https://zhuanlan.zhihu.com/p/111014448
视频地址:
https://www.bilibili.com/video/BV1634y1t7B9/?share_source=copy_web&vd_source=6888e998072955ff0cd273996df291f5
Homebrew安装命令:
/bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)"
安装Redis
brew install redis启动redis
brew services start redis查看一下版本(复制如下代码到终端运行):
redis-server查看redis进程
ps axu | grep redis停止redis
brew services stop redis



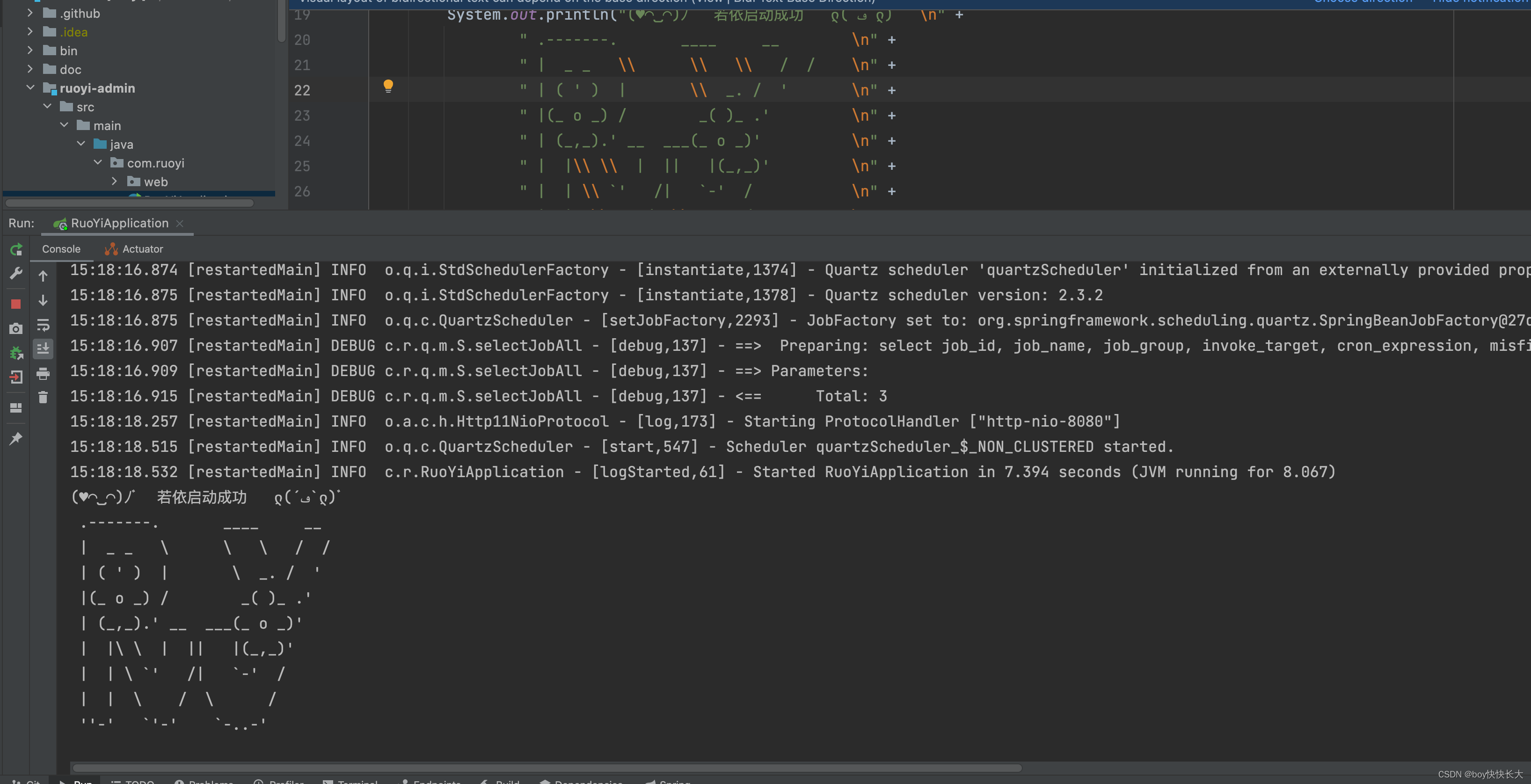
本地配置好redis、mysql、日志路径之后Redis可以正常启动
4. Linux小集群部署
共计3台服务器,分别是腾讯云、华为云、天翼云三台服务器。其中华为云部署前端以及提供MYSQL与Redis服务。另外两台部署后端服务。
华为云安装redis、MySQL
mysql 初始密码Mr%d;N?ce4<l

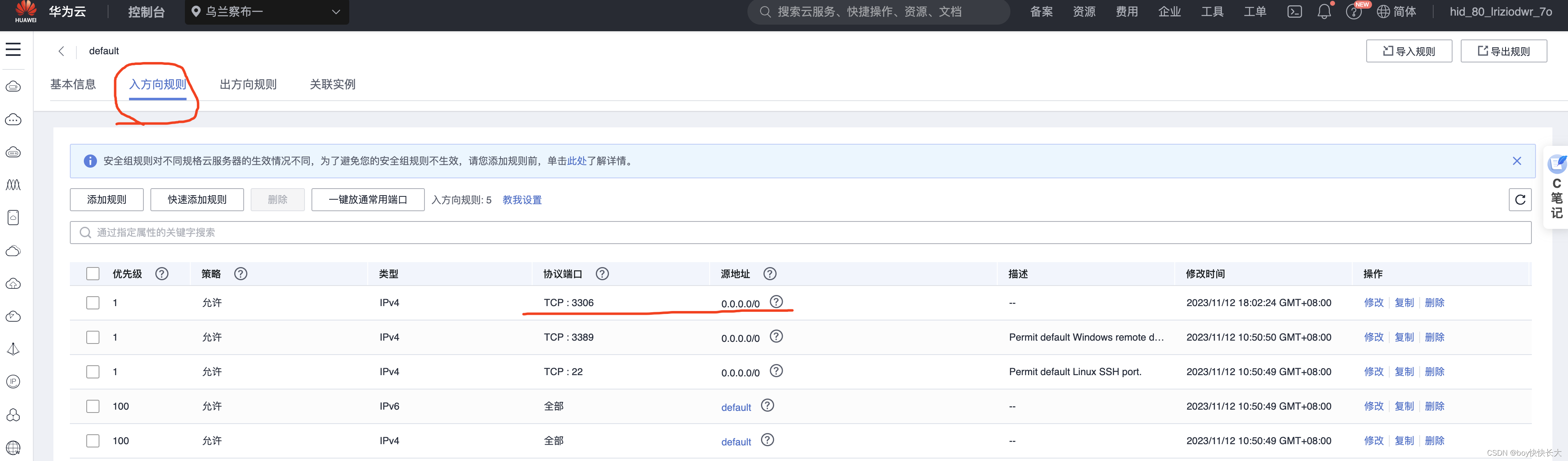
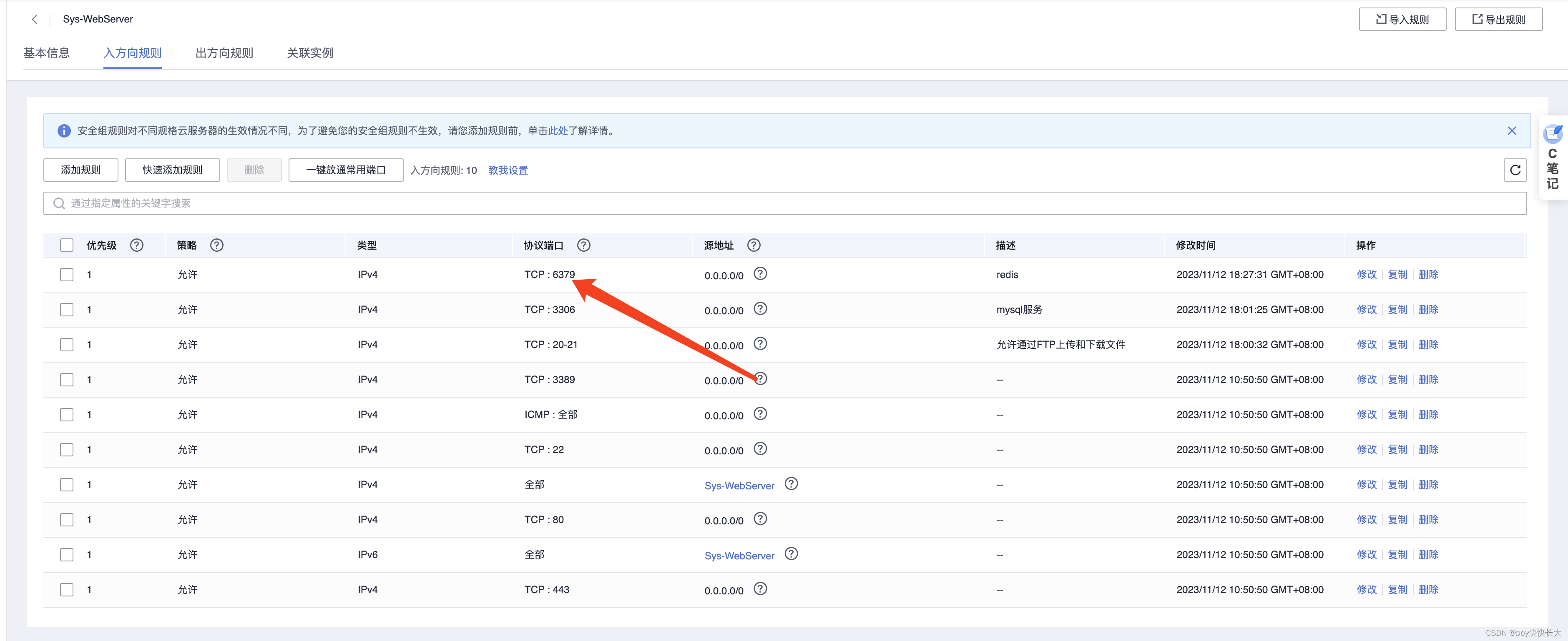
这里华为云需要修改入方向规则
代码中需要修改的地方

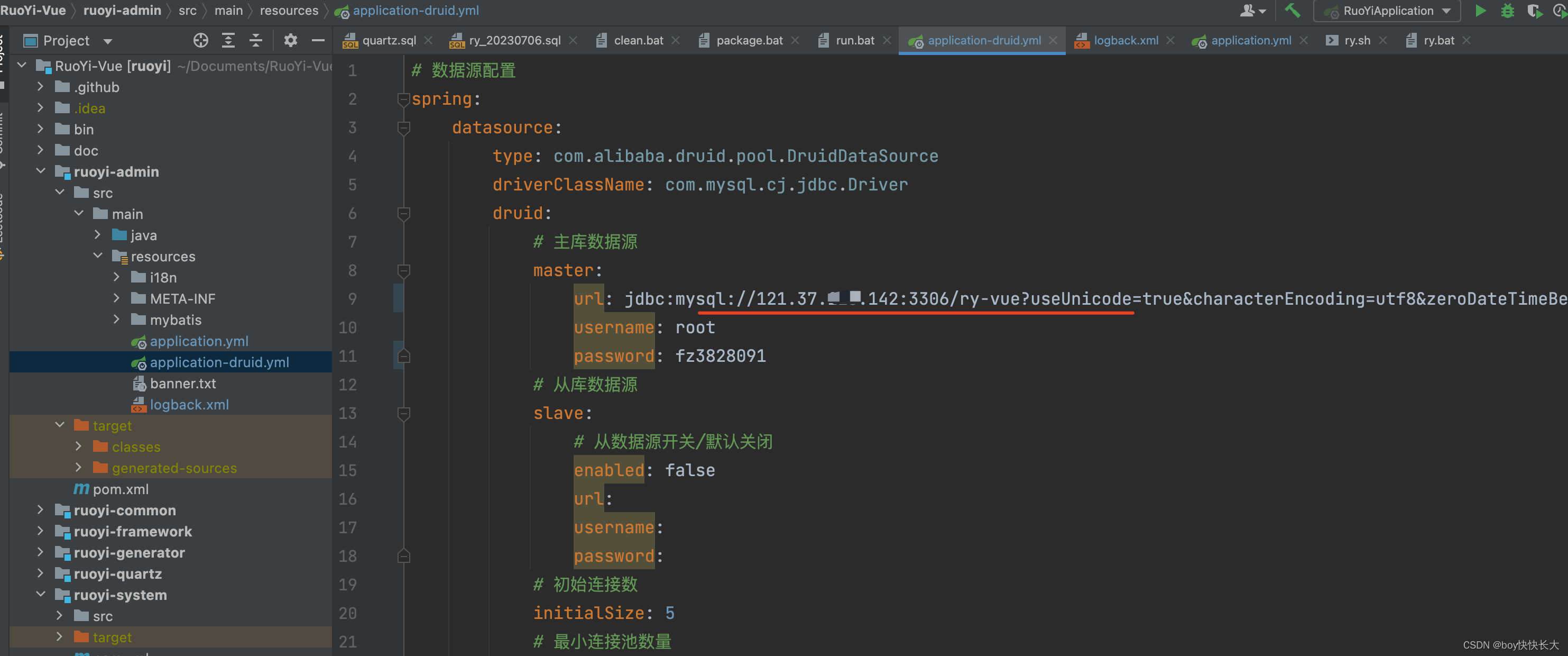
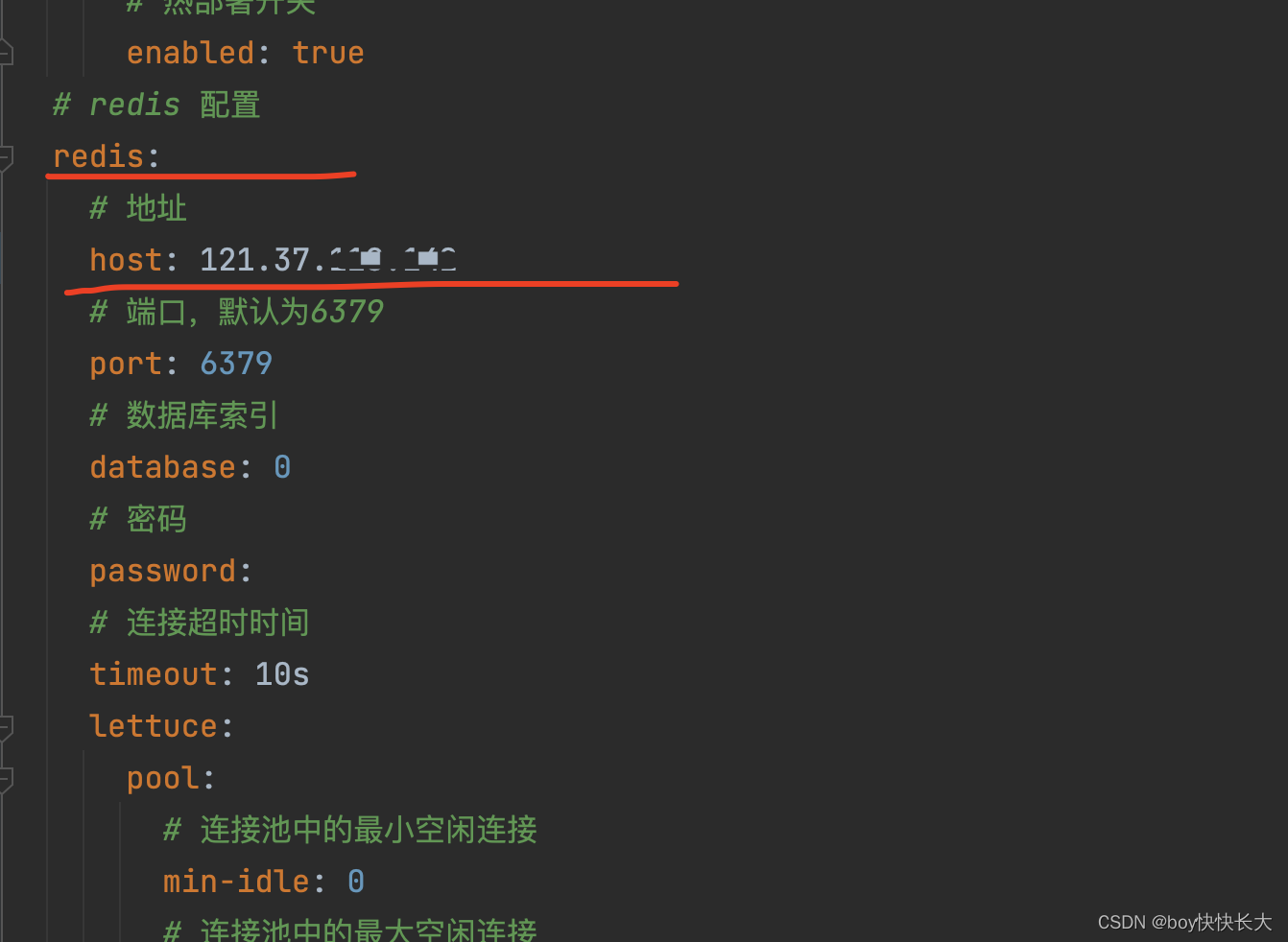
全部的encode地方加上charset

注意华为云6379接口要开放
4.1 前段代码(华为云)
我把ruoyi-ui的前段代码打包

上传到服务器中
然后在workspace中解压代码
华为云要安装nginx并且放开80端口
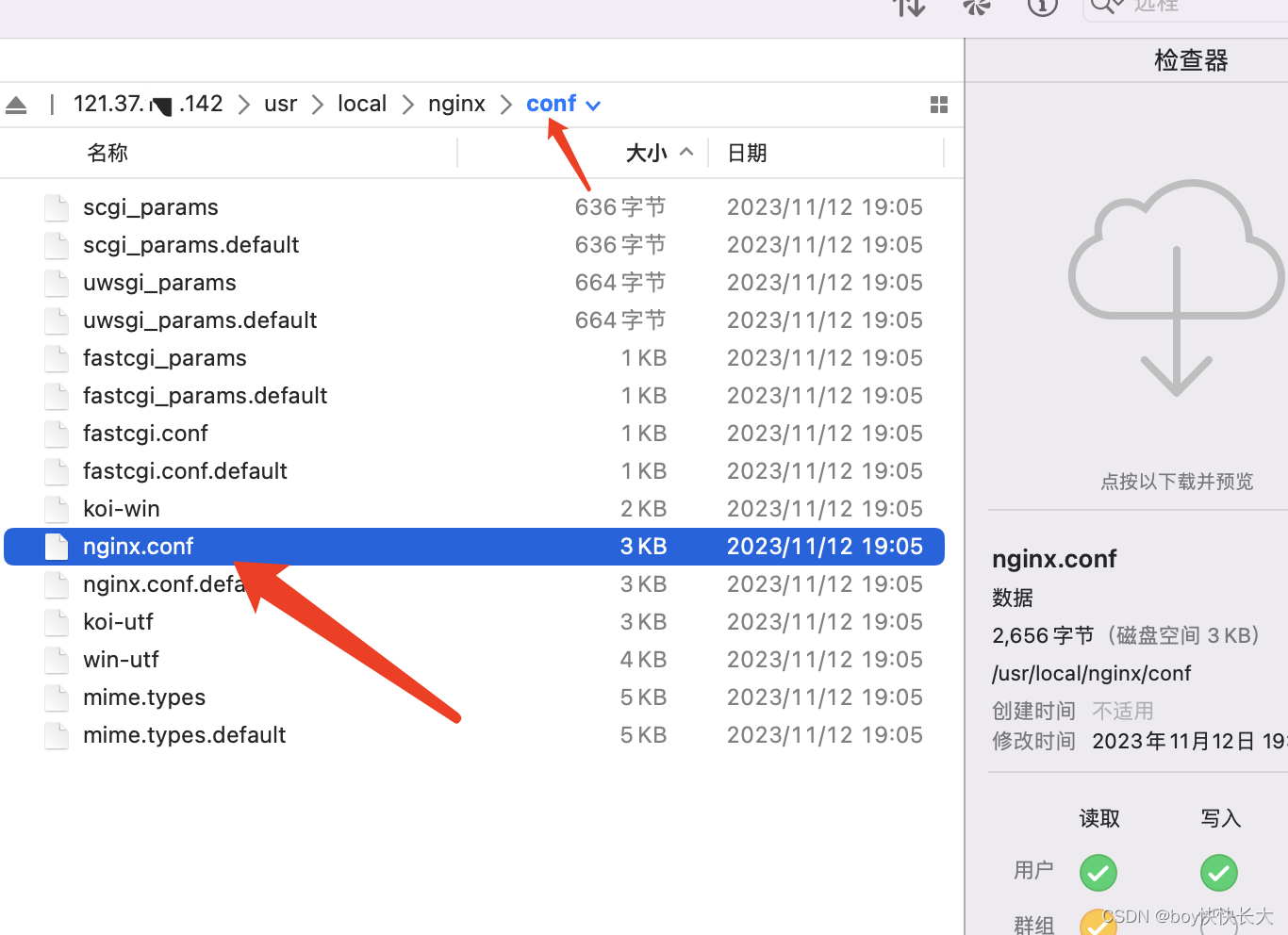
华为云中修改nginx文件

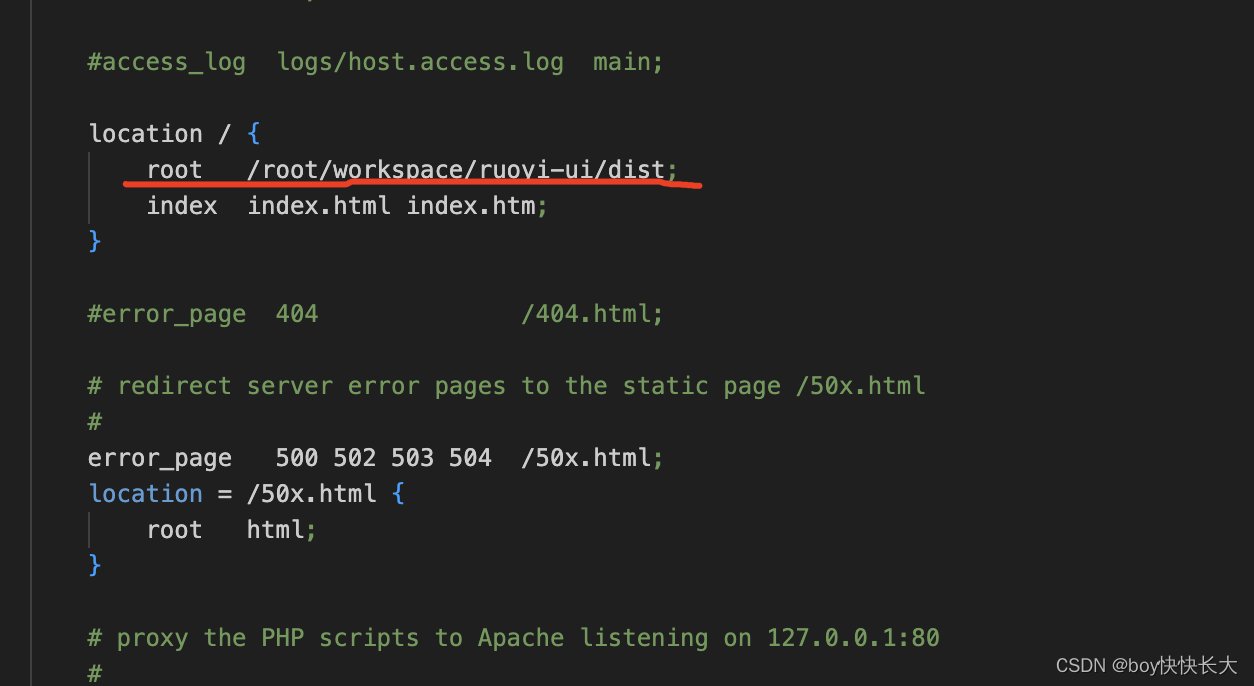
重启nginx之后前段就可以访问了
/usr/local/nginx/sbin/nginx -s reload
4.2 后端代码(天翼云、腾讯云)
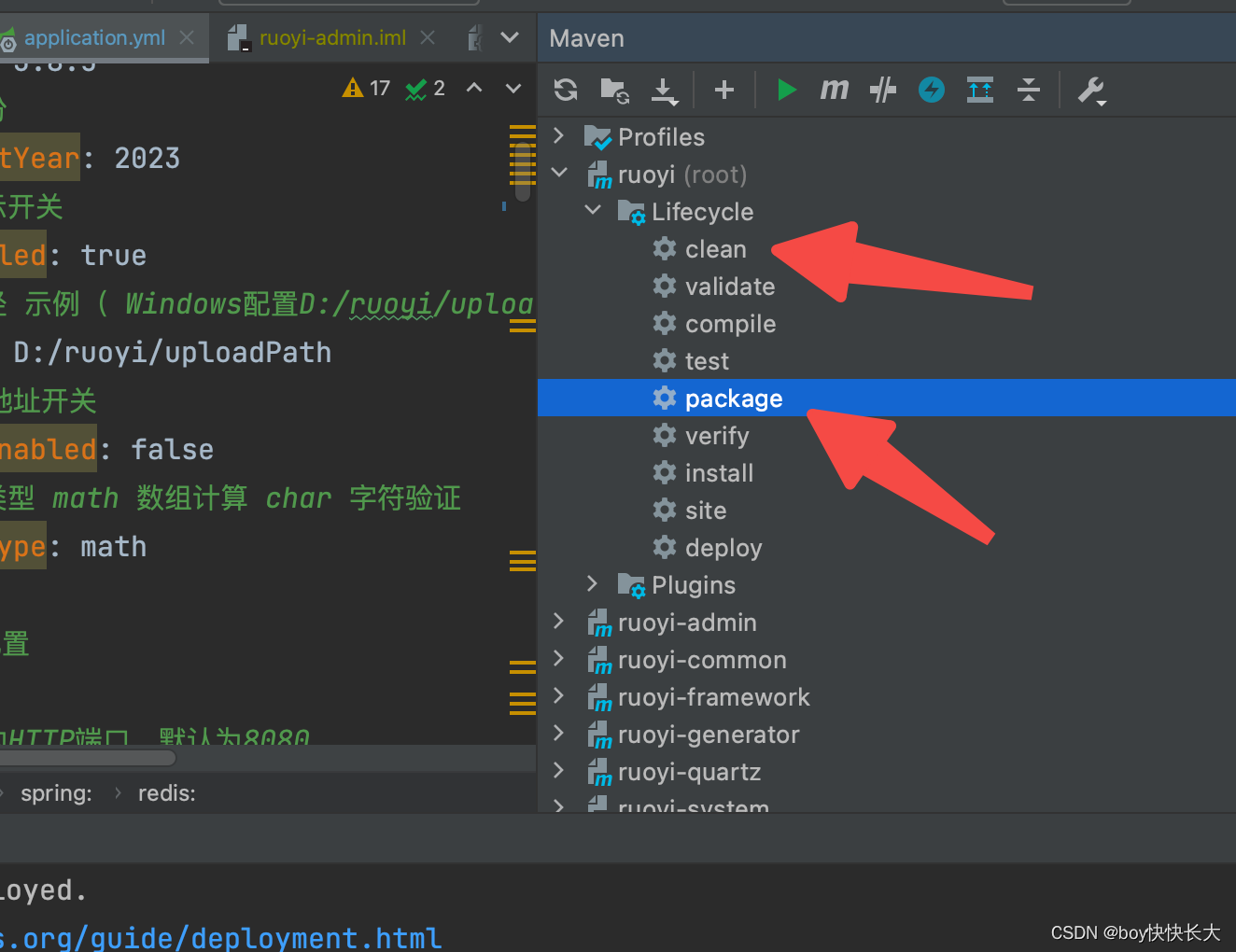

因为是SpringBOOT项目内置了Tomcat直接打jar包。上图是两种打包方式都可以。第一个图先clean后package。
jar包位置。
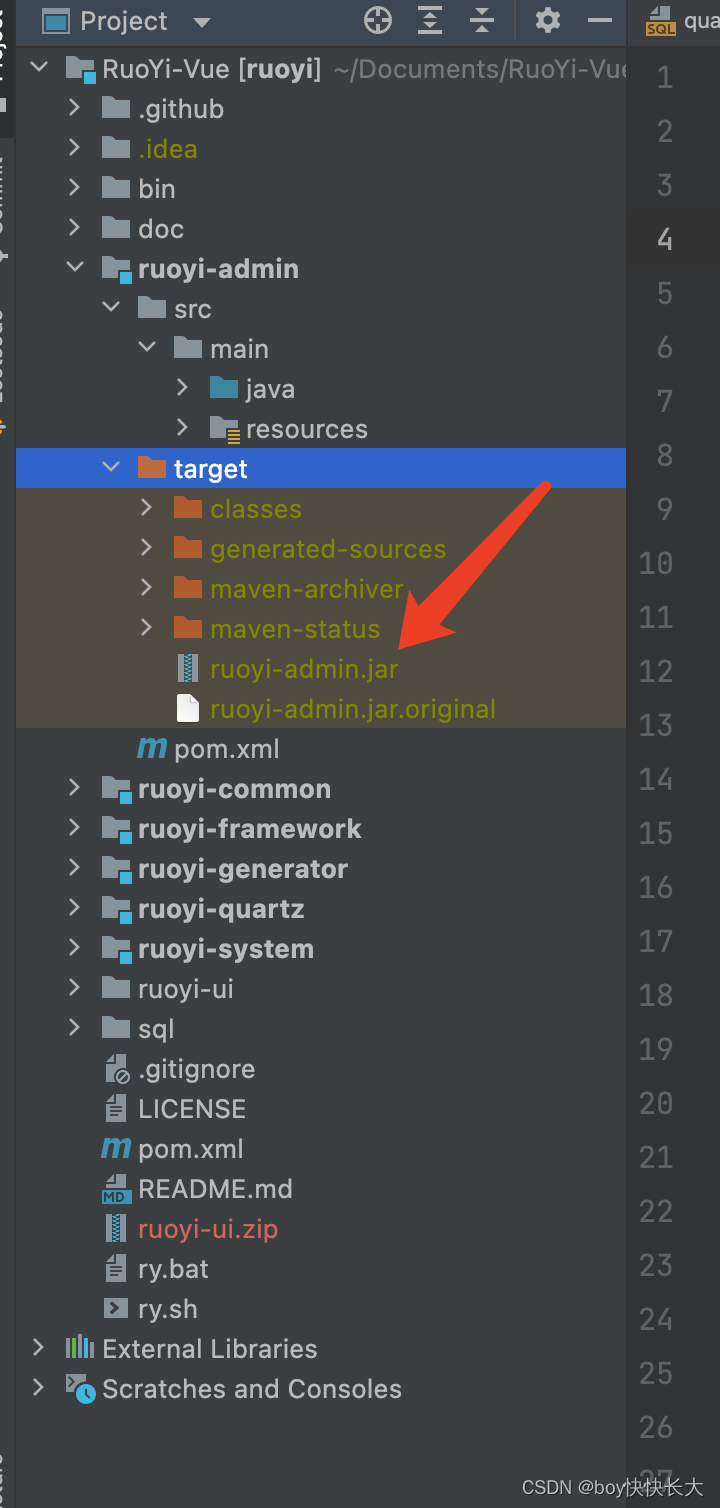
这里不打war包了,还要安装tomcat,需要打war包可以看视频(最上面的)
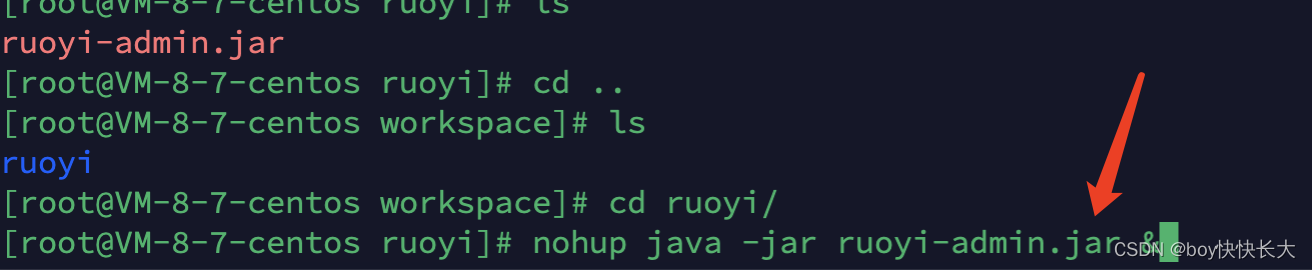
[root@VM-8-7-centos ruoyi]# pwd
/root/workspace/ruoyi[root@VM-8-7-centos ruoyi]# nohup java -jar ruoyi-admin.jar &

虽然前后端都发布了,但是前段的nginx代理还未配置。也就是说前段现在没有访问到后端接口
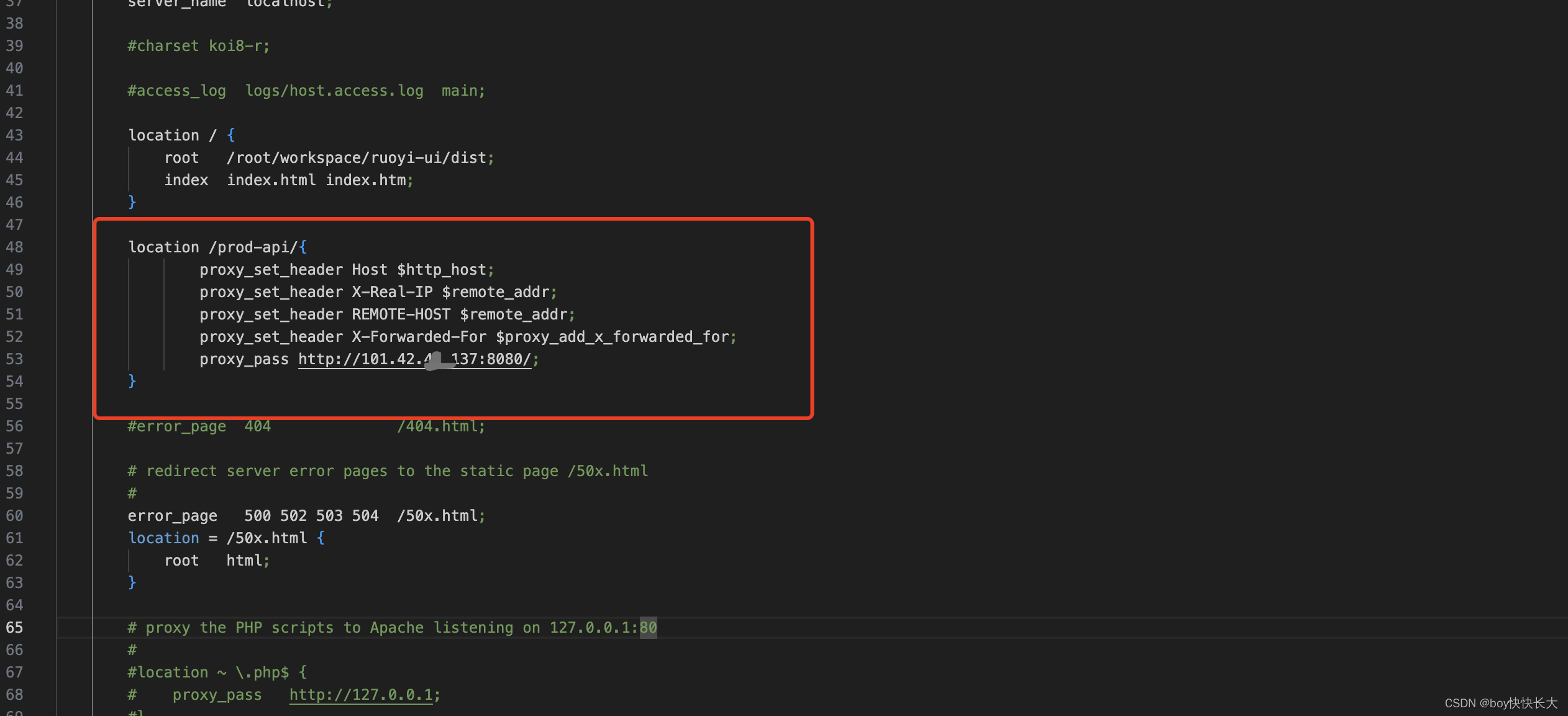
在华为云中修改了nginx并重启了nginx
这里腾讯云记得打开8080端口

为了集群部署,我们还是需要修改nginx,并设置天翼云权重为3,腾讯云的为5
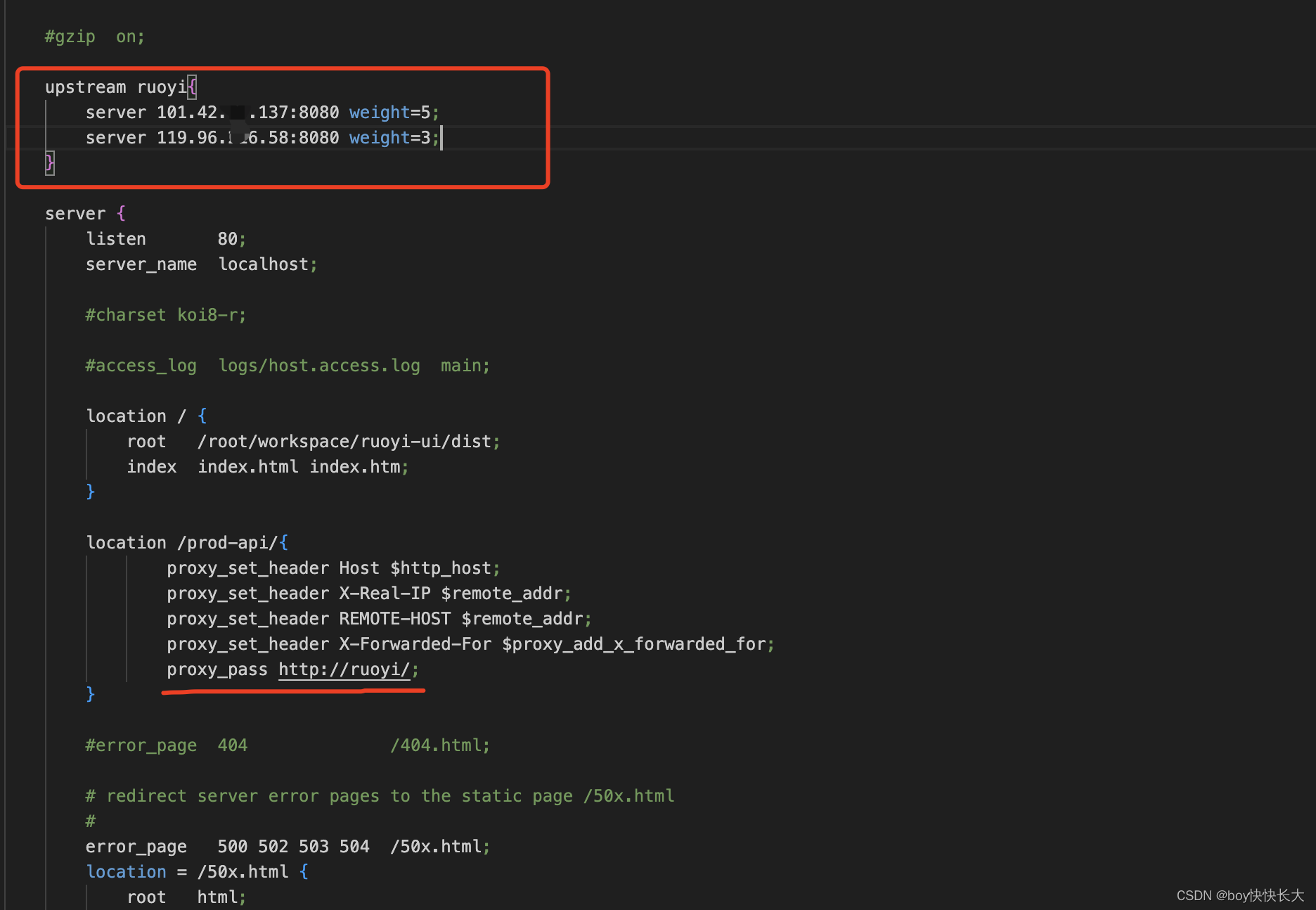
再次将nginx reload一下,当前天翼云的后端服务也运行起来了。
查看天翼云

这里天翼云有个坑,8080端口不备案不开放,我重新换成了8081端口
这里算是部署好了前后端

为了验证效果,以及看一下Nginx转发。当我输入错误验证码时可以看到多次访问的是腾讯服务器因为它的权重更高
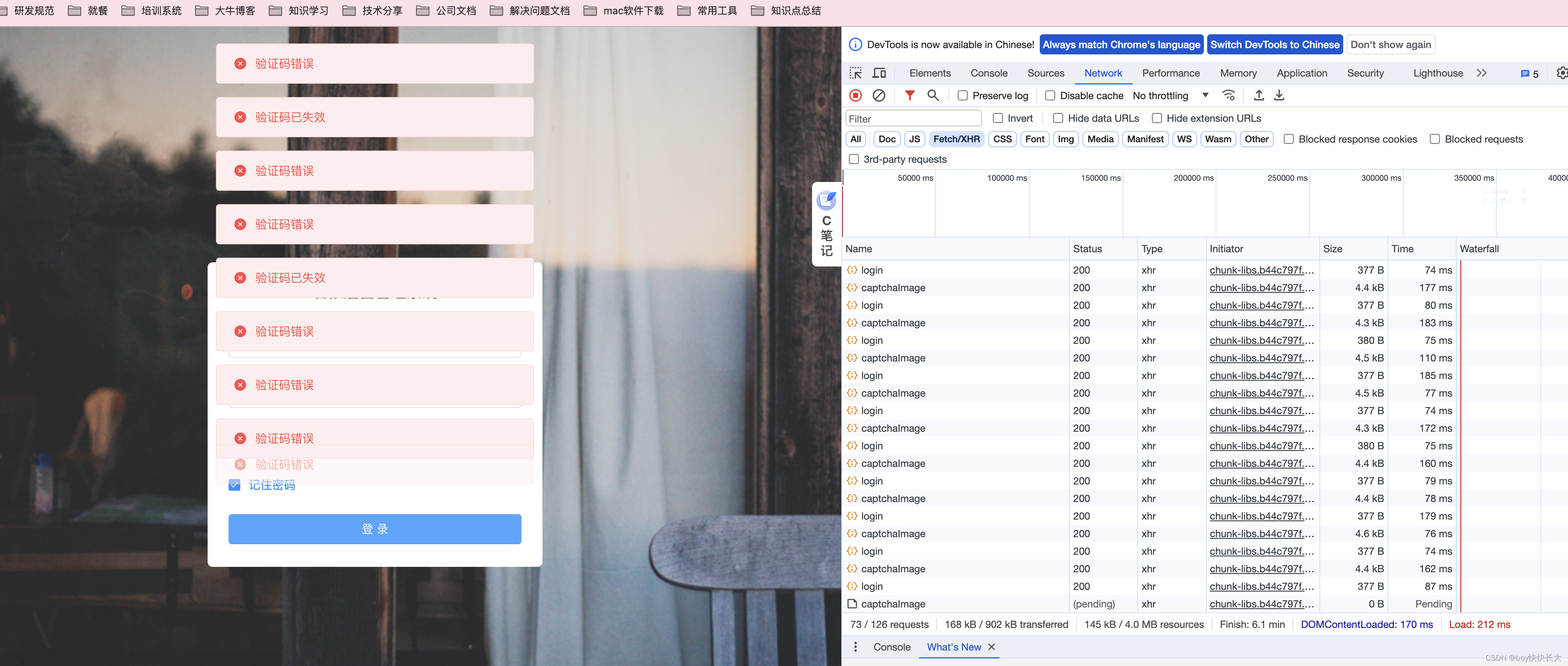
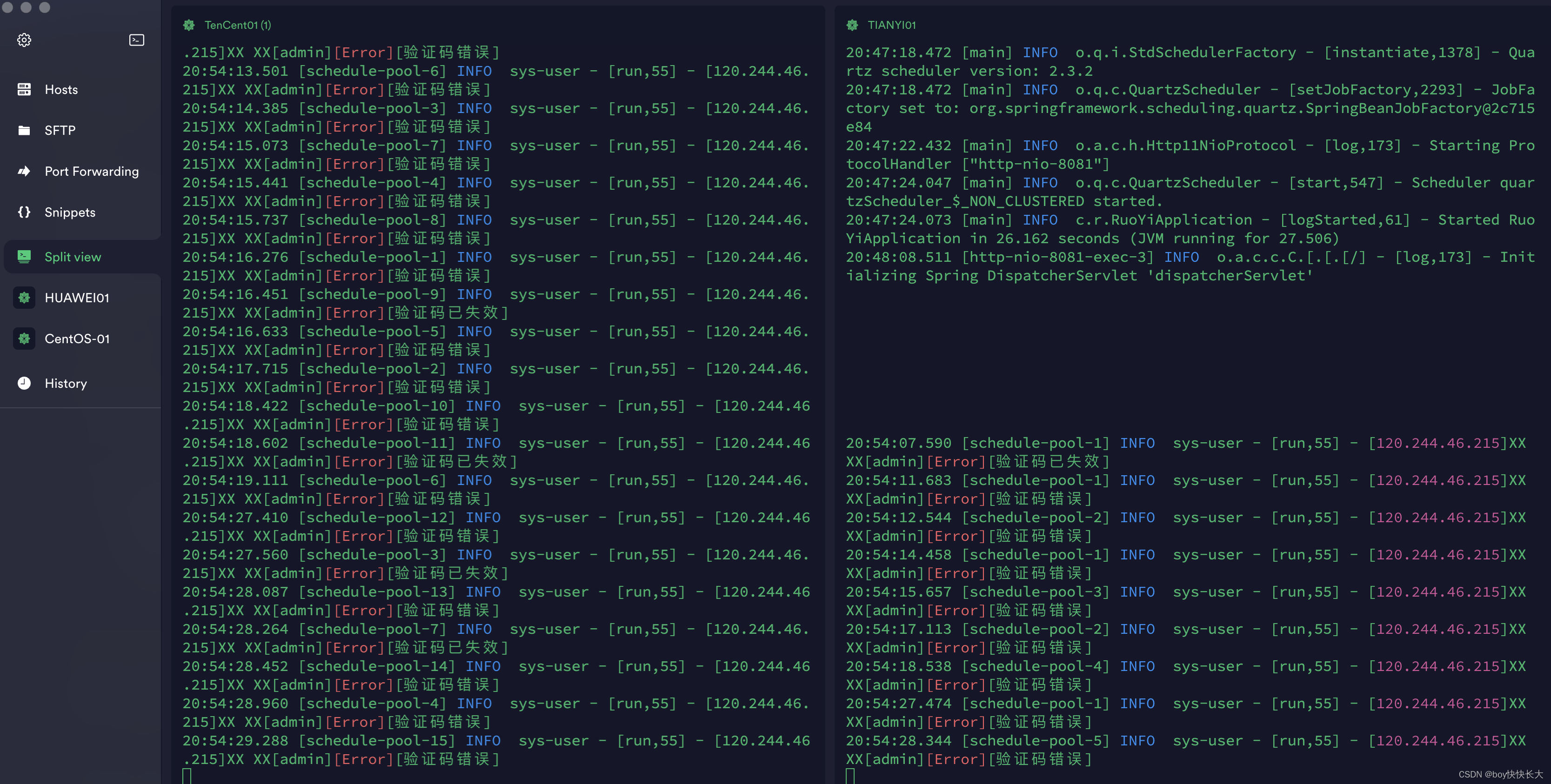
n.Docker部署(todo)
Docker请看我的专栏http://t.csdnimg.cn/2rLIs
3.1 Docker安装Mysql
这里我已经安装过mysql了,不熟悉如何Docker安装mysql可以看专栏。
我目前Docker正在run的容器有

此处我发现时间不准确。通过将NTP服务代理为阿里云解决。
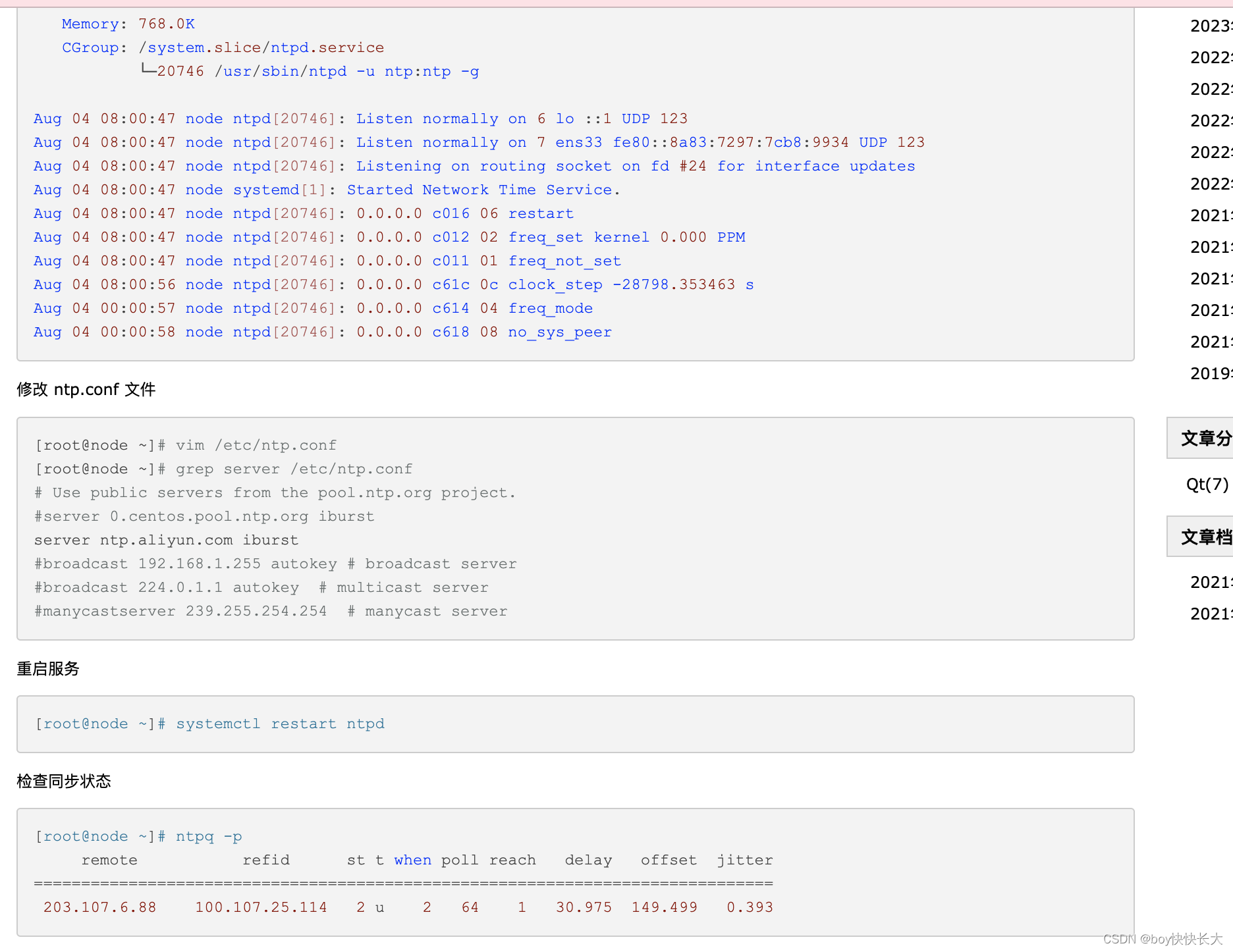
[root@node ~]# vim /etc/ntp.conf
[root@node ~]# grep server /etc/ntp.conf
# Use public servers from the pool.ntp.org project.
#server 0.centos.pool.ntp.org iburst
server ntp.aliyun.com iburst
#broadcast 192.168.1.255 autokey # broadcast server
#broadcast 224.0.1.1 autokey # multicast server
#manycastserver 239.255.254.254 # manycast server
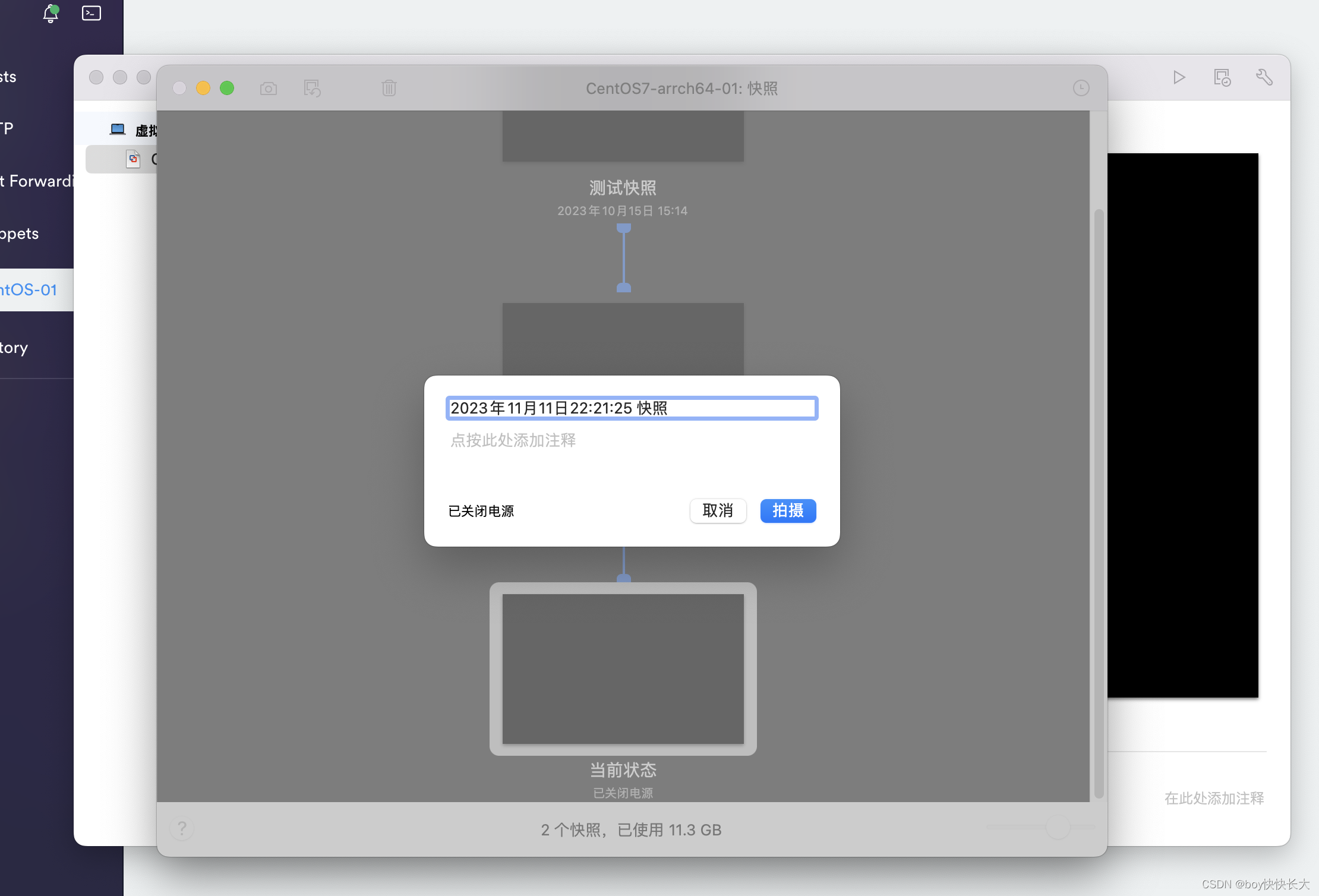
3.2 录制快照
附录
1.同步阿里云时间 https://www.cnblogs.com/liulianzhen99/articles/17637056.html
2.Mac 如何安装 Homebrew
3.Homebrew安装以及使用Redis