网站魔板大全公众号 网站开发
使用HTML时,例如,使用<b>标记显示粗体文本。 如果需要列表,则对每个列表项使用<ul>标记及其子标记<li> 。 标签由浏览器解释,并与CSS一起确定网页内容的显示方式以及部分内容的行为。
有时,仅使用一个HTML标记不足以满足Web应用程序所需的功能。 通常,这可以通过将多个HTML标记与JavaScript和CSS结合使用来解决,但是这种解决方案并不是那么优雅。
更为优雅的解决方案是使用自定义标签 - 用<>括起来的标识符,浏览器将其解释为呈现我们预期的功能。 与常规HTML标签一样,我们应该能够在页面中多次使用自定义标签,并且还应该能够具有标签属性和子标签来辅助自定义标签的功能。 所以,让我们看一个例子!
示例:创建Gravatar自定义HTML标签
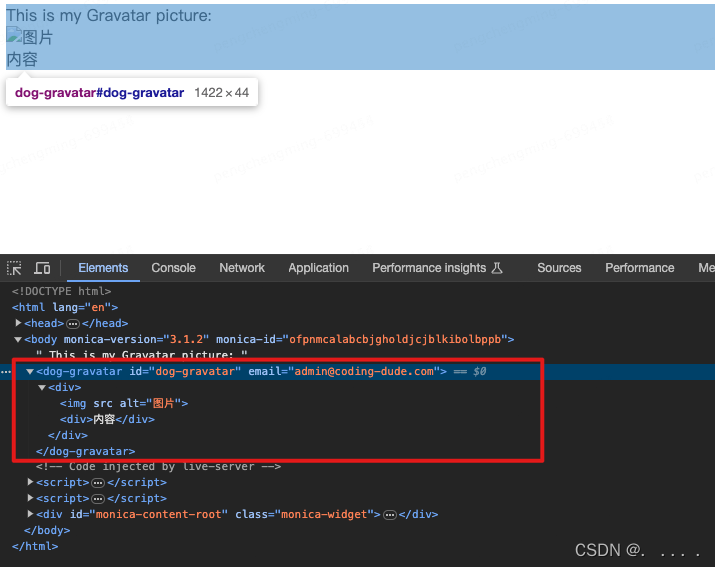
下面是用自定义标签封装了一个HTML片段,使得这个HTML片段更具有语义性,且可以多处复用。
<!DOCTYPE html>
<html lang="en"><head><meta charset="UTF-8" /><meta name="viewport" content="width=device-width, initial-scale=1.0" /><title>Document</title></head><body>This is my Gravatar picture:<dog-gravatar id="dog-gravatar" email="admin@coding-dude.com"><div><img src="" alt="图片"><div>内容</div></div></dog-gravatar></body><script>const dogGravatar = document.querySelector('dog-gravatar');console.log(dogGravatar.getAttribute('email'));</script>
</html>