如果给公司网站做网络广告公司营业执照注册
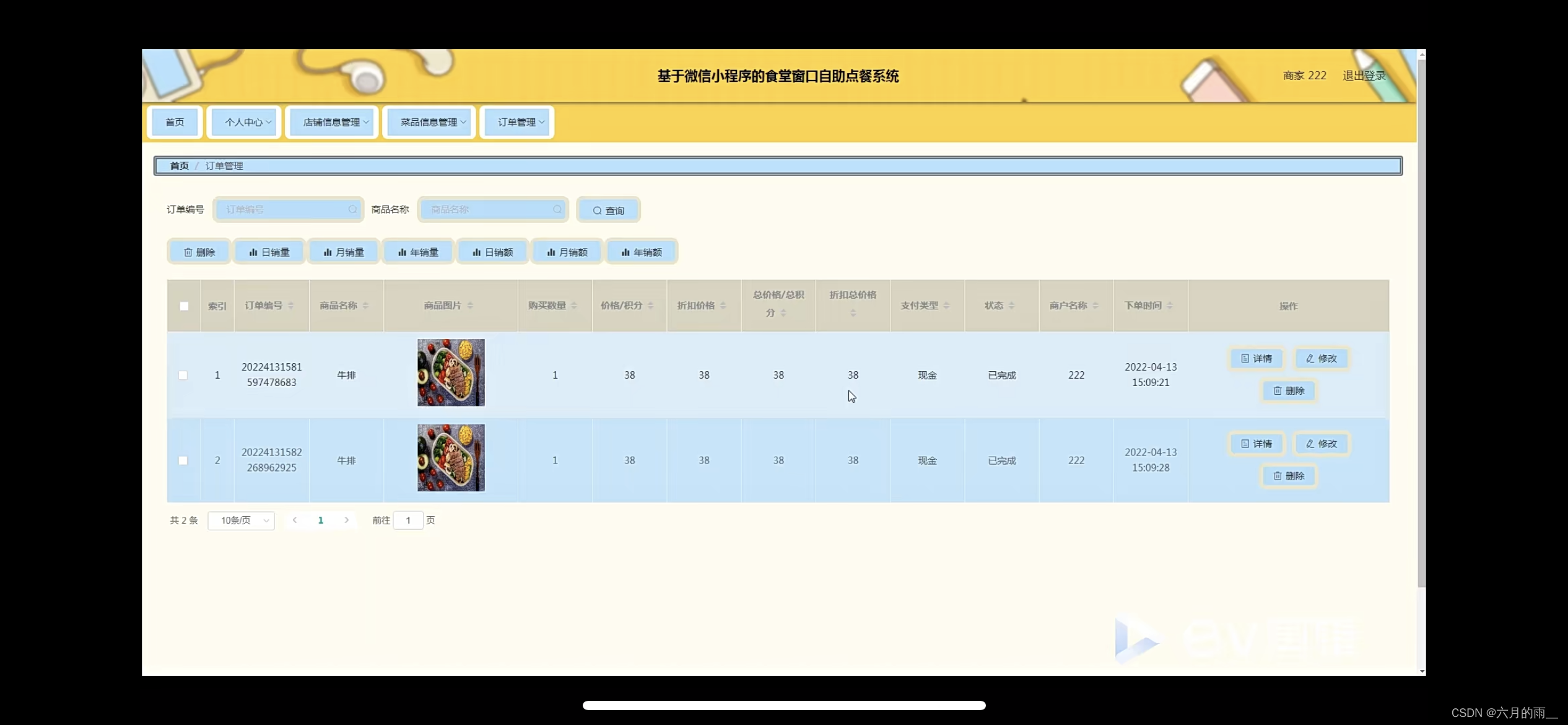
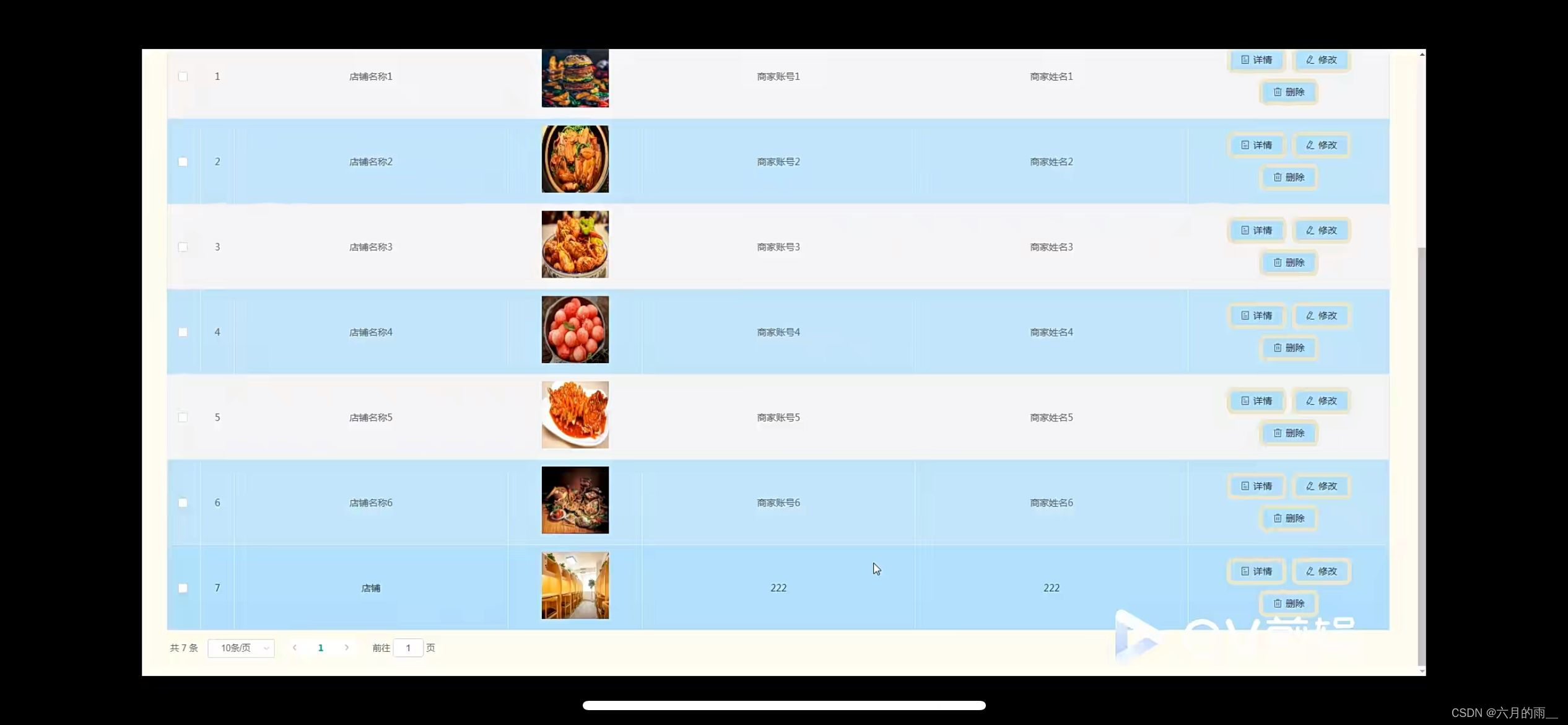
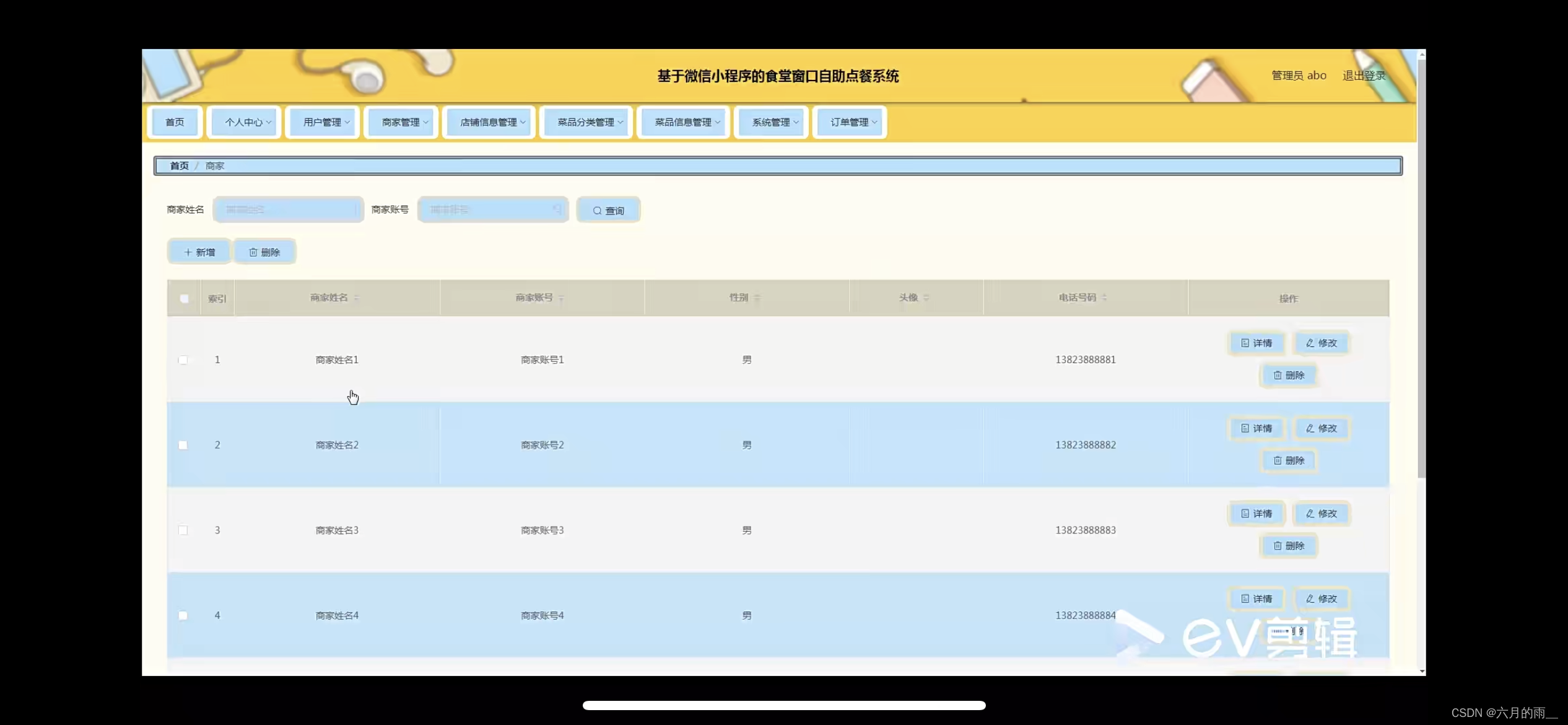
管理员账户功能包括:系统首页,个人中心,用户管理,商家管理,店铺信息管理,菜品分类管理,菜品信息管理,订单管理,系统管理
微信端账号功能包括:系统首页,公告信息,购物车,我的
开发系统:Windows
架构模式:SSM
JDK版本:Java JDK1.8
开发工具:IDEA(推荐)
数据库版本: mysql5.7
数据库可视化工具: navicat
服务器:SpringBoot自带 apache tomcat
主要技术:Java,Spring,mybatis,mysql,jquery,html