盖县网站开发河南省城乡住房建设厅网站首页
1.MySQL数据库的使用演示
1.1创建自己的数据库
命令格式如下(创建的数据库名称不能与已经存在的数据库重名):
mysql> create database 数据库名;
例如:
mysql> create database atguigudb; #创建atguigudb数据库,该名称不能与已经存在的数据库重名。
1.2使用自己的数据库
mysql> use 数据库名;
例如:
mysql> use atguigudb;
说明:如果没有使用use语句,后面针对数据库的操作也没有加“数据名”的限定,那么会报“ERROR 1046(3D000): No database selected”(没有选择数据库)。使用完use语句之后,如果接下来的SQL都是针对一个数据库操作的,那就不用重复use了,如果要针对另一个数据库操作,那么要重新use。
1.3查看某个库的所有表格
mysql> show tables;
或者:
mysql> show tables from 数据库名;
1.4创建新的表格
mysql> create table 表名称(
字段名 数据类型,
字段名 数据类型
);
例如:
#创建学生表
mysql> create table student(
id int,
name varchar(20) #说名字最长不超过20个字符
);
1.5查看一个表的数据
mysql> select * from 数据库表名称
1.6添加一条记录
insert into 表名称 values(值列表);
#添加两条记录到student表中
insert into student values(1,'张三');
insert into student values(2,'李四');
报错:
mysql> insert into student values(1,'张三');
ERROR 1366 (HY000): Incorrect string value: '\xD5\xC5\xC8\xFD' for column 'name' at
row 1
mysql> insert into student values(2,'李四');
ERROR 1366 (HY000): Incorrect string value: '\xC0\xEE\xCB\xC4' for column 'name' at
row 1
mysql> show create table student;
1.7查看表的创建信息
show create table 表名称\G
#查看student表的详细创建信息
show create table student\G
执行结果:
Table: student
Create Table: CREATE TABLE `student` (
`id` int(11) DEFAULT NULL,
`name` varchar(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
上面的结果显示student的表格的默认字符集是“latin1”不支持中文。
修改表格的字符集:
在这里插入代码片
1.8查看数据库的创建信息
show create database 数据库名\G
#查看atguigudb数据库的详细创建信息
show create database atguigudb\G
返回的结果如下:
#结果如下
*************************** 1. row ***************************
Database: atguigudb
Create Database: CREATE DATABASE `atguigudb` /*!40100 DEFAULT CHARACTER SET latin1 */
1 row in set (0.00 sec)
上面的结果显示atguigudb数据库也不支持中文,字符集默认是latin1。
1.9删除表格及数据库
删除表格
drop table 表名称;
#删除学生表
drop table student;
删除数据库
drop database 数据库名;
#删除atguigudb数据库
drop database atguigudb;
注意:delete删除和drop删除的区别,delete删除只是单纯删掉某一张表,drop删除则是将和表所有相关的逻辑关系以及表本身都删除,drop删除更为彻底。
2. MySQL的编码设置
修改mysql的数据目录下的my.ini配置文件
default-character-set=utf8 #默认字符集
[mysqld] # 大概在76行左右,在其下添加
...
character-set-server=utf8
collation-server=utf8_general_ci
步骤3:重启服务
步骤4:查看编码命令
show variables like 'character_%';
show variables like 'collation_%';
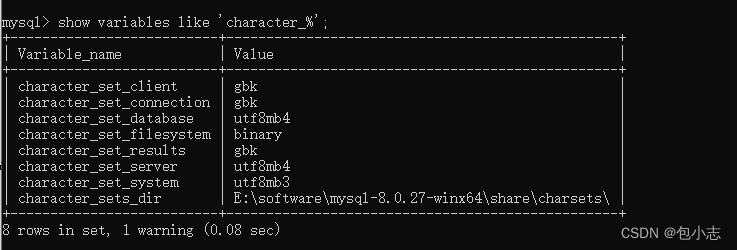

在MySQL 8.0版本之前,默认字符集为latin1,utf8字符集指向的是utf8mb3。从MySQL 8.0
开始,数据库的默认编码改为 utf8mb4 ,从而避免了上述的乱码问题。