河南建设集团网站研艺影楼网站建设
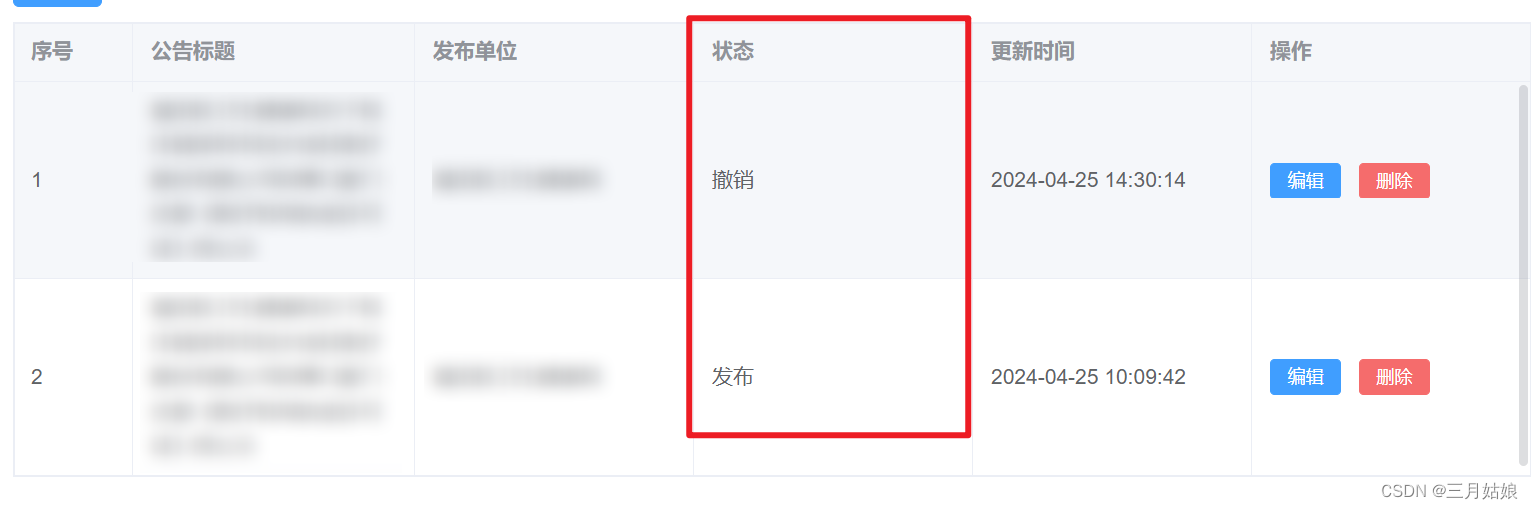
问题:后端返回的字段为数字

解决办法:
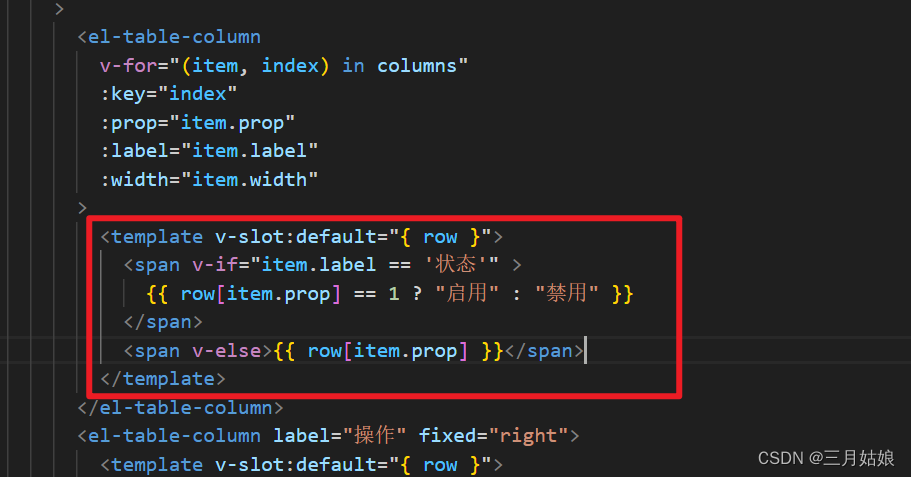
最终果:

另外:如果多种状态时可用函数
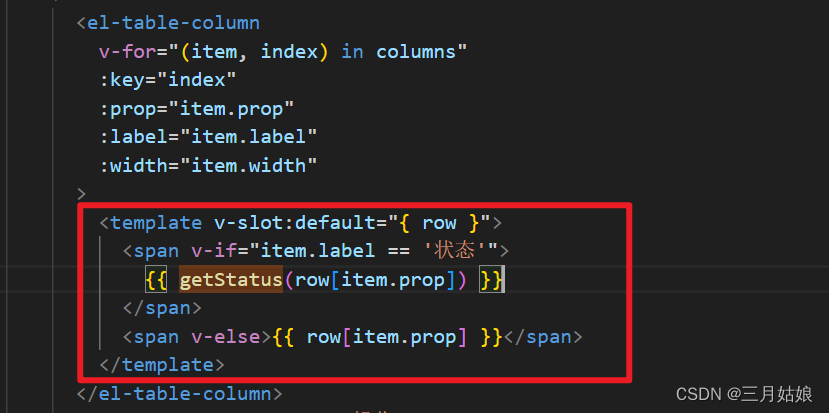
{{ getStatus(row[item.prop]) }}
{{ row[item.prop] }}
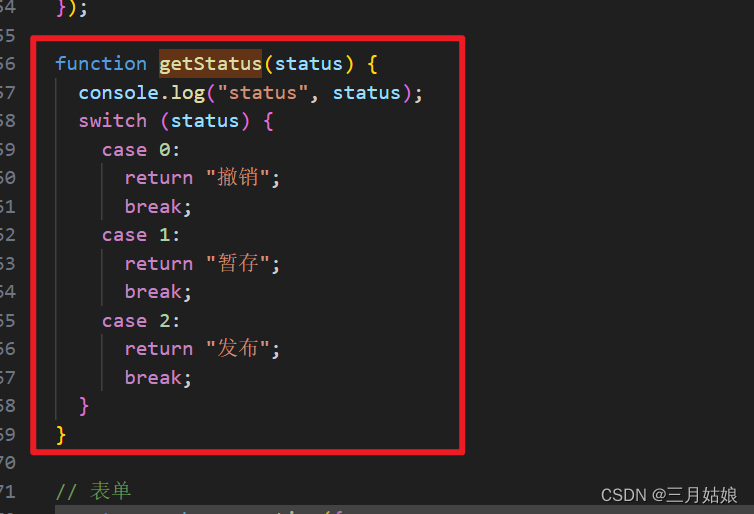
function getStatus(status) {
console.log(“status”, status);
switch (status) {
case 0:
return “撤销”;
break;
case 1:
return “暂存”;
break;
case 2:
return “发布”;
break;
}
}
最终效果: