企业网站推广免费建网站那个好
本教程选取与参考书籍《PostgreSql11 从入门到精通》(清华大学出版社)的11大版本最新小版本11.22的安装作为教程案例
下载
下载PostgreSQL installer

下载到本地

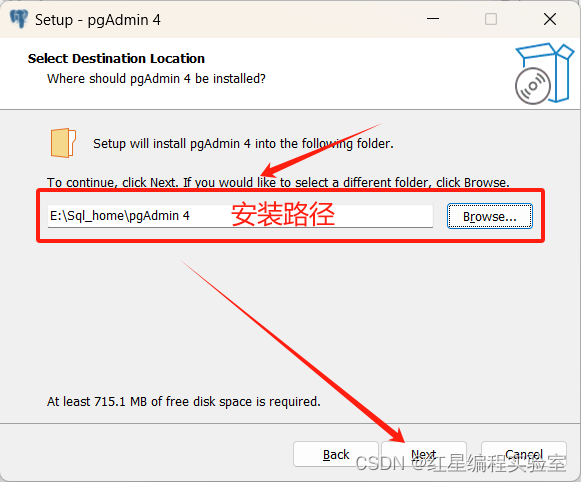
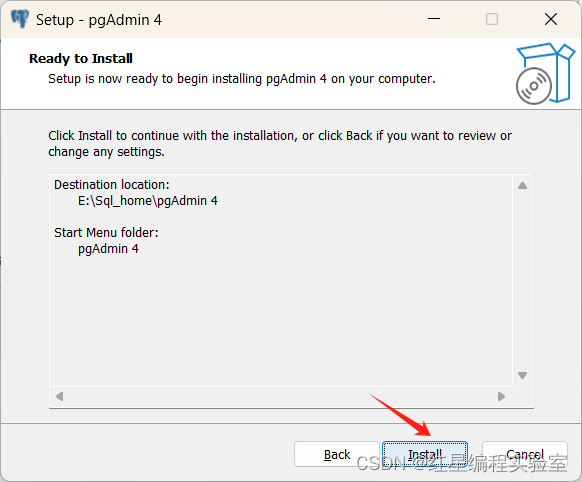
安装
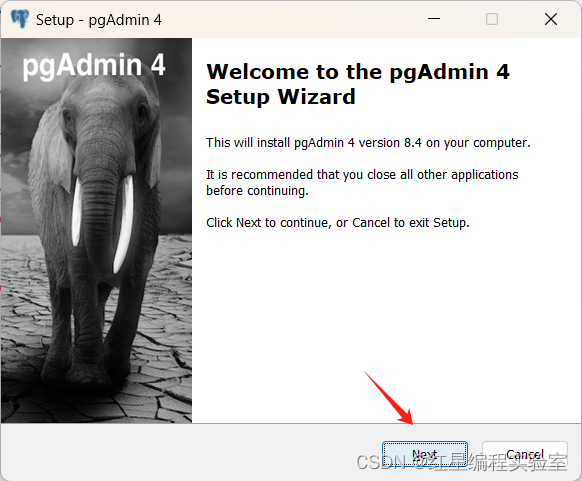
运行安装引导器

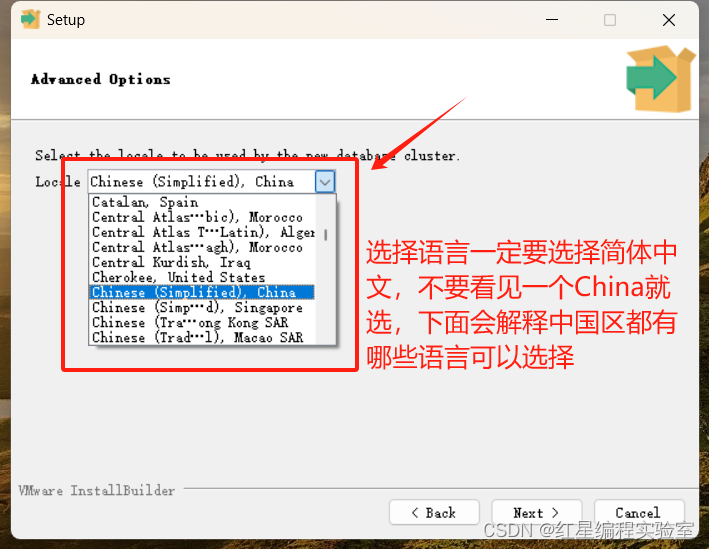
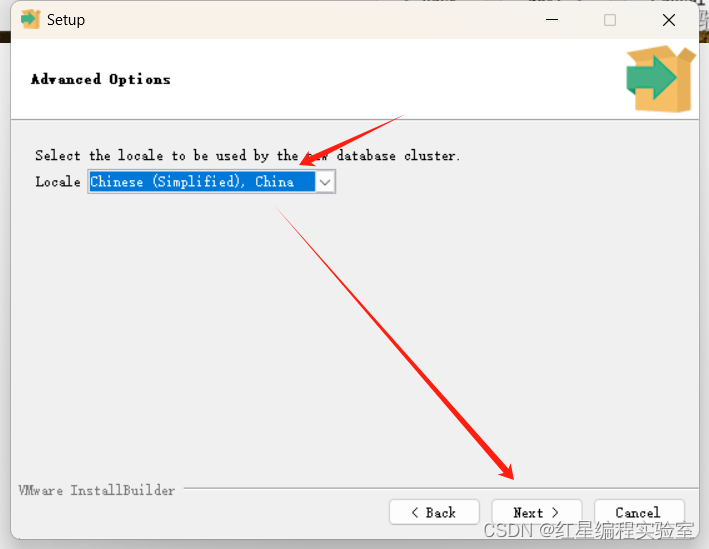
| Chinese(Simplified), china | 简体中文 |
| Chinese(Traditional),Taiwan、kong、macao | 繁体中文 (港澳台还特意单独搞了三个选项,真是辛苦你了) |
| Mongolian (Traditional Mongolian),China | 蒙古语(传统蒙古语) |
| Tibetan China | 藏语 |
| Uyghur, china | 维吾尔族语 |
| Yi,China | 彝族语 |
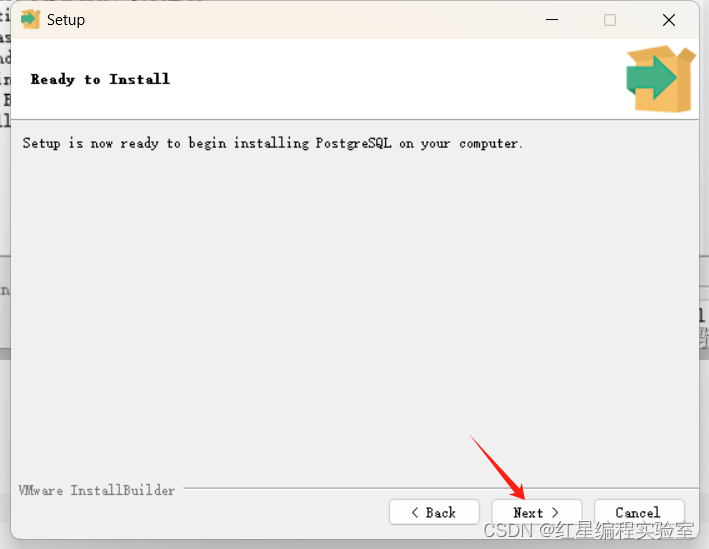
自行安装
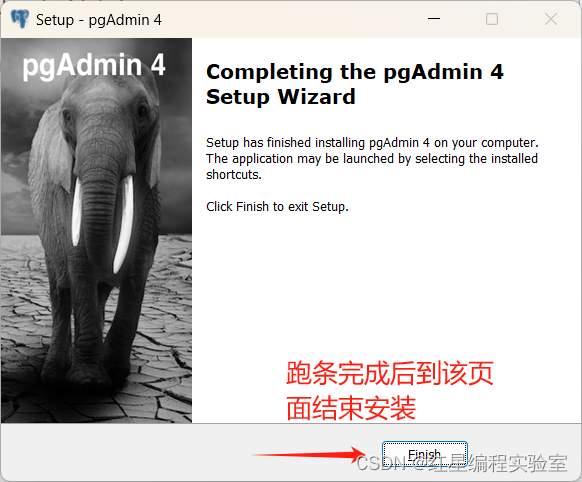
安装完点finish就行了
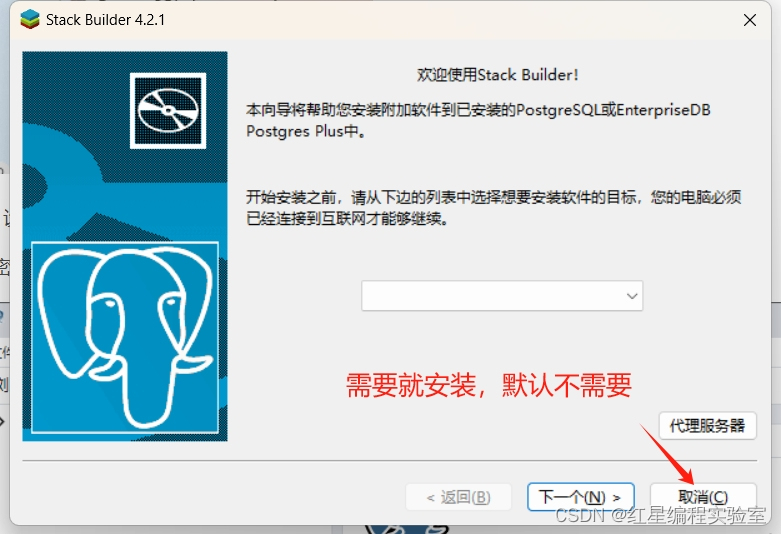
不需要就取消安装引导,一般都不需要。
二次安装
如果你在安装中有遇到报错
Problem running post-install step. Installation may not complete correctly. The database cluster initialisation failed.
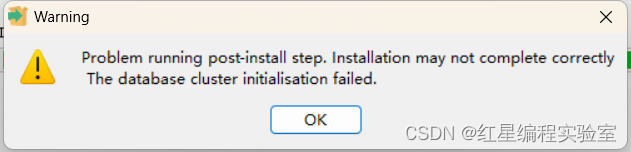
就说明你是二次安装的人,请遵循如下操作,一步都不要少
1.卸载旧版pgsql
通过系统的“控制面板”来找到pgsql,并且右键,“卸载”,进入卸载引导
2.删掉旧版pgsql的主体文件夹,因为里面会有data文件夹影响后续安装的非空要求
3.删除注册表
win的搜索功能搜索“注册表”,并打开“注册表编辑器”,组合键ctrl+F打开搜索功能,输入“postgresql”,点击“查找下一个”,可以找到两个“数据”列写着postgresql的两个行,找到并删除这两个行,其余不要动,也不要删错
4.关闭杀毒软件,接下来的操作会被杀软判定为“报毒”,其实不用怕
5.在系统内新增postgres用户
win的搜索功能搜索“终端”,以管理员身份运行“终端”
输入以下命令
net user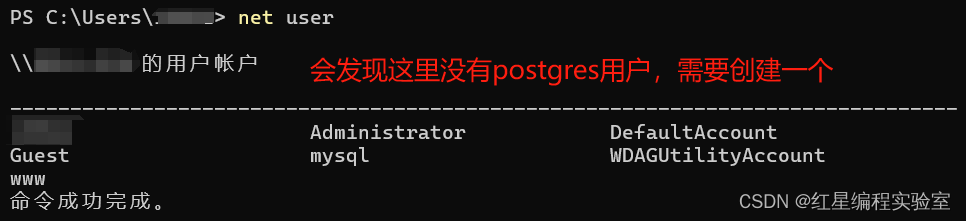
用如下命令创建,推荐只修改密码部分
net user postgres password /add例如
net user postgres 123456 /add
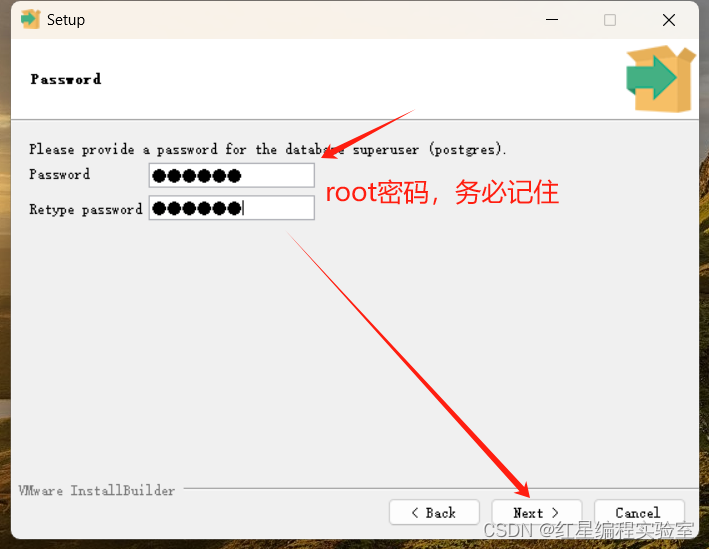
这个密码是超管密码,务必记住,后面数据库安装要用
再次查看用户是否被创建

然后就可以重新安装新的pgsql了
以“管理员身份”运行安装程序
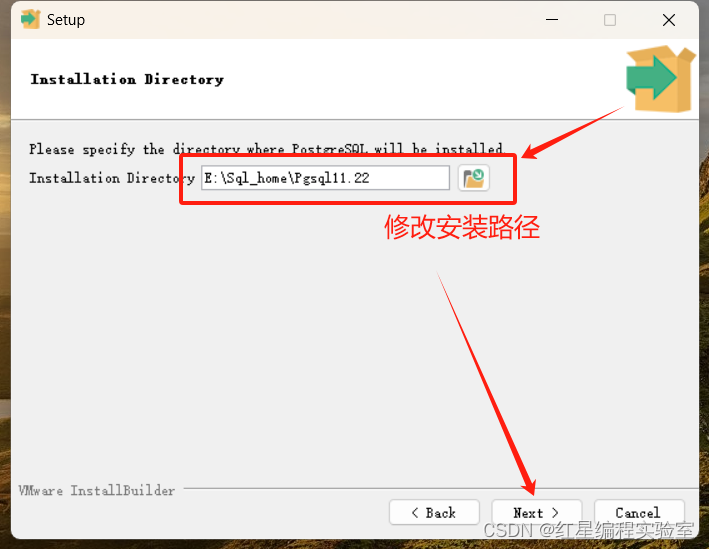
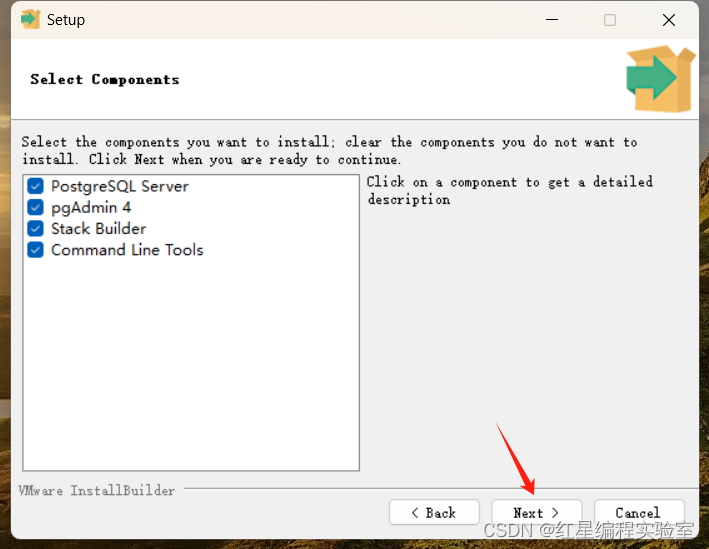
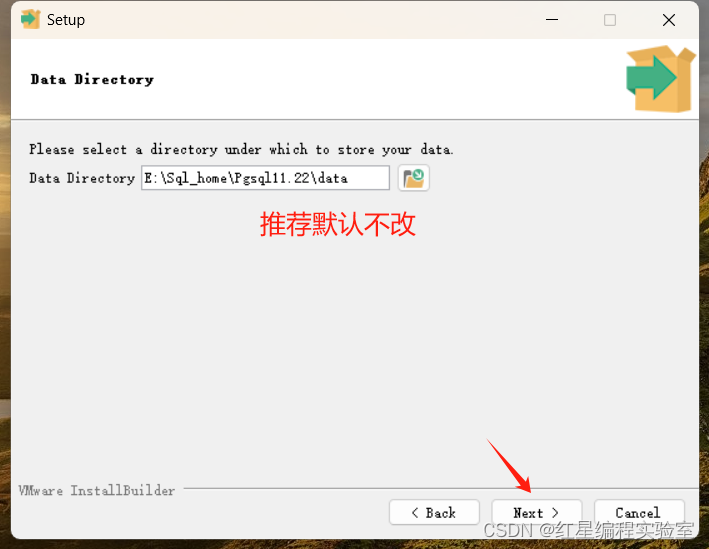
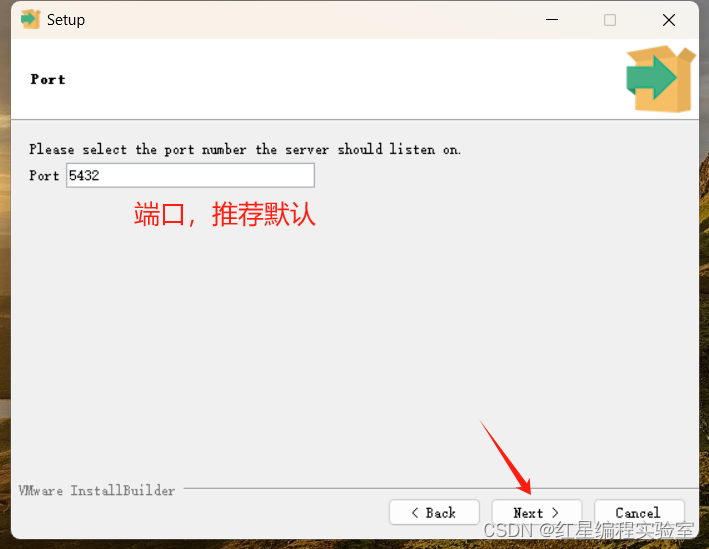
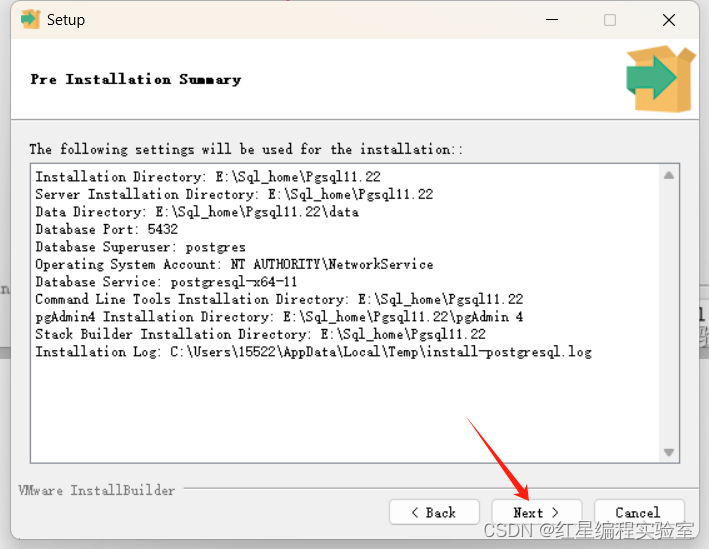
安装步骤预览:next》选择安装位置》next》next》输入密码(账号默认postgres,输入刚刚net user里创建用户的密码)》next(端口号默认5432)》next(语言选C)》next 》next
这一次如果没有缺少步骤应该就不会再弹出报错窗口了
pgadmin4问题解决

初次打开会很快,长时间打不开就会遇到以下问题
遇到下图这种报错
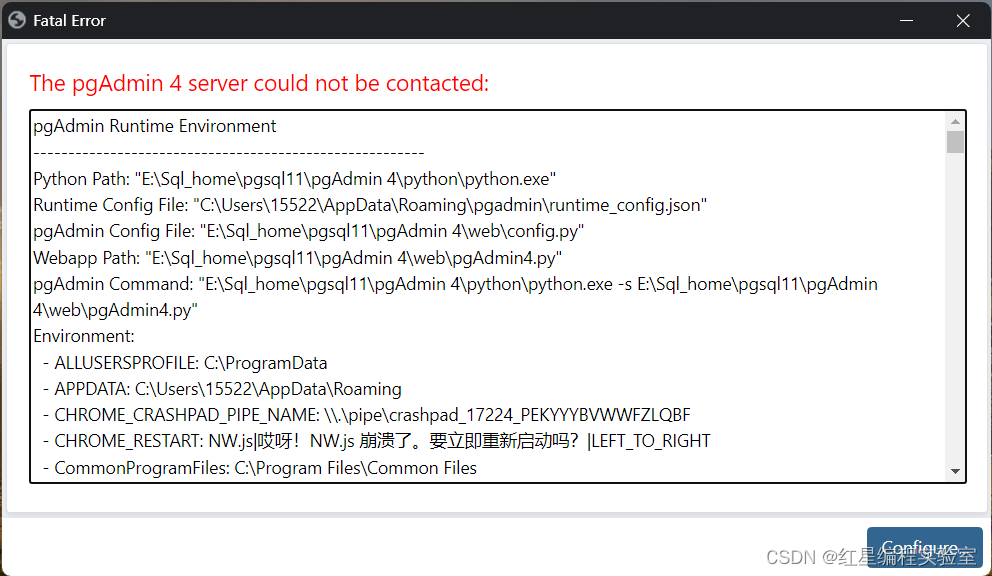
这个问题有很多种解决方案
1.与系统不匹配(老系统可能有)
那大概是因为上面pgsql安装时一起附带安装的pgadmin不是适合当前电脑的版本,需要自行下载一个合适的pgadmin4的版本安装
pgadmin4的win版下载
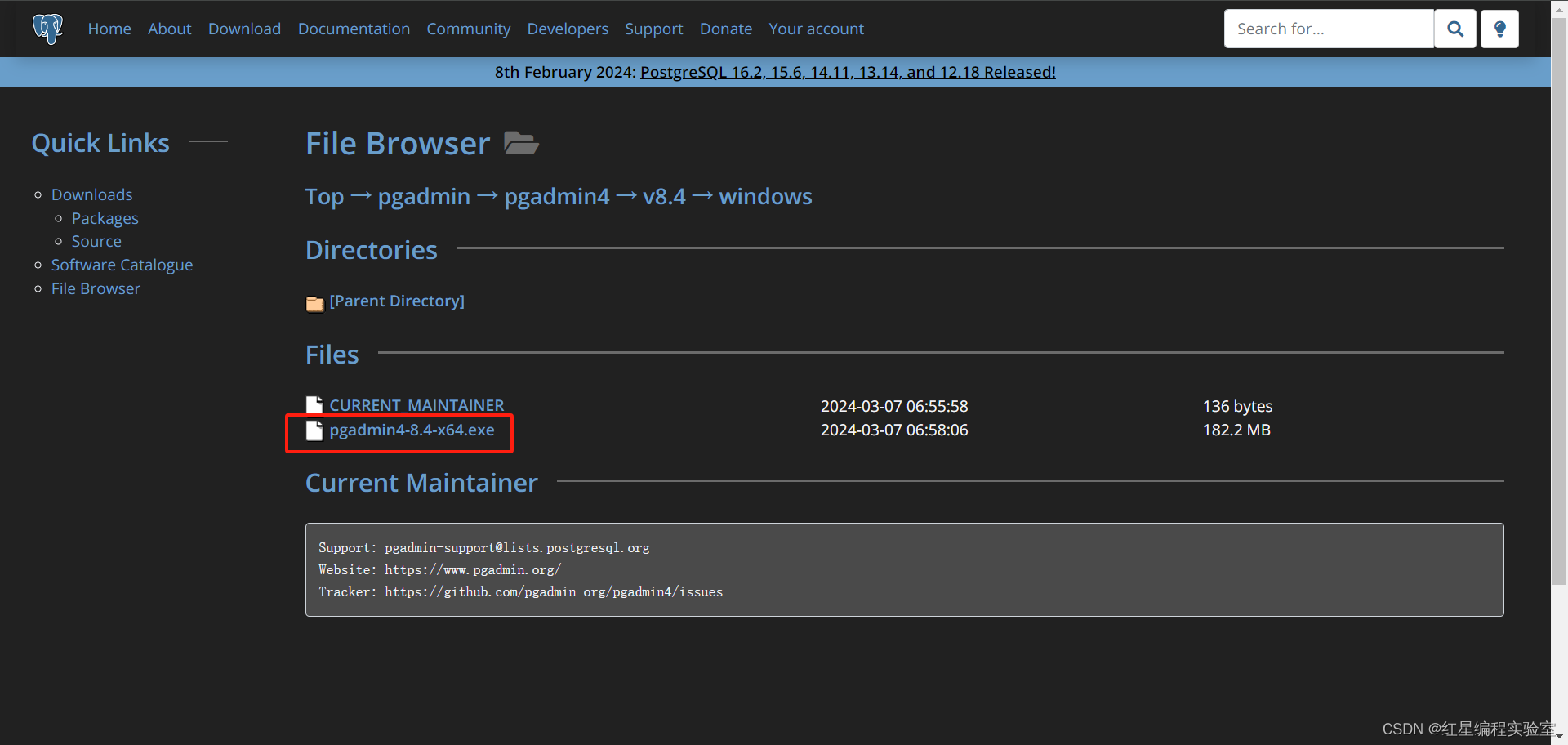

以管理员模式运行



2.以前旧版本的pgadmin4的残存数据影响新版本运行
关闭当前的pgadmin4应用
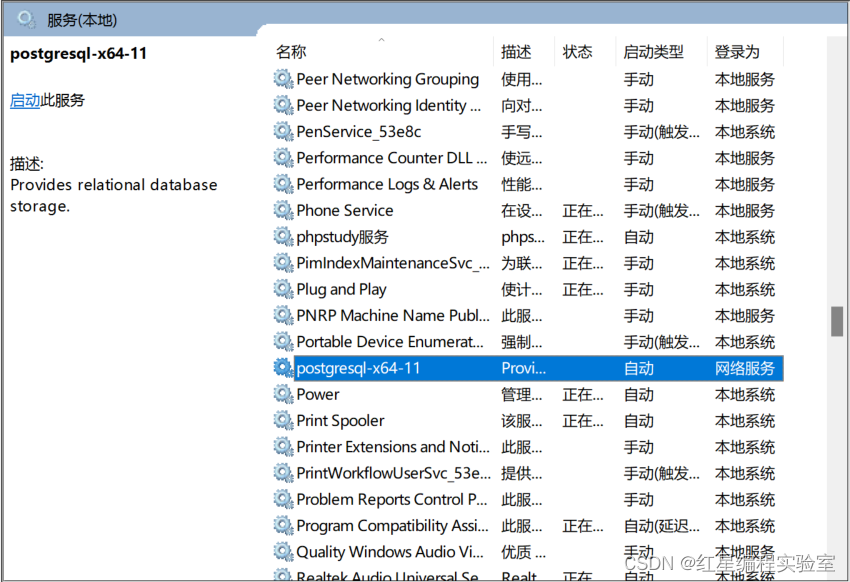
win的搜索功能搜索“服务”,进入“服务”后找到“postgresql-x64-11”服务,并暂停服务
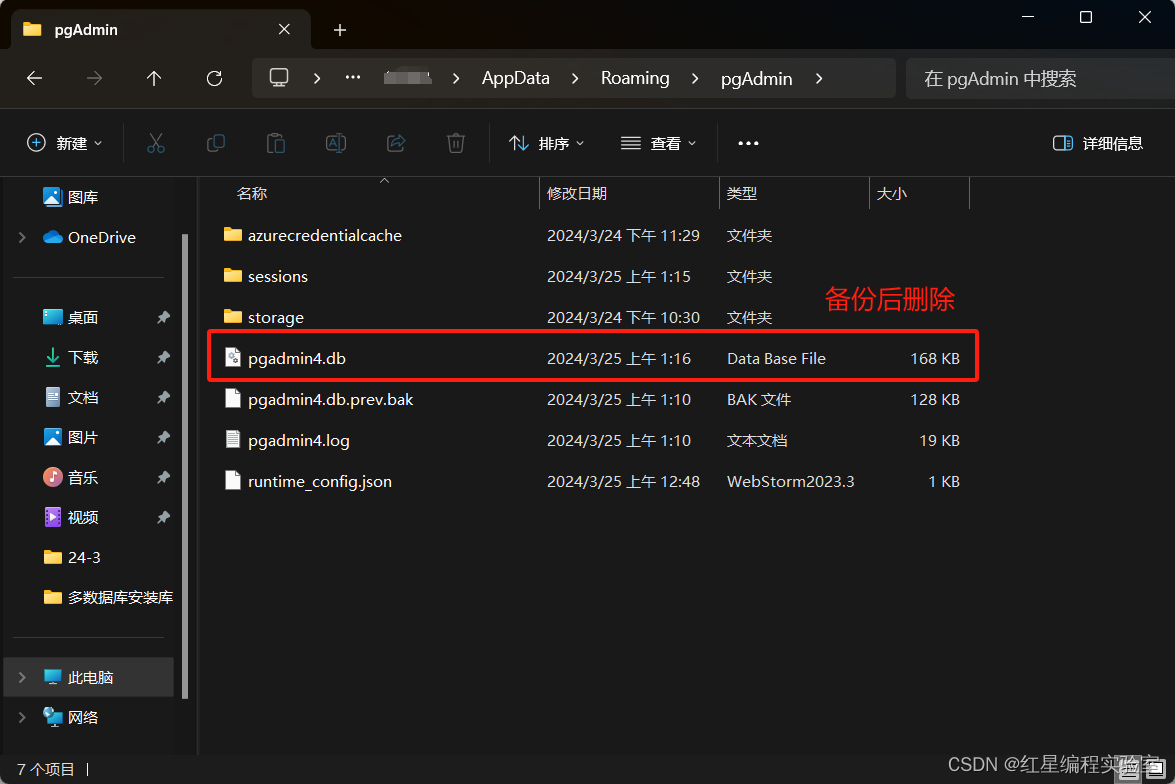
进入资源管理器或者“此电脑” ,按以下路径寻找文件夹位置(取消资源管理器的隐藏系统文件选项的勾选,否则找不到AppData文件夹)
C:\Users\15522\AppData\Roaming\pgAdmin
重启当前的pgadmin4应用
可以完美启动
汉化pgadmin4
当我们千辛万苦成功打开了pgadmin4进入页面,先调一个汉化出来(首次安装者无需看此步)
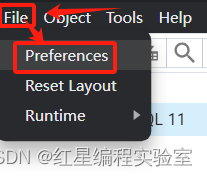
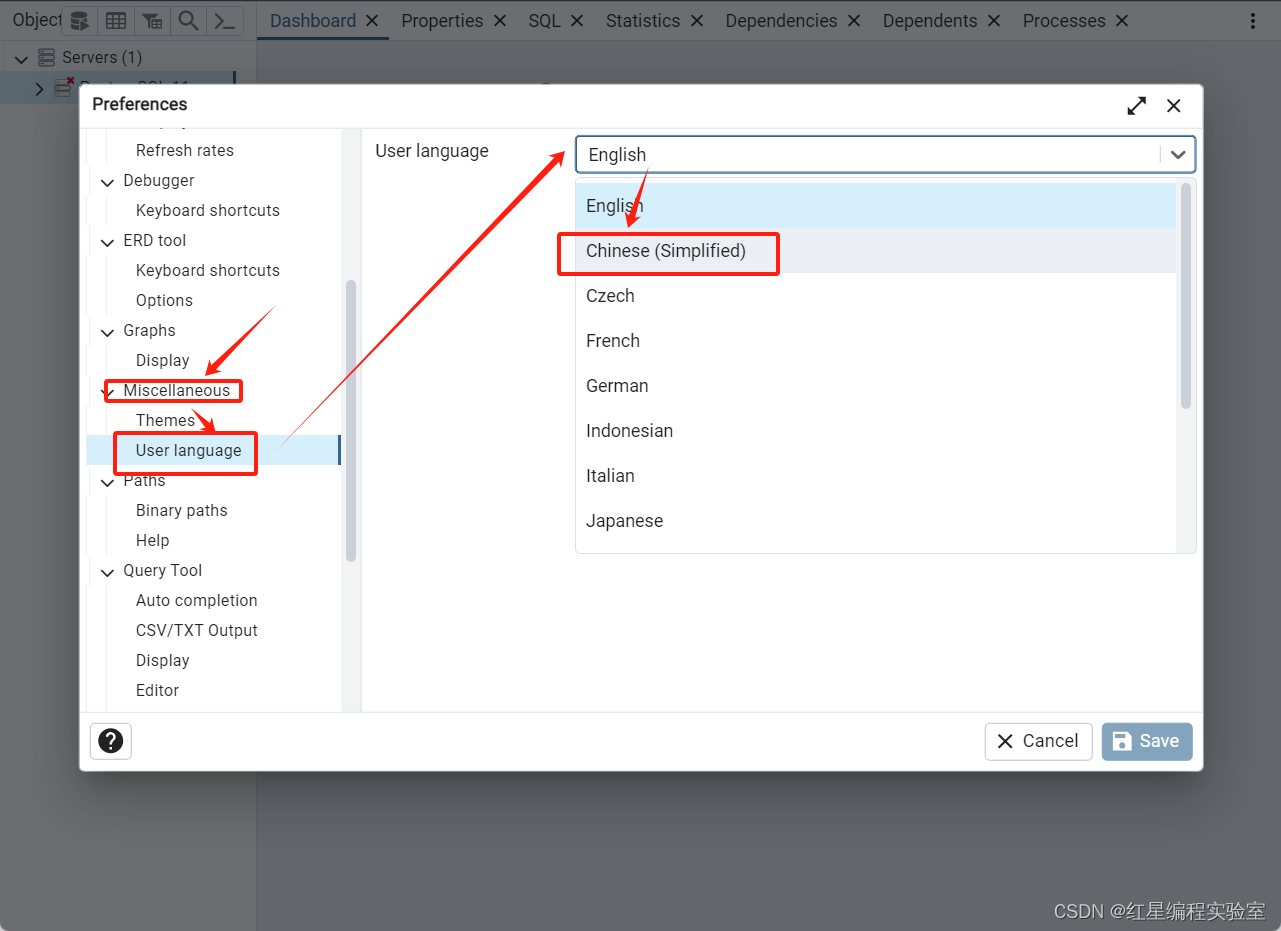
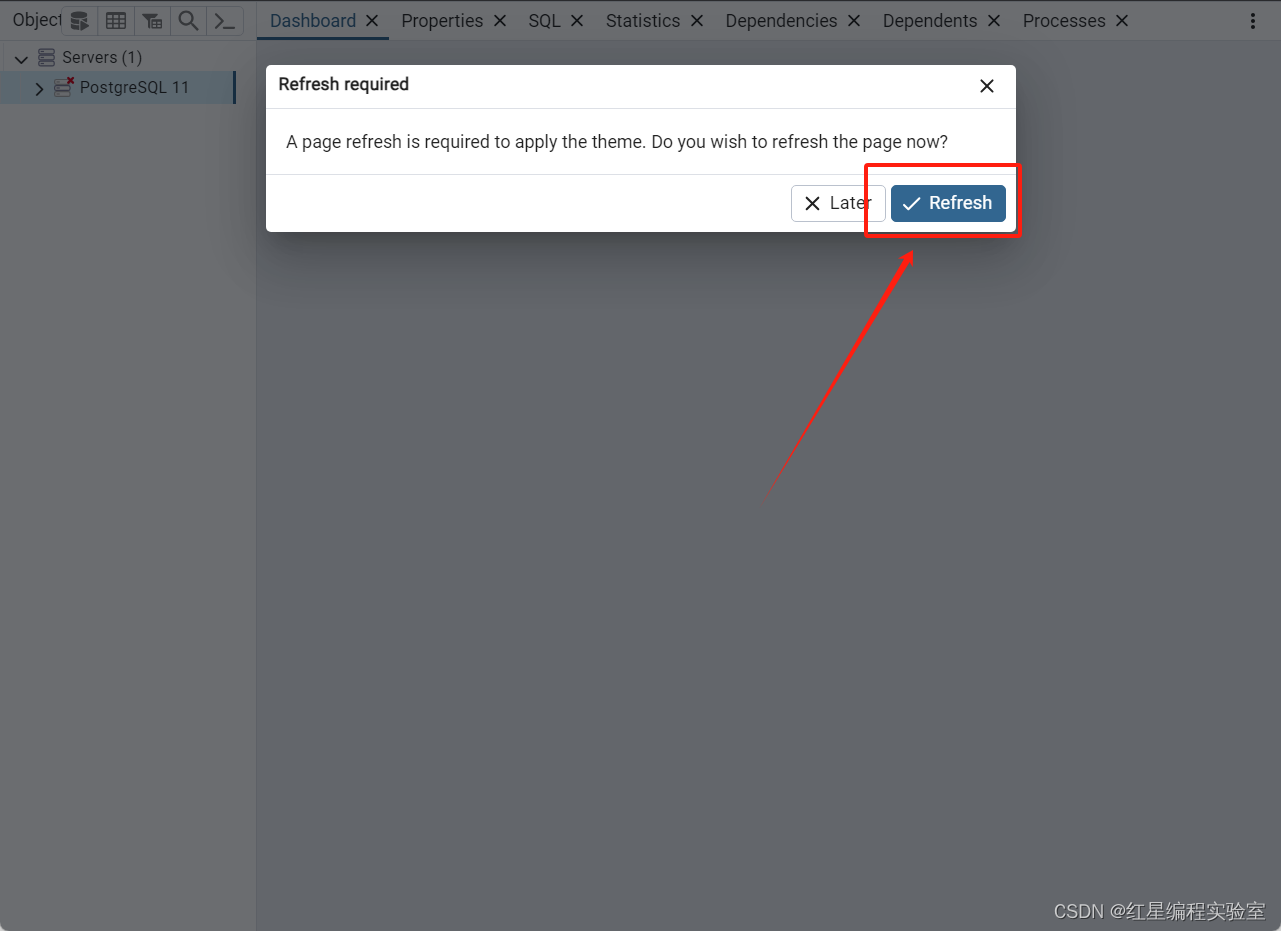
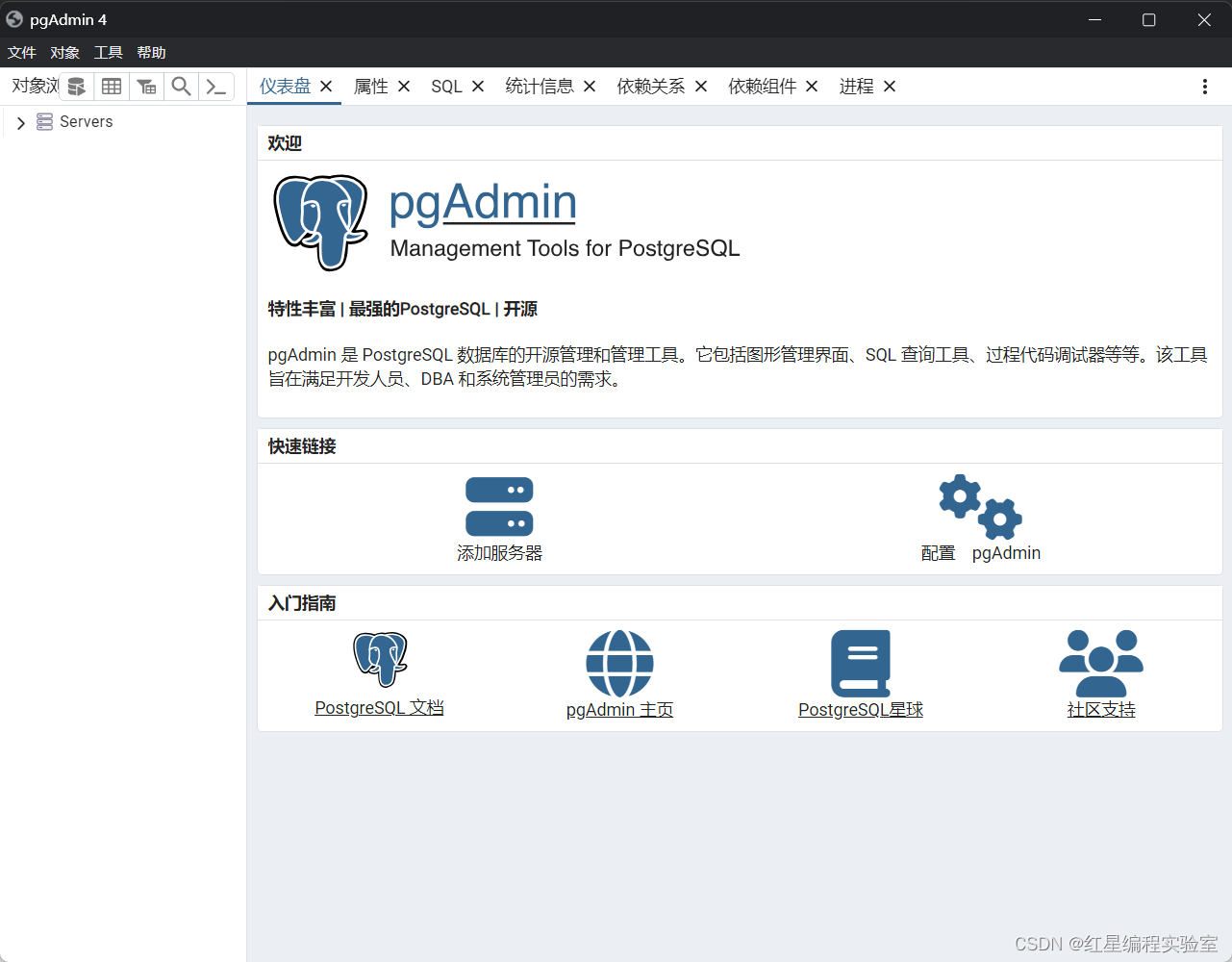
汉化完成
用pgAdmin4连接pgsql11
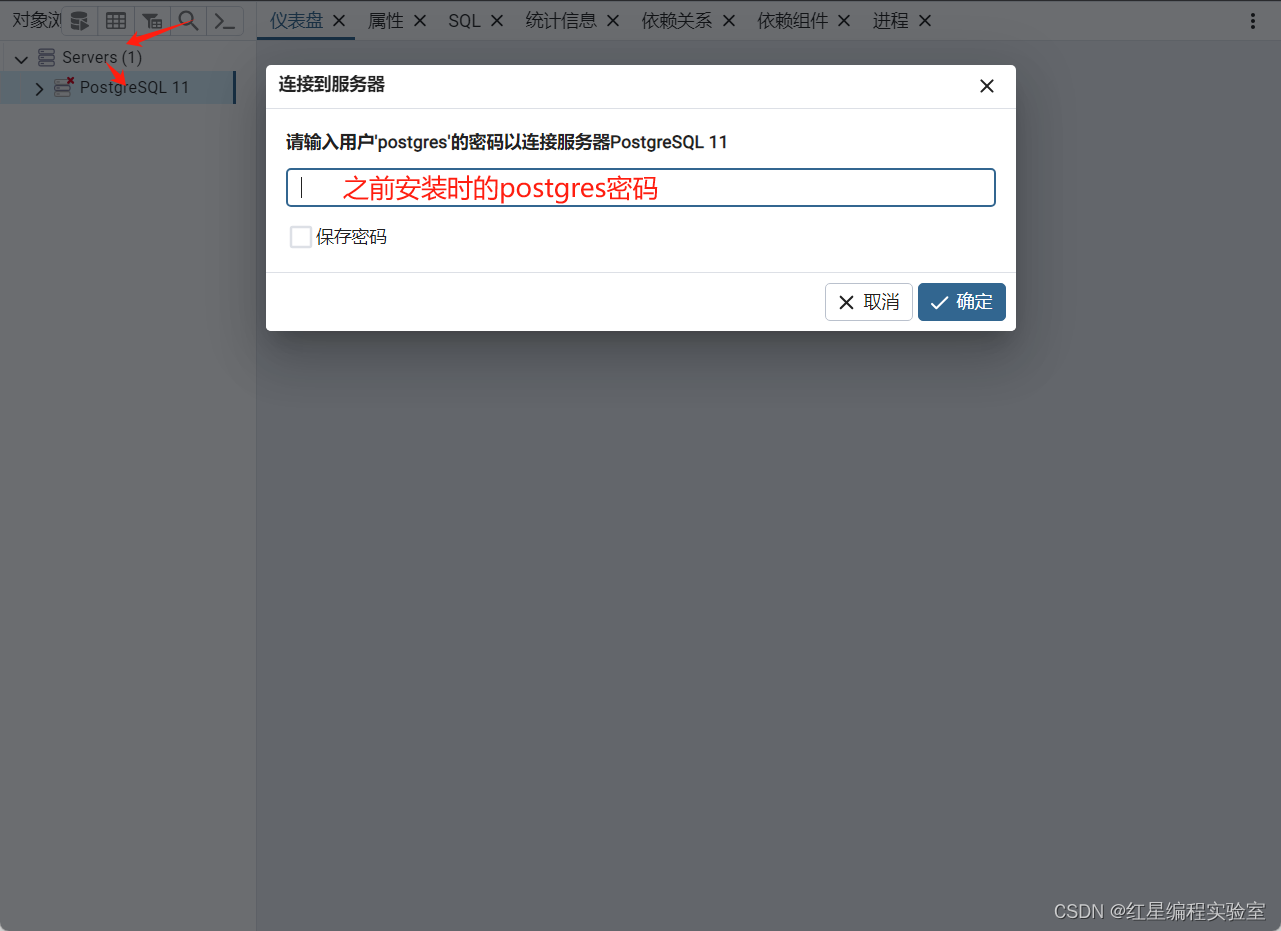
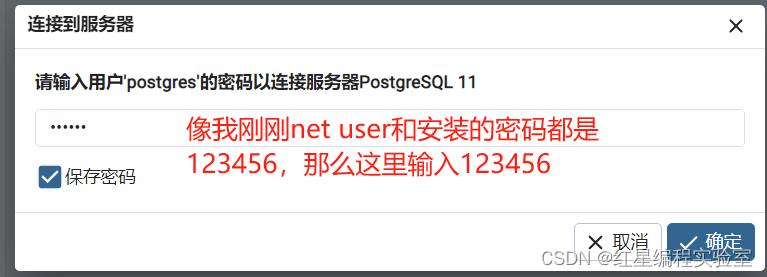
如果出现连接不上的情况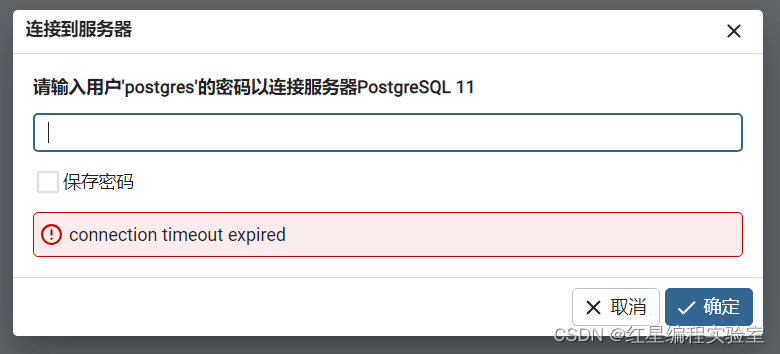
那么就是刚刚的二次重装步骤中暂停了“postgresql-x64-11”服务,我们手动开启pgsql的服务
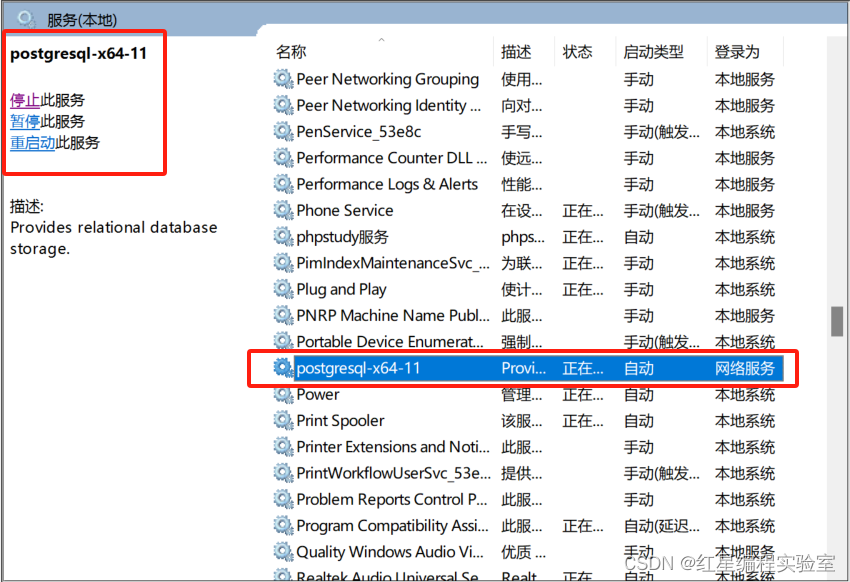

完美秒杀,成功连接pgsql11
参考文献(感谢声明):
终于解决!!!the pgadmin4 server could not be contacted——
Windows 10上安装PostgreSQL详细教程,及“数据库群集初始化失败“问题解决——IT愤青
安装postgres10 后,使用自带的pgAdmin 4 访问数据库,出现The pgAdmin 4 server could not be contacted错误的最完美解决方案,另附安装步骤。
——木易GIS
作者的话(Alvin):
因为jetbrain全家桶的一次小崩溃导致的win11重做系统,凑巧那我就重新安装一下pgsql11版,结果万万没想到这一路遇到好几个大坑,顺便把安装过程和问题解决直接合成一个大合集写成一篇文章,三个小时的精华都在这里了(笑哭)希望能够帮到你们吧