网络销售网站设置多用户商城系统哪里有
学生成绩管理程序
实例说明
编制一个统计存储在文件中的学生考试分数的管理程序。设学生成绩以一个学生一条记录的
形式存储在文件中,每个学生记录包含的信息有姓名、学号和各门功课的成绩。要求编制具有以
下几项功能的程序:求出各门课程的总分,平均分、按姓名,按学号寻找其记录并显示,浏览全
部学生成绩和按总分由高到低显示学生信息等。
程序运行结果

输入 l 命令后的结果

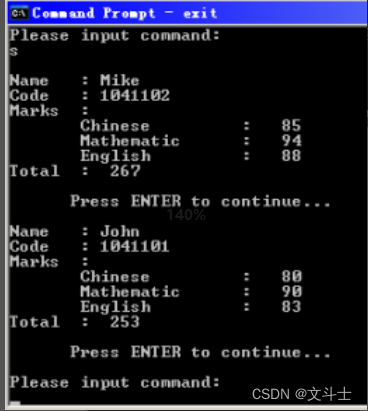
输入 s 命令后的结果
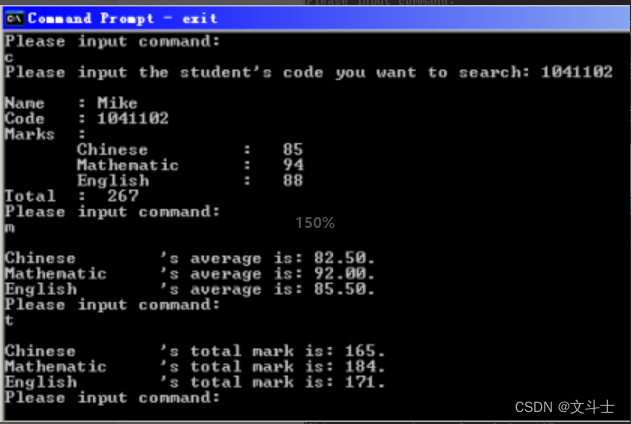
按姓名和学号查找记录的结果

计算平均分和总分
实例解析
设每位学生学习语文、数学和英语 3 门课程,主程序输入文件名之后,进入接受命令、执行
命令处理程序的循环。
按问题的要求共设 5 条命令:求各门课程的总分、求各门课程的平均分、按学生名字寻找其
信息、按学号寻找其信息、结束命令。
为求各门课程的总分,从文件逐一读出学生记录,累计各门课程的分数,待文件处理完即可
得到各门课程的总分。为求各门课程的平均分,从文件逐一读出学生记录,累计各门课程的分数,
并统计学生人数,待文件处理完毕,将得到的各门课程的总分除以人数就得到各门课程的平均分。
按学生名字寻找学生信息的处理,首先要求输入待寻找学生的名字,顺序读入学生记录,凡名字
与待寻找学生相同的记录都在屏幕上显示,直到文件结束。按学生学号寻找学生信息的处理,首
先要求输入待寻找学生的学号,顺序读入学生记录,发现有学号与待寻找学生相同的记录就在屏
幕上显示,并结束处理。浏览学生全部成绩,顺序读入学生记录,并在屏幕上显示,直到文件结
束。按总分由高到低显示学生信息,首先顺序读入学生记录并构造一个有序链表,然后顺序显示
链表上的各元素。
程序代码
#include <stdio.h>
#define SWN 3 /* 课程数 */
#define NAMELEN 20 /* 姓名最大字符数 */
#define CODELEN 10 /* 学号最大字符数 */
#define FNAMELEN 80 /* 文件名最大字符数 */
#define BUFLEN 80 /* 缓冲区最大字符数 */
/* 课程名称表 */
char schoolwork[SWN][NAMELEN+1] = {"Chinese","Mathematic","English"};
struct record
{ char name[NAMELEN+1]; /* 姓名 */ char code[CODELEN+1]; /* 学号 */ int marks[SWN]; /* 各课程成绩 */ int total; /* 总分 */
}stu; struct node
{ char name[NAMELEN+1]; /* 姓名 */ char code[CODELEN+1]; /* 学号 */ int marks[SWN]; /* 各课程成绩 */ int total; /* 总分 */ struct node *next; /* 后续表元指针 */
}*head; /* 链表首指针 */ int total[SWN]; /* 各课程总分 */
FILE *stfpt; /* 文件指针 */
char stuf[FNAMELEN]; /* 文件名 */
/* 从指定文件读入一条记录 */
int readrecord(FILE *fpt,struct record *rpt)
{ char buf[BUFLEN]; int i; if(fscanf(fpt,"%s",buf)!=1) return 0; /* 文件结束 */ strncpy(rpt->name,buf,NAMELEN); fscanf(fpt,"%s",buf); strncpy(rpt->code,buf,CODELEN); for(i=0;i<SWN;i++) fscanf(fpt,"%d",&rpt->marks[i]); for(rpt->total=0,i=0;i<SWN;i++) rpt->total+=rpt->marks[i]; return 1;
}
/* 对指定文件写入一条记录 */
void writerecord(FILE *fpt,struct record *rpt)
{ int i; fprintf(fpt,"%s\n",rpt->name); fprintf(fpt,"%s\n",rpt->code); for(i=0;i<SWN;i++) fprintf(fpt,"%d\n",rpt->marks[i]); return ;
} /* 显示学生记录 */
void displaystu(struct record *rpt)
{ int i; printf("\nName : %s\n",rpt->name); printf("Code : %s\n",rpt->code); printf("Marks :\n"); for(i=0;i<SWN;i++) printf(" %-15s : %4d\n",schoolwork[i],rpt->marks[i]); printf("Total : %4d\n",rpt->total);
}
/* 计算各单科总分 */
int totalmark(char *fname)
{ FILE *fp; struct record s; int count,i; if((fp=fopen(fname,"r"))==NULL) { printf("Can't open file %s.\n",fname); return 0; } for(i=0;i<SWN;i++) total[i]=0; count=0; while(readrecord(fp,&s)!=0) { for(i=0;i<SWN;i++) total[i]+=s.marks[i]; count++; } fclose(fp); return count; /* 返回记录数 */
} /* 列表显示学生信息 */
void liststu(char *fname)
{ FILE *fp; struct record s; if((fp=fopen(fname,"r"))==NULL) {printf("Can't open file %s.\n",fname); return ; } while(readrecord(fp,&s)!=0) { displaystu(&s); printf("\n Press ENTER to continue...\n"); while(getchar()!='\n'); } fclose(fp); return;
} /* 构造链表 */
struct node *makelist(char *fname)
{ FILE *fp; struct record s; struct node *p,*u,*v,*h; int i; if((fp=fopen(fname,"r"))==NULL) { printf("Can't open file %s.\n",fname); return NULL; } h=NULL; p=(struct node *)malloc(sizeof(struct node)); while(readrecord(fp,(struct record *)p)!=0) { v=h; while(v&&p->total<=v->total) { u=v; v=v->next; } if(v==h) h=p; else u->next=p; p->next=v; p=(struct node *)malloc(sizeof(struct node)); } free(p); fclose(fp); return h;
} /* 顺序显示链表各表元 */
void displaylist(struct node *h)
{ while(h!=NULL) { displaystu((struct record *)h); printf("\n Press ENTER to continue...\n");while(getchar()!='\n'); h=h->next; } return;
}
/* 按学生姓名查找学生记录 */
int retrievebyn(char *fname, char *key)
{ FILE *fp; int c; struct record s; if((fp=fopen(fname,"r"))==NULL) { printf("Can't open file %s.\n",fname); return 0; } c=0; while(readrecord(fp,&s)!=0) { if(strcmp(s.name,key)==0) { displaystu(&s); c++; } } fclose(fp); if(c==0) printf("The student %s is not in the file %s.\n",key,fname); return 1;
} /* 按学生学号查找学生记录 */
int retrievebyc(char *fname, char *key)
{ FILE *fp; int c; struct record s; if((fp=fopen(fname,"r"))==NULL) { printf("Can't open file %s.\n",fname); return 0; } c=0; while(readrecord(fp,&s)!=0) { if(strcmp(s.code,key)==0) { displaystu(&s); c++; break; } } fclose(fp); if(c==0)printf("The student %s is not in the file %s.\n",key,fname); return 1;
} /*示意程序*/
int main()
{int i,j,n; char c; char buf[BUFLEN]; FILE *fp; struct record s; clrscr(); printf("Please input the students marks record file's name: "); scanf("%s",stuf); if((fp=fopen(stuf,"r"))==NULL) { printf("The file %s doesn't exit, do you want to creat it? (Y/N) ",stuf); getchar(); c=getchar(); if(c=='Y'||c=='y') { fp=fopen(stuf,"w"); printf("Please input the record number you want to write to the file: "); scanf("%d",&n); for(i=0;i<n;i++) { printf("Input the student's name: "); scanf("%s",&s.name); printf("Input the student's code: "); scanf("%s",&s.code); for(j=0;j<SWN;j++) { printf("Input the %s mark: ",schoolwork[j]); scanf("%d",&s.marks[j]); } writerecord(fp,&s); } fclose(fp); } } fclose(fp); getchar(); /*clrscr();*/ puts("Now you can input a command to manage the records."); puts("m : mean of the marks."); puts("t : total of the marks."); puts("n : search record by student's name."); puts("c : search record by student's code."); puts("l : list all the records."); puts("s : sort and list the records by the total."); puts("q : quit!"); while(1) { puts("Please input command:");scanf(" %c",&c); /* 输入选择命令 */ if(c=='q'||c=='Q') { puts("\n Thank you for your using."); break; /* q,结束程序运行 */ } switch(c) { case 'm': /* 计算平均分 */ case 'M': if((n=totalmark(stuf))==0) { puts("Error!"); break; } printf("\n"); for(i=0;i<SWN;i++) printf("%-15s's average is: %.2f.\n",schoolwork[i], (float) total[i]/n); break; case 't': /* 计算总分 */ case 'T': if((n=totalmark(stuf))==0) { puts("Error!"); break; } printf("\n"); for(i=0;i<SWN;i++) printf("%-15s's total mark is: %d.\n",schoolwork[i], total[i]); break; case 'n': /* 按学生的姓名寻找记录 */ case 'N': printf("Please input the student's name you want to search: ");scanf("%s",buf); retrievebyn(stuf,buf); break; case 'c': /* 按学生的学号寻找记录 */ case 'C': printf("Please input the student's code you want to search: ");scanf("%s",buf); retrievebyc(stuf,buf); break; case 'l': /* 列出所有学生记录 */ case 'L': liststu(stuf); break; case 's': /* 按总分从高到低排列显示 */ case 'S': if((head=makelist(stuf))!=NULL) displaylist(head); break; default: break;} } return 0;
}
归纳注释
本程序除为每个处理功能编写相应的函数外,另外编写从文件读学生记录的函数、写记录到
文件和显示一个学生记录的函数,从而简化编程。