深圳服装网站建设制作开发动漫制作专业学什么课程
一、背景
在选择一款比较合适的中台的情况下,挑选了有arco design、ant design pro、soybean、vue-pure-admin等中台系统,经过筛选就选择了ant design pro。之前使用过arco design 搭建通过组件库拼装过后台管理界面,官方文档也比较全,但是想着再尝试其他的框架,于是就没继续使用arco design组件库了,而选择尝试ant design pro中台。
二、准备环境
技术栈
前端
Node.js 18.16.1
node版本管理 nvm 1.1.12
框架 Ant Design Pro 6.0.0
组件库 procomponents 5
ant-design 5.12.5
fetch
路由 Router 6
版本查看:
⚡keney ❯❯ nvm -v
1.1.12
⚡keney ❯❯ nvm list* 18.16.1 (Currently using 64-bit executable)16.15.0 ⚡keney ❯❯ node -v
v18.16.1 ⚡keney ❯❯ npm -v
9.5.1
nvm、node安装教程这里就不展示了
nvm安装教程:
https://blog.csdn.net/m0_54345753/article/details/131653960
https://blog.csdn.net/HuangsTing/article/details/113857145
https://blog.csdn.net/qq_22182989/article/details/125387145
node下载地址:
https://nodejs.org/dist/v13.13.0/
node安装教程:
https://blog.csdn.net/WHF__/article/details/129362462
# 配置node镜像:
node_mirror: https://npmmirror.com/mirrors/node/
# 配置npm镜像:
npm_mirror: https://npmmirror.com/mirrors/npm/
三、项目介绍
3.1 项目结构
|-- fun-bill-front
| |-- public # 静态资源
| | |-- favicon.ico # 图标
| |-- config # 配置文件
| |-- routes.ts #路由
| |-- proxy.ts # 本地代理配置
| |-- oneapi.json # 类似swagger接口文档
| |-- defaultSettings.ts # 主题默认配置
| `-- config.ts # 配置
| |-- src # 源码
| | |-- .umi # umi配置
| | |-- components # 组件
| | |-- constant # 常量
| | |-- locales # 国际化
| | |-- pages # 页面
| | |-- services # 请求
| | |-- utils # 工具
| | |-- access.ts # 权限
| | |-- app.tsx # 入口
| | |-- global.less # 全局样式
| | |-- global.tsx # 全局
| | |-- manifest.json # pwa
| | |-- requestErrorConfig.ts # 请求错误配置
| | |-- serviceWorker.ts # pwa
| | `-- types.d.ts # 类型
| |-- tests # 测试
| |-- types # 类型
| |-- .editorconfig # 编辑器配置
| |-- .env # 环境变量
| |-- .eslintrc # eslint配置
| |-- .gitignore # git忽略
| |-- .prettierignore # prettier忽略
| |-- .prettierrc # prettier配置
| |-- jest.config.js # jest配置
| |-- jsconfig.json # js配置
| |-- LICENSE # 许可证
| |-- package.json # 包管理
| |-- README.md # 说明四、项目创建和启动
UmiJS文档:
https://umijs.org/docs/guides/getting-startedant design pro
https://pro.ant.design/zh-CN ant
design pro组件库:
https://procomponents.ant.design/
注意:在阅读这篇教程,建议先通读ant design pro官方文档,跟着官方文档搭建,然后再看这篇教程文档,会更好理解。
创建项目教程可以参考这篇 ant design pro 6.0搭建教程:
https://blog.csdn.net/nxg0916/article/details/139200391
1、安装和启动
1.1 使用 npm安装全局依赖,并创建ant design pro中台模板
npm i @ant-design/pro-cli -g
npx pro create myapp
1.2 选择 umi@4
? 🐂 使用 umi@4 还是 umi@3 ? (Use arrow keys)
❯ umi@4umi@3
1.3 安装依赖:
进入到刚刚创建的模板文件夹下,并执行npm install命令安装依赖
$ cd myapp && tyarn
// 或
$ cd myapp && npm install
npm 命令的使用需要配置好国内镜像,这一步在安装node就配置好了,这里就不在赘述了。
1.4 项目启动:
npm run start
这个命令是预览mock功能
为什么使用 nmp run dev命令,可以从 package.json中找到
对接后端接口,就需要配置后端接口地址
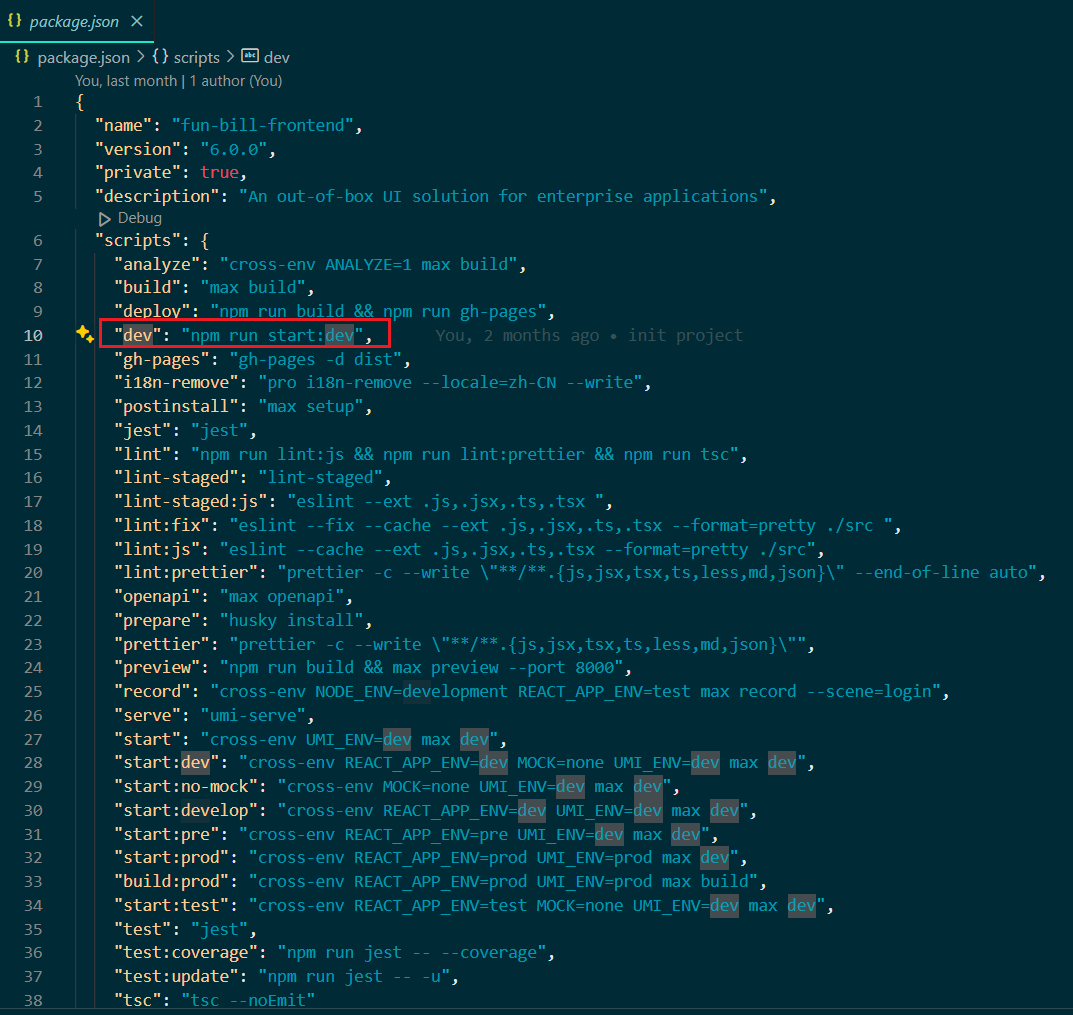
这里本地调试就可以使用一下命令启动(开发环境)
npm run start:dev
停止运行就直接按Ctrl+C
本地构建部署详情,请看附件部分
2、访问
http://localhost:8000/
五、功能介绍
对接后台接口服务,也就是前后端分离的项目的时候
列表使用案例:参考另外一篇文章,或者参考:
后台:
https://github.com/imnxg/shixunapp
后台接口服务:
https://github.com/imnxg/shixunapp-backend
其他案例:
https://github.com/imnxg/RentalManagement
5.1 本地开发代理配置
先修改配置 config\proxy.ts 代理
// 如果需要自定义本地开发服务器 请取消注释按需调整dev: {// localhost:8000/api/** -> https://preview.pro.ant.design/api/**'/api/': {// 要代理的地址,本地后端接口地址target: 'http://localhost:8091',// 配置了这个可以从 http 代理到 https// 依赖 origin 的功能可能需要这个,比如 cookiechangeOrigin: true,},},
例如:
后端登录接口:localhost:8091/api/login/account
在src\services\login\loginApi.ts配置接口
/** 登录接口 POST /api/login/account */
export async function login(body: LOGINAPI.LoginParams, options?: { [key: string]: any }) {return request<LOGINAPI.LoginResult>('/api/login/account', {method: 'POST',headers: {'Content-Type': 'application/json',},data: body,...(options || {}),});
}
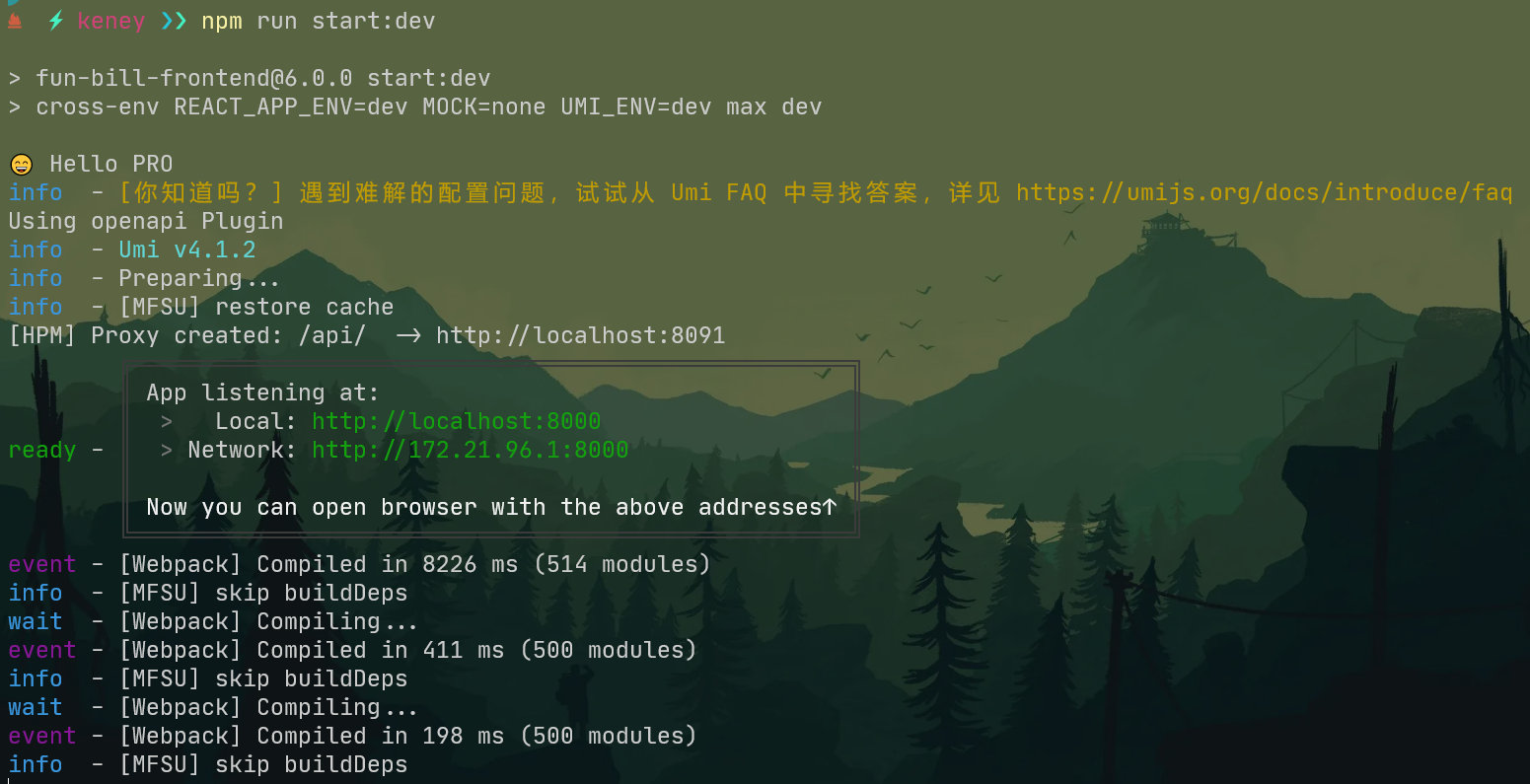
配置了代理后,运行 npm run start:dev 效果如下:
5.2 菜单权限
src\access.ts
/*** @see https://umijs.org/docs/max/access#access* */
export default function access(initialState: { currentUser?: API.CurrentUser } | undefined) {const { currentUser } = initialState ?? {};return {canAdmin: currentUser && currentUser.user?.admin,canUser: currentUser && currentUser.user?.admin,};
}
不同角色访问菜单的权限不同
路由配置:
config\routes.ts
{path: '/admin',name: 'admin',icon: 'crown',access: 'canAdmin', //只有用户有 canAdmin 权限的才能访问该菜单routes: [{path: '/admin',redirect: '/admin/sub-page',},{path: '/admin/sub-page',name: 'sub-page',component: './Admin',},],},{name: 'list.table-list',icon: 'table',path: '/list',component: './User/UserManager',},
5.3. 服务请求
给每个请求地址加上token
/*** requestInterceptors 接收一个数组,数组的每一项为一个 request 拦截器。等同于 umi-request 的 request.interceptors.request.use() 。*/
const authHeaderInterceptor = (url: string, options: RequestConfig) => {//console.log('authHeaderInterceptor url, options: ', url, options );//console.log('url.indexOf: ',url.indexOf('/login/') +",", url.indexOf('/login/account'));// 如果是登录页面,不需要添加tokenif (url.indexOf('/login/account') !== -1 || url.indexOf('/login/logout') !== -1 || url.indexOf('/register') !== -1) {return {url: `${url}`,options: { ...options, interceptors: true },};} else {const token = getToken();// console.log('url, token: ', url, token);let authHeader = {};// 如果token存在,就添加到请求头if (token) {authHeader = { Authorization: `Bearer ${token}` };}return {url: `${url}`,options: { ...options, interceptors: true, headers: authHeader },};}
};/*** @name request 配置,可以配置错误处理* 它基于 axios 和 ahooks 的 useRequest 提供了一套统一的网络请求和错误处理方案。* @doc https://umijs.org/docs/max/request#配置*/
export const request: RequestConfig = {...errorConfig,// 新增自动添加AccessToken的请求前拦截器// requestInterceptors: [demoResponseInterceptors],// 新增自动添加AccessToken的请求前拦截器requestInterceptors: [authHeaderInterceptor],// baseURL: 'https://xxx.xx.top/',
};
注意:使用这token原因:后台接口有token校验,需要在每个请求同时带上Authorization 对应的token,才能校验通过。
否则无法调用后端接口。
附件
项目启动扩展
package.json文件:
# 启动不使用本地模拟数据"start:no-mock": "cross-env MOCK=none UMI_ENV=dev max dev",# 开发环境,即配置了后台接口地址"start:develop": "cross-env REACT_APP_ENV=dev UMI_ENV=dev max dev",# 预生产环境,可配置也不配置"start:pre": "cross-env REACT_APP_ENV=pre UMI_ENV=dev max dev",# 生产环境本地调用生产环境接口"start:prod": "cross-env REACT_APP_ENV=prod UMI_ENV=prod max dev",# 生产环境(正式环境),将配置好的后端接口一同打包"build:prod": "cross-env REACT_APP_ENV=prod UMI_ENV=prod max build",
启动和构建命令大致就是这样:
# 启动不使用本地模拟数据npm run start:no-mock# 开发环境,即配置了后台接口地址npm run start:develop# 预生产环境,可配置也不配置npm run start:pre# 生产环境本地调用生产环境接口npm run start:prod# 生产环境(正式环境),将配置好的后端接口一同打包npm run build:prod
请求加token和配置生产环境
注意:
本地开发调试时,先注释 /src/app.tsx下
/*** @name request 配置,可以配置错误处理* 它基于 axios 和 ahooks 的 useRequest 提供了一套统一的网络请求和错误处理方案。* @doc https://umijs.org/docs/max/request#配置*/
export const request: RequestConfig = {...errorConfig,// 新增自动添加AccessToken的请求前拦截器// requestInterceptors: [demoResponseInterceptors],// 新增自动添加AccessToken的请求前拦截器requestInterceptors: [authHeaderInterceptor],// baseURL: 'https://in.xxx.top/',
};
本地开发的时候注释掉 baseURL,这里默认的模版没有,我们需要添加才会有。
当你需要打包到生产环境,即上线,那就需要配置你的后台接口地址,并取消注释:
baseURL: 'https://in.xxx.top/',
生产环境
npm run build
# 或者 包括本地配置的生产地址也一同打包
npm run build:prod
使用echar图
在package.json中增加
"@ant-design/charts": "^2.0.3",
或者去官方文档查看相关的添加命令
参考资料
测试文档ant design pro v6
https://beta-pro.ant.design/docs/request-cn#%E8%AF%B7%E6%B1%82%E5%89%8D%E6%8B%A6%E6%88%AA%EF%BC%9Arequestinterceptors
参考:https://zhuanlan.zhihu.com/p/648178323
Ant Design Pro v5
https://www.zhihu.com/people/song-bo-73-14/zvideos?page=7
ant design pro v6设置 token学习:
https://www.bilibili.com/video/BV1bK41197eX/?vd_source=83e20cd531608ce070908ea29997e648
参考:https://www.5axxw.com/questions/simple/yqzki6