婚恋网站页面设计课后反思
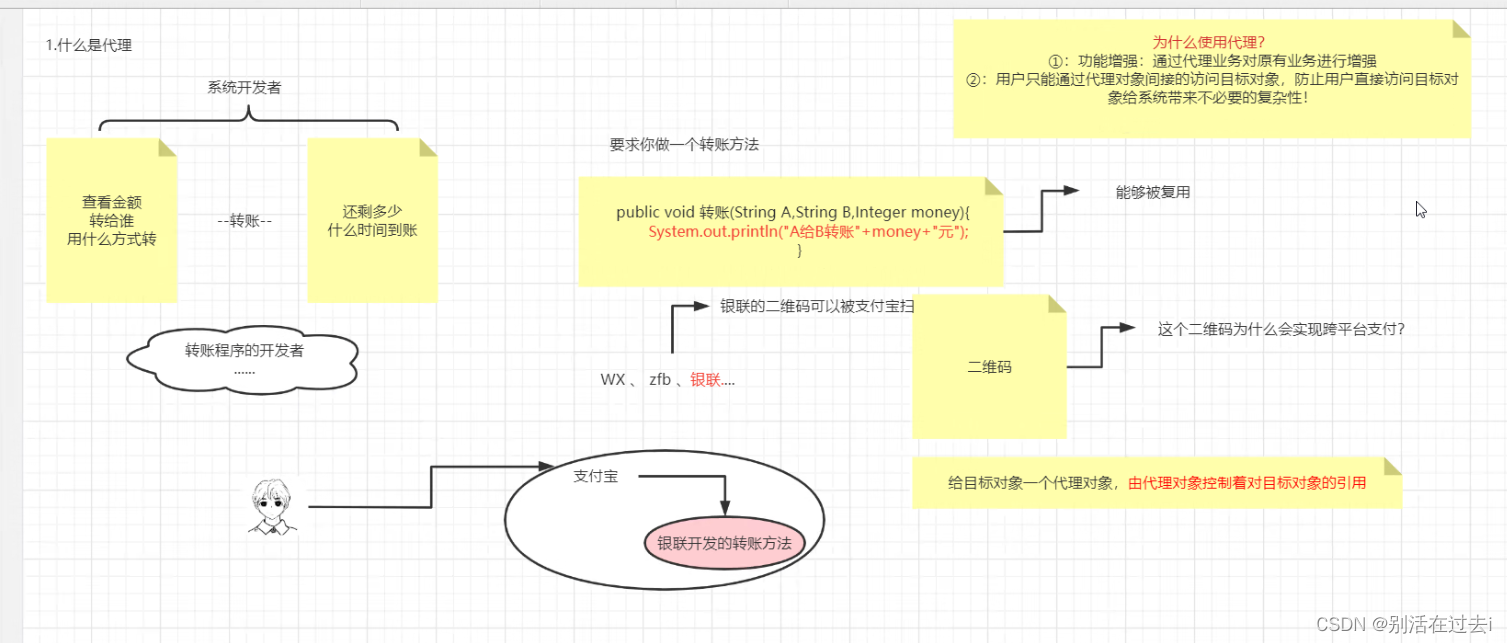
什么是代理:
给目标对象一个代理对象,由代理对象控制着对目标对象的引用
为什么使用代理:
①:功能增强:通过代理业务对原有业务进行增强
②:用户只能同行过代理对象间接访问目标对象,防止用户直接访问目标对象给系统带来不必要的复杂性!
静态代理:
随着我们当中目标类的增多,代理类代理的目标类也会增多....一个代理类生成多个对象。每一个目标对象都是代理着多个目标对象
静态代理相当于是多写了一个代理类,在调用的时候调用的是代理类,在代理类中的处理还是原生的处理逻辑,不过在前后添加上需要添加的代码。
缺点:需要为每一个被代理的对象都创建一个代理类。
静态代理点的问题:
当我们的目标类增多的时候,代理类需要代理的目标类增多,可能会出现代理关闭不便。当我们的目标类进行修改或增多的时候,会影响目标类.....
动态代理:
所谓的动态代理就是生成不同的代理对象每一个 代理对象都代理着自己的目标对象
动态代理一个代理对象只管理一个目标类,比静态代理灵活
Java标准库提供了动态代理功能,允许在运行期动态创建一个接口的实例; 动态代理是通过 Proxy 创建代理对象,然后将接口方法“代理”给 InvocationHandler 完成的。
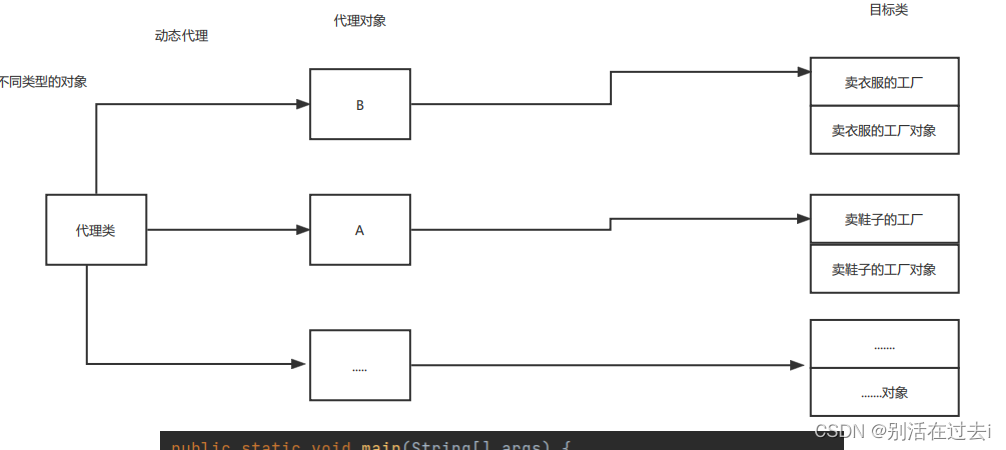
动态代理中将将new目标类对象交给了用户,下面是在main方法里通过接口生成了代理对象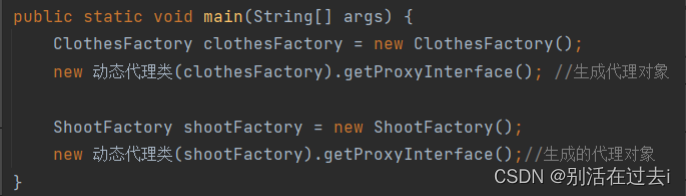
Proxy.newProxylnstance( ,目标接口在这,invocationHandler)给接口生成代理对象
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;// 1.目标类的引用
// 2.调用目标类的核心方法,并实现功能的增强
// 要想调用核心方法,就必须知道核心方法是谁
public class 动态代理类 implements InvocationHandler{// 1.目标类的引用 ----》这种方式灵活private Object factory;public 动态代理类(Object factory){this.factory = factory;}// 要用动态的方式知道我们要调用的核心方法是谁// 核心方法:在目标类实现的接口当中......// 如何找到目标类的接口 -----》 反射public Object getProxyInterface(){return Proxy.newProxyInstance(factory.getClass().getClassLoader(),factory.getClass().getInterfaces(),(InvocationHandler) this);}/*** 如何调用核心方法 -----》 jdk(java的开发者)给我们提供了调用核心方法的接口* @param proxy* @param method 通过反射带来的核心方法* @param args 核心方法的参数* @return* @throws Throwable*/@Overridepublic Object invoke(Object proxy, Method method, Object[] args) throws Throwable {System.out.println("进行前期调研......");method.invoke(factory,args);System.out.println("打包,快递.......");return null;}}
cglib动态代理之前总结过:点击查看
cglib动态代理_别活在过去i的博客-CSDN博客