江西中耀建设集团有限公司网站网站开发推广招聘
本文以安装clickhouse的插件为例,记录下如何离线安装插件
1 下载插件
ClickHouse plugin for Grafana | Grafana Labs
2 找到grafana的配置文件

打开编辑,搜索plugin关键字,修改plugin的加载目录
目录不存在,手动创建,可以找到一个适合的路径
3 重启grafana服务
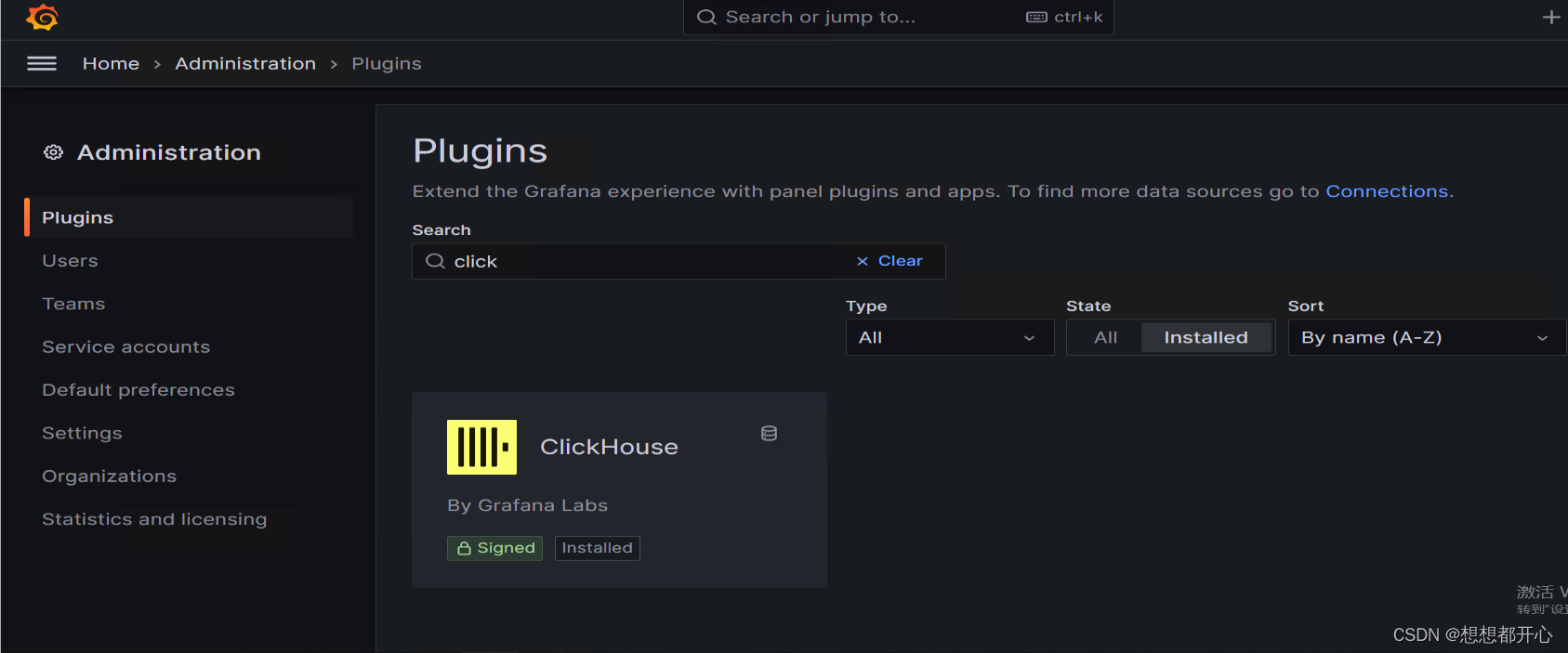
感谢浏览,欢迎指正!
本文以安装clickhouse的插件为例,记录下如何离线安装插件
ClickHouse plugin for Grafana | Grafana Labs
打开编辑,搜索plugin关键字,修改plugin的加载目录
目录不存在,手动创建,可以找到一个适合的路径
感谢浏览,欢迎指正!