购物网站备案费用提供网站建设搭建
一、需求分析
1、系统定义
在线花卉商城是一个通过互联网提供花卉销售服务的电子商务平台,用户可以在该平台上浏览、选择和购买各种花卉产品。
2、功能需求
在线花卉商城是一个通过互联网提供花卉销售服务的电子商务平台,用户可以在该平台上浏览、选择和购买各种花卉产品。在线花卉商城通常包含以下功能:
产品展示
- 花卉分类: 将花卉按照种类、颜色、用途等分类展示,方便用户浏览。
- 产品详情: 提供详细的产品信息,包括花卉名称、价格、描述、图片等。
- 推荐商品: 根据用户的浏览历史或购买记录推荐相关的商品。
购物功能
- 购物车: 用户可以将感兴趣的商品加入购物车,方便统一结算。
- 下单流程: 提供简洁明了的购买流程,包括选择商品、填写收货信息、选择支付方式等。
- 订单管理: 用户可以查看订单状态、订单历史记录等。
用户管理
- 用户注册登录: 用户可以注册账号并登录,保存个人信息和订单记录。
- 个人中心: 用户可以管理个人信息、地址、收藏的商品等。
- 评价功能: 用户可以对购买的商品进行评价,帮助其他用户选择合适的商品。
支付功能
- 多种支付方式: 支持多种支付方式,如在线支付、货到付款、支付宝、微信支付等。
- 支付安全: 提供安全可靠的支付环境,保障用户支付信息的安全。
订单管理
- 订单跟踪: 提供订单跟踪功能,让用户随时了解订单状态。
- 订单管理: 商家可以管理订单,包括确认订单、发货、退款等操作。
3、技术分析
- HTML,是一种制作万维网页面的标准语言,它消除了不同计算机之间信息交流的障碍;
- CSS,可以帮助把网页外观做得更加美观;
- JavaScript,是一种轻量级的解释型编程语言;
- jQuery,使用户能更方便地处理HTML documents、events、实现动画效果,并且方便地为网站提供AJAX交互;
- Bootstrap 是快速开发 Web 应用程序的前端工具包。它是一个 CSS,HTML 和 JS 的集合,它使用了最新的浏览器技术,给你的 Web 开发提供了时尚的版式;
- AJAX,创建交互式网页应用的网页开发技术。
4、设计思路
用户友好性:界面简洁直观,易于操作,减少用户的学习成本。
模块化设计:将系统功能模块化,每个模块负责一类功能,方便扩展和维护。
Responsiveness:后台管理系统应当是响应式设计,能够适配不同设备屏幕大小,包括电脑、平板和手机等。
权限控制:根据用户角色设定不同的权限,确保用户只能访问其权限范围内的功能。
数据安全:对用户数据进行加密存储、访问控制等措施,保护用户隐私和系统安全。
日志功能:记录关键操作日志,保留操作痕迹,便于审计和追踪问题。
系统性能:考虑系统的性能优化,包括减少不必要的数据读写、合理利用缓存等,提高系统响应速度。
二、界面展示
1、系统首页
 【广告】
【广告】
2、花卉导航栏
 【花卉详情】
【花卉详情】
【购物车】
 3、花卉博文
3、花卉博文
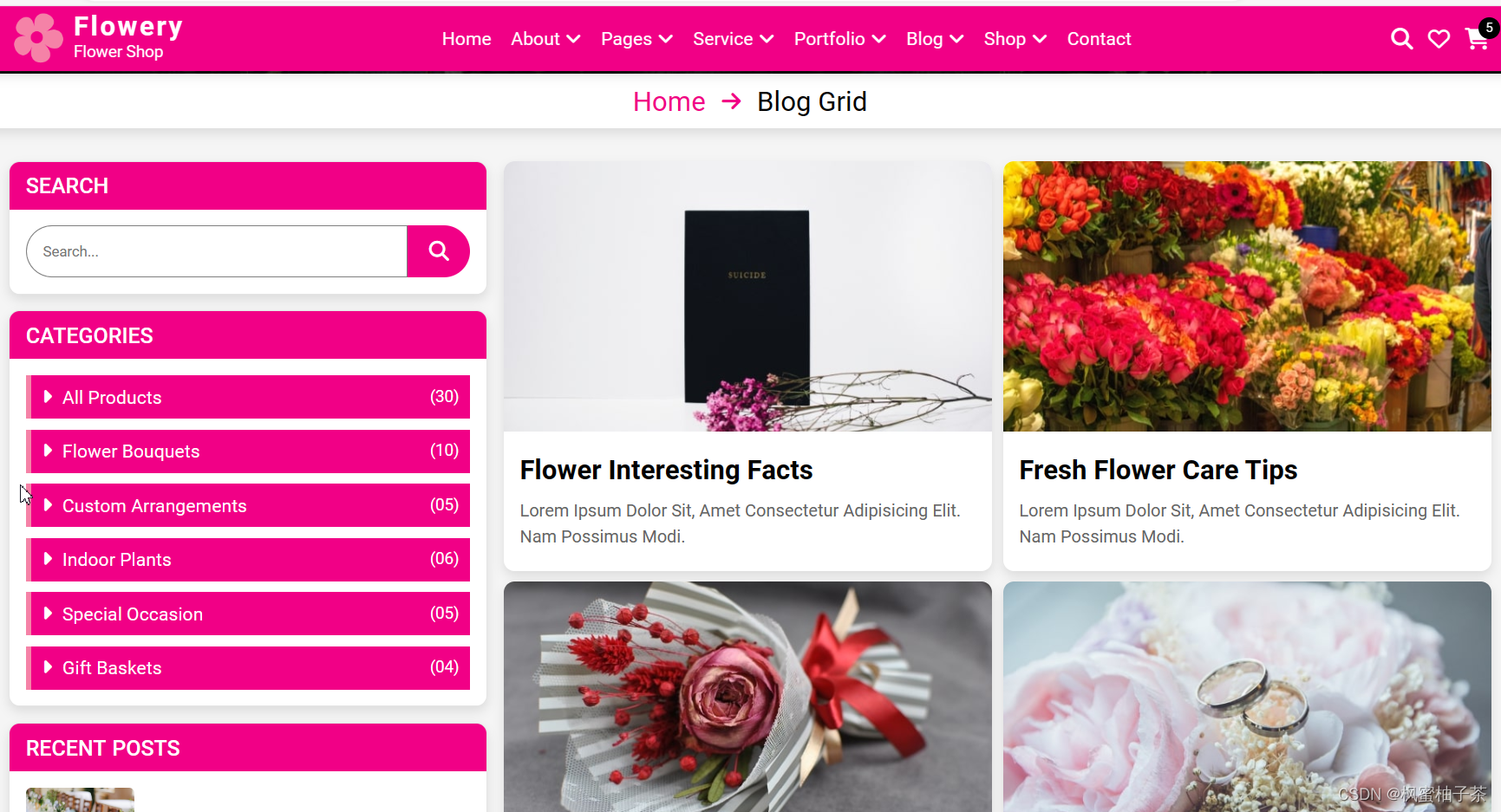
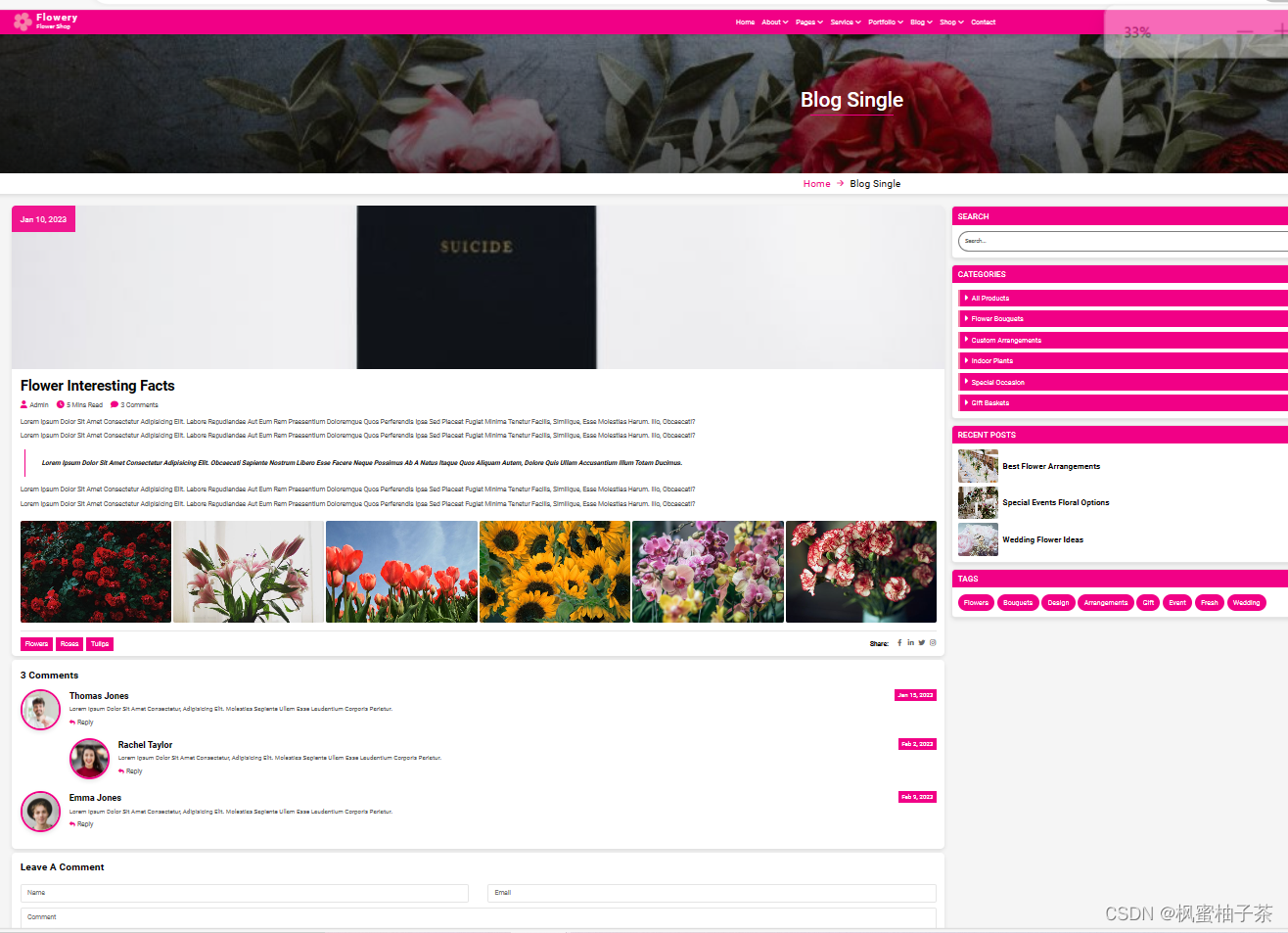
【博文详情】
三、资源获取
html+css+bootstrap实现电商网站源码获取,花卉商城html代码案例flowery.zip资源-CSDN文库