网站套模板什么意思网页界面设计调查问卷
植物大战僵尸游戏开发教程专栏地址![]() http://t.csdnimg.cn/ErelL
http://t.csdnimg.cn/ErelL
一、启动方式
鼠标左键单机VS2022上方工具栏中绿色三角按钮(本地Windows调试器)进行项目启动。第一次启动项目需要编译项目中所有代码文件,编译生成需要一定的时间。不同性能的电脑需要消耗的时间差别可能较大,通常在几分钟到几十分钟之间。编译成功后会自动启动运行游戏。
qi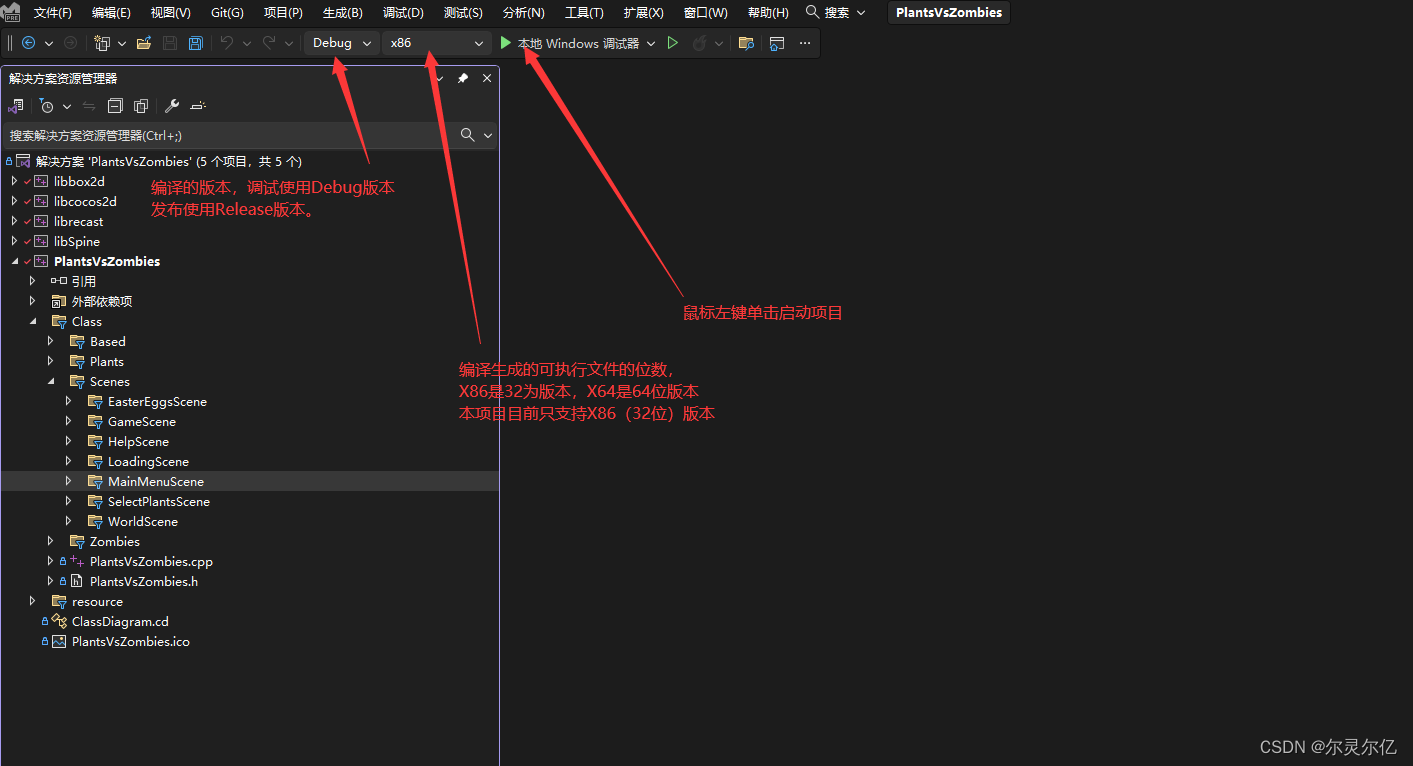
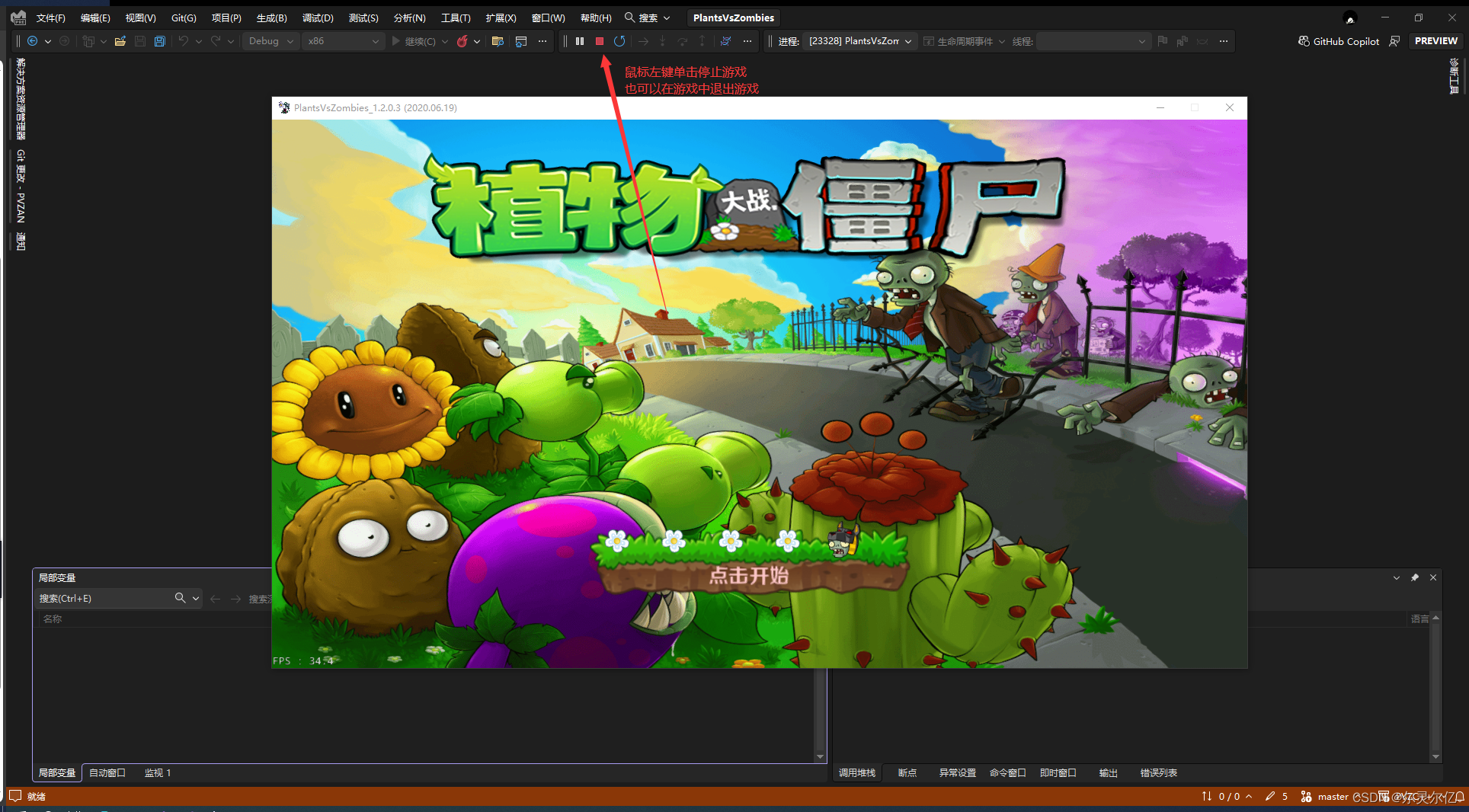
编译成功后自动启动运行游戏如下图。
二、启动流程
1. main函数
首先找到项目的main函数。mian函数在Class文件夹下的PlantsVsZombies.cpp文件中。
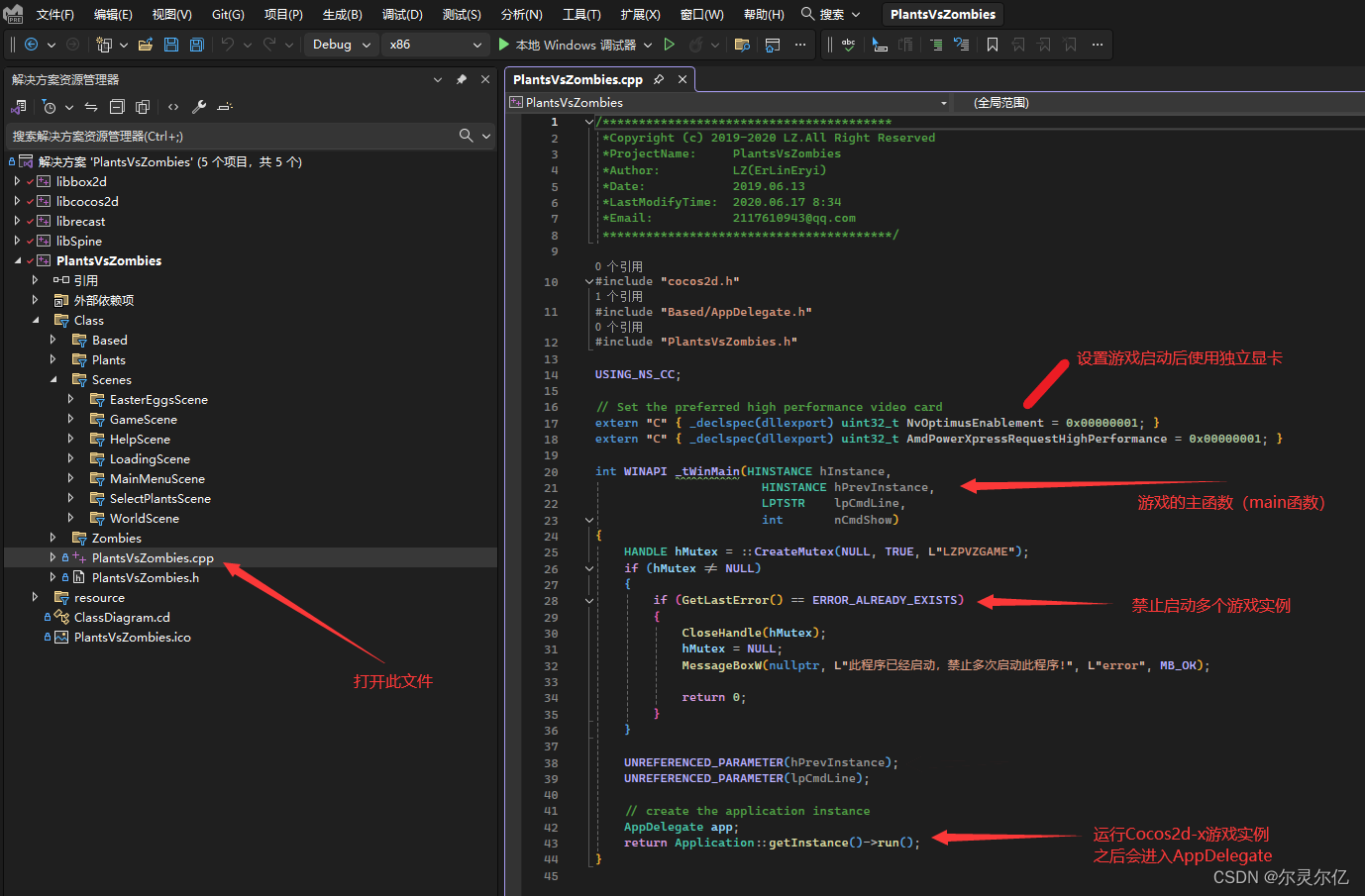
int WINAPI _tWinMain(HINSTANCE hInstance,HINSTANCE hPrevInstance,LPTSTR lpCmdLine,int nCmdShow)
{HANDLE hMutex = ::CreateMutex(NULL, TRUE, L"LZPVZGAME");if (hMutex != NULL){if (GetLastError() == ERROR_ALREADY_EXISTS){CloseHandle(hMutex);hMutex = NULL;MessageBoxW(nullptr, L"此程序已经启动,禁止多次启动此程序!", L"error", MB_OK);return 0;}}UNREFERENCED_PARAMETER(hPrevInstance);UNREFERENCED_PARAMETER(lpCmdLine);// create the application instanceAppDelegate app;return Application::getInstance()->run();
}在Main函数中首先判断进程实例是否已经存在,如果存在则不会创建新的进程。游戏只允许一个进程实例进行运行。例如Windows任务管理器也是只允许一个进程实例。
// create the application instance
AppDelegate app;
return Application::getInstance()->run();2. AppDelegate
这两行代码用于创建启动Cocos2d-x游戏实例。启动之后会进入AppDelegate.cpp文件中的applicationDidFinishLaunching()函数中。
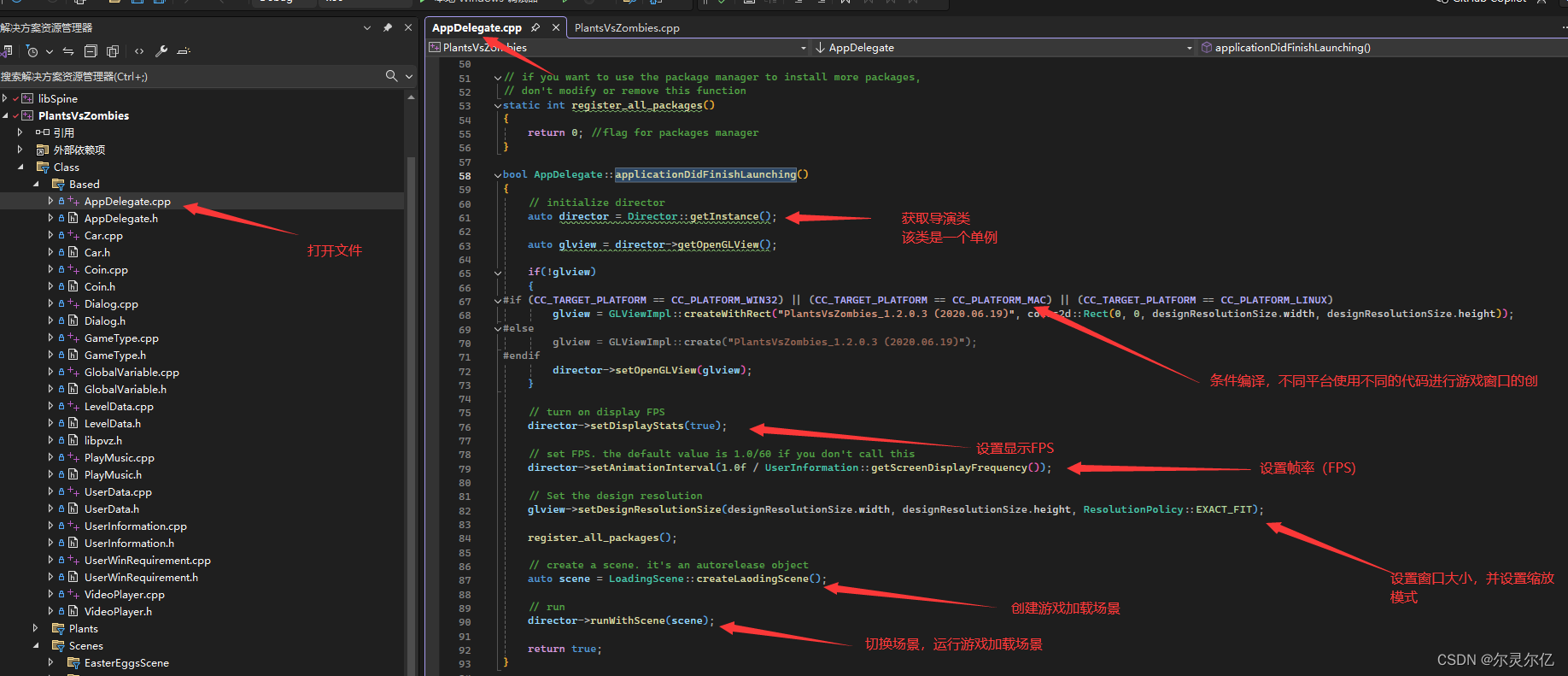
bool AppDelegate::applicationDidFinishLaunching()
{// initialize directorauto director = Director::getInstance();auto glview = director->getOpenGLView();if(!glview){
#if (CC_TARGET_PLATFORM == CC_PLATFORM_WIN32) || (CC_TARGET_PLATFORM == CC_PLATFORM_MAC) || (CC_TARGET_PLATFORM == CC_PLATFORM_LINUX)glview = GLViewImpl::createWithRect("PlantsVsZombies_1.2.0.3 (2020.06.19)", cocos2d::Rect(0, 0, designResolutionSize.width, designResolutionSize.height));
#elseglview = GLViewImpl::create("PlantsVsZombies_1.2.0.3 (2020.06.19)");
#endifdirector->setOpenGLView(glview);}// turn on display FPSdirector->setDisplayStats(true);// set FPS. the default value is 1.0/60 if you don't call thisdirector->setAnimationInterval(1.0f / UserInformation::getScreenDisplayFrequency());// Set the design resolutionglview->setDesignResolutionSize(designResolutionSize.width, designResolutionSize.height, ResolutionPolicy::EXACT_FIT);register_all_packages();// create a scene. it's an autorelease objectauto scene = LoadingScene::createLaodingScene();// rundirector->runWithScene(scene);return true;
}在applicationDidFinishLaunching()函数中创建了游戏窗口,设置游戏运行帧率,最后切换场景进入游戏加载场景。
3. LaodingScene
在游戏加载场景中会进入init函数中。在init函数会进行游戏版本检查,检测游戏是否有更新,如果有更新,则会进入游戏更新场景。然后计算文件总数,设置系统参数,以及加载游戏文件同时展示加载动画。游戏文件加载是异步操作,会启动一个新的线程进行文件加载,否则游戏加载时界面就不能展示动画,动画会卡住,直到文件加载完成。
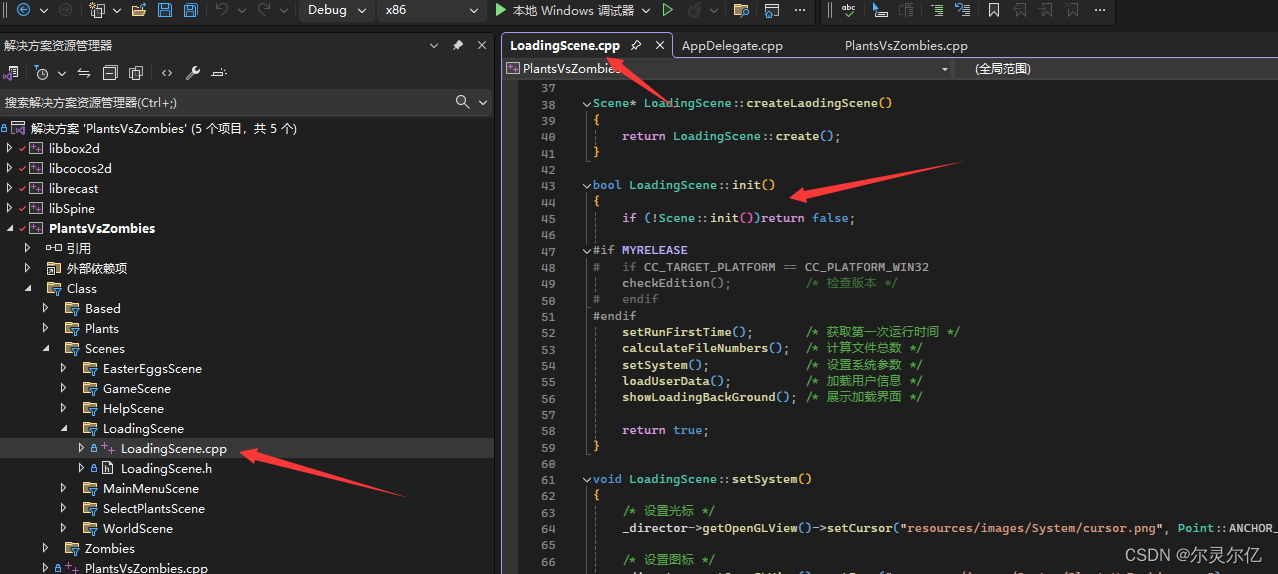
当所有文件加载完成后进入游戏按钮就会设置为可点击状态。点击后进入游戏主界面场景。
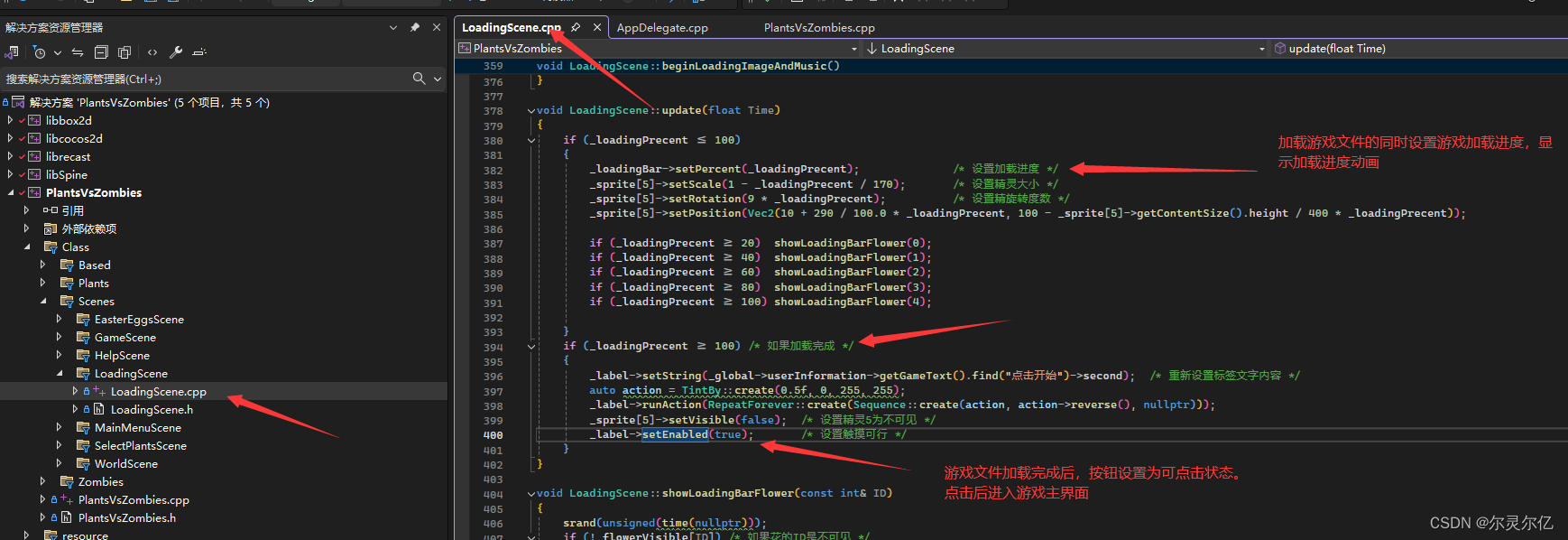
点击开始游戏按钮,触发回调函数,进入游戏主界面。同样的然后会调用主界面场景的init函数来创建游戏主场景。
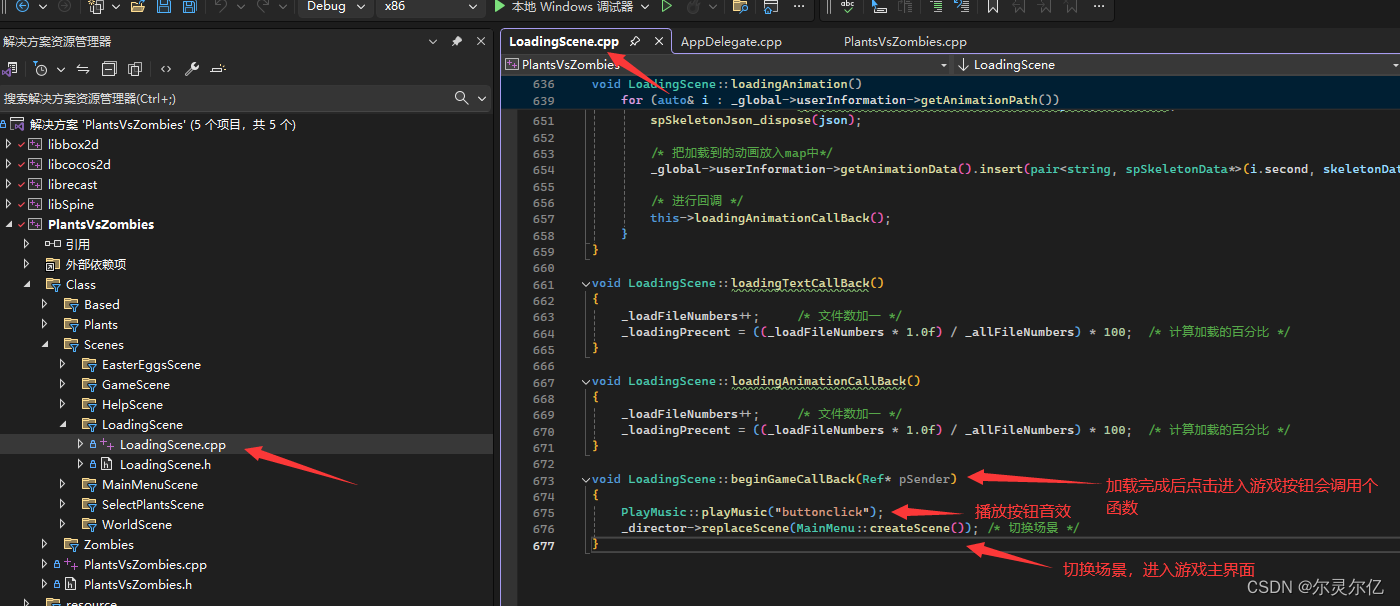
至此,从主函数开始,到游戏加载完成进入游戏主界面的流程大概讲解完成。
三、后续
下一篇会详细讲解游戏文件加载场景中的细节。LoadScene.h和LoadingScene.cpp中详细的代码执行流程以及每个函数的作用。