弹幕网站是什么技术做的合肥制作网页设计
前言
很多新手会觉得前端很难,但其实前端很简单,你知道了前端的写法套路就会变得很easy,本篇教大家最快上手前端,结合我上篇的内容一起看
因为是给新手看的,所以后面会附上代码用过全部的知识点,先给大家看看效果图
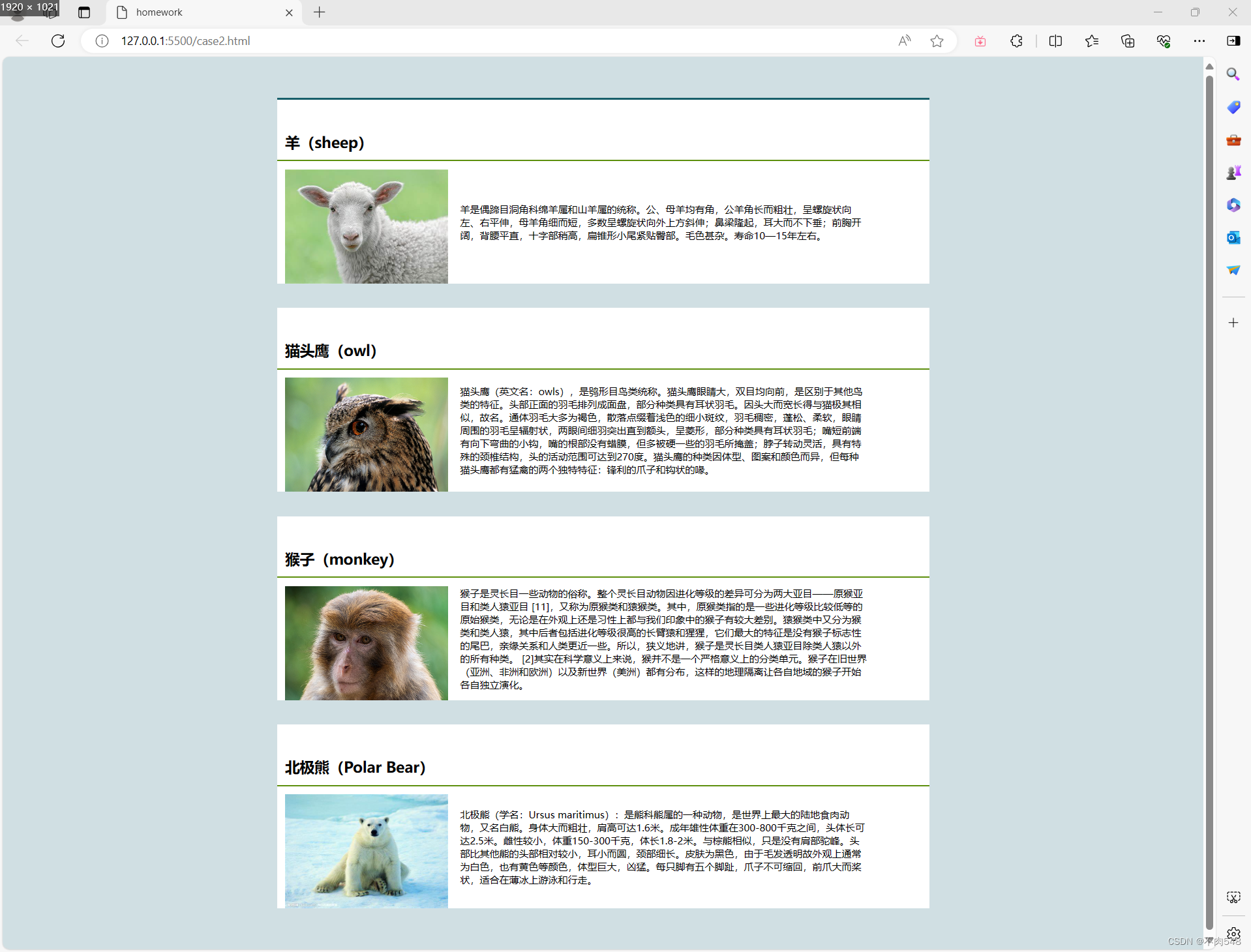
前端演示结果可在另一个文章里看视频
页面效果
本页面可实现页面跳转,标题点击前是黑色,鼠标移上去时粉紫色,长按是灰色,点击之后返回后标题变绿色。
页面源码
话不多说,直接上代码:
<!doctype html>
<html><head><meta charset="utf-8"><meta name="keywords" content="商品展示"><meta name="discription" content="展示页面"><meta name="viewport" content="width=device-width,initital-scale=100"><title>homework</title><style>* {margin: 0;padding: 0;}body {background-color: rgb(208, 223, 227);}ul {list-style: none; /*清楚默认指示器样式*/margin: 50px auto;}.one {border-top: 3px solid rgb(24, 95, 106);}li {width: 800px;background-color: white;margin: 30px auto;}img {display: inline-block;width: 200px;height: 140px;padding-top: 10px;}a {text-decoration: none;color: black;}a:visited {color: chartreuse;}a:hover {color: rgb(203, 68, 122);}a:active {color: darkgray;}.title {font-size: 18px;font-weight: 600;padding: 40px 10px 10px;border-bottom: 2px solid rgb(93, 143, 13);}p {width: 500px;margin: 10px auto;}.desc {display: inline-block;font-size: 12px;color: black;padding-left: 10px;vertical-align: middle;}</style></head><body><ul><li class="one"><h3 class="title"><a href="https://baike.baidu.com/item/%E7%BE%8A/1947" alt="sheep" target='_blank'>羊(sheep)</a></h3><img class="desc" src="img/sheep.jpe" alt="羊(sheep)" width="474" height="316"><p class="desc">羊是偶蹄目洞角科绵羊属和山羊属的统称。公、母羊均有角,公羊角长而粗壮,呈螺旋状向左、右平伸,母羊角细而短,多数呈螺旋状向外上方斜伸;鼻梁隆起,耳大而不下垂;前胸开阔,背腰平直,十字部稍高,扁锥形小尾紧贴臀部。毛色甚杂。寿命10—15年左右。</p></li><li><h3 class="title"><a href="https://baike.baidu.com/item/%E7%8C%AB%E5%A4%B4%E9%B9%B0/74037" alt="owl" target='_blank'>猫头鹰(owl)</a></h3><img class="desc" src="img/猫头鹰.jpg" alt="猫头鹰(owl)" width="860" height="573"><p class="desc">猫头鹰(英文名:owls),是鸮形目鸟类统称。猫头鹰眼睛大,双目均向前,是区别于其他鸟类的特征。头部正面的羽毛排列成面盘,部分种类具有耳状羽毛。因头大而宽长得与猫极其相似,故名。通体羽毛大多为褐色,散落点缀着浅色的细小斑纹,羽毛稠密,蓬松、柔软,眼睛周围的羽毛呈辐射状,两眼间细羽突出直到额头,呈菱形,部分种类具有耳状羽毛;嘴短前端有向下弯曲的小钩,嘴的根部没有蜡膜,但多被硬一些的羽毛所掩盖;脖子转动灵活,具有特殊的颈椎结构,头的活动范围可达到270度。猫头鹰的种类因体型、图案和颜色而异,但每种猫头鹰都有猛禽的两个独特特征:锋利的爪子和钩状的喙。</p></li><li><h3 class="title"><a href="https://baike.baidu.com/item/%E7%8C%B4%E5%AD%90/1593453" alt="monkey" target='_blank'>猴子(monkey)</a></h3><img class="desc" src="img/monkey.jpe" alt="猴子(monkey)" width="450" height="300"><p class="desc">猴子是灵长目一些动物的俗称。整个灵长目动物因进化等级的差异可分为两大亚目——原猴亚目和类人猿亚目 [11],又称为原猴类和猿猴类。其中,原猴类指的是一些进化等级比较低等的原始猴类,无论是在外观上还是习性上都与我们印象中的猴子有较大差别。猿猴类中又分为猴类和类人猿,其中后者包括进化等级很高的长臂猿和猩猩,它们最大的特征是没有猴子标志性的尾巴,亲缘关系和人类更近一些。所以,狭义地讲,猴子是灵长目类人猿亚目除类人猿以外的所有种类。 [2]其实在科学意义上来说,猴并不是一个严格意义上的分类单元。猴子在旧世界(亚洲、非洲和欧洲)以及新世界(美洲)都有分布,这样的地理隔离让各自地域的猴子开始各自独立演化。</p></li><li><h3 class="title"><a href="https://baike.baidu.com/item/%E5%8C%97%E6%9E%81%E7%86%8A/48826" alt="北极熊(Polar)" target='_blank'>北极熊(Polar Bear)</a></h3><img class="desc" src="img/bear.jpe" alt="北极熊(Polar)" width="474" height="355"><p class="desc">北极熊(学名:Ursus maritimus):是熊科熊属的一种动物,是世界上最大的陆地食肉动物,又名白熊。身体大而粗壮,肩高可达1.6米。成年雄性体重在300-800千克之间,头体长可达2.5米。雌性较小,体重150-300千克,体长1.8-2米。与棕熊相似,只是没有肩部驼峰。头部比其他熊的头部相对较小,耳小而圆,颈部细长。皮肤为黑色,由于毛发透明故外观上通常为白色,也有黄色等颜色,体型巨大,凶猛。每只脚有五个脚趾,爪子不可缩回,前爪大而桨状,适合在薄冰上游泳和行走。</p></li></ul></body>
</html>代码涉及的知识点
1.首先是代码的整体框架加三要素:标题title,关键字keywords,简介描述description
2.在body里写代码整体结构,用到的标签如下:
<p> 段落标签 a 超链接标签 href 跳转目标地址
列表
无序列表:ul/li ->嵌套使用 li中可以放其他标签
3.接下来对内容进行css装饰
类选择器
.类名{属性1:属性值1;属性2:属性值2;}
标签调用时用class=“类名” 即可
id选择器(唯一)
#类名{属性1:属性值1;属性2:属性值2;}
用法和类选择器相同
两者区别:最大的不同在于使用次数上
通配符选择器
* {属性1:属性值1;属性2:属性值2;}
能匹配到页面中所有的元素
多类名选择器
class中加多个属性,并在head标签中定义
基础字体样式
开头空两格:text-indent:2em; em:相对于当前对象内文本的字体大小(font-size)尺寸
颜色设置:color:颜色英文;
字体大小:font-size:18px; (普遍使用14px+,一般都为偶数)
字体粗细:font-weight:bold;(100~900,400相当于normal,700等价于bold,一定要是100的整数倍)
字体样式:font-family:”宋体“(尽量转化为Unicode编码来写,转换后去掉u)
字体风格:font-style:normal;(normal:默认值;italic:斜体;oblique:倾斜字体)
font:综合设置字体样式
选择器{font:font-style font-weight font-size/line-height font-family;}
使用font属性时,必须按照上面的语法格式顺序书写,不能更换顺序,各个属性以空格隔开。
注意:其中不需要的属性可以省略(取默认值),但必须保留font-size和font-family属性,否则font属性将不起作用
color:文本颜色
1.英文颜色
2.十六进制,如#FF0000(最常用)
取色技巧:qq截屏用鼠标对着想要取的颜色,按ctrl,然后按c就可以复制颜色色号
常见颜色:#000000 纯黑 #FFFFFF 纯白 #FF0000 纯红 #00FF00 纯绿 #0000FF 纯蓝
注意:#AABBCC类颜色可以简写为#ABC
3.RGB代码,如红色可以表示为rgb(255,0,0)或rgb(100%,0%,0%)
rgba( , , , )最后一位为透明度,范围在0~1之间
注意:如果使用RGB代码的百分比颜色值,取值为0时也不能省略百分号
line-height:行间距
属性值单位:像素px,相对值em,百分比%(基于当前标签的字体大小,默认字体大小为16px)
一般情况下,行距比字号大7,8像素左右(凑偶数)
text-align:水平对齐方式
left:左对齐;right:右对齐;center:居中
text-indent:首行缩进
1em就是一个字的宽度,如果是汉字的段落,1em就是一个汉字的宽度
text-decoration:文本的装饰
通常用于给链接修改装饰效果
none:默认。定义标准的文本
underline:定义文本下的一条线,下划线,也就是链接自带的
overline:定义文本上的一条线
line-through:定义穿过文本下的一条线
a标签居中方式:设置它的上一级标签居中
链接伪类选择器
-
:link 未访问的链接
-
:visited 已访问的链接
-
:hover 鼠标移动到链接上
-
:active 选定的链接(鼠标按住的时候)
注意:写的时候,顺序尽量不要颠倒,按照lvha的顺序
总结
前端也是需要多练多写,最快的记忆方式就是敲代码,后面我会总结前端的笔记发出来方便大家学习,下期再见。