专业网站设计报价类似wordpress的平台
目录
CISC vs RISC
概念和历史
CISC vs RISC
对比举例:X86的CAS(做原子操作的)
对比举例:ARM的CAS(做原子操作的)
指令寻址
指令中的操作数的寻址方式
各语言对象内存布局对比
C++内存布局
理解编译单元
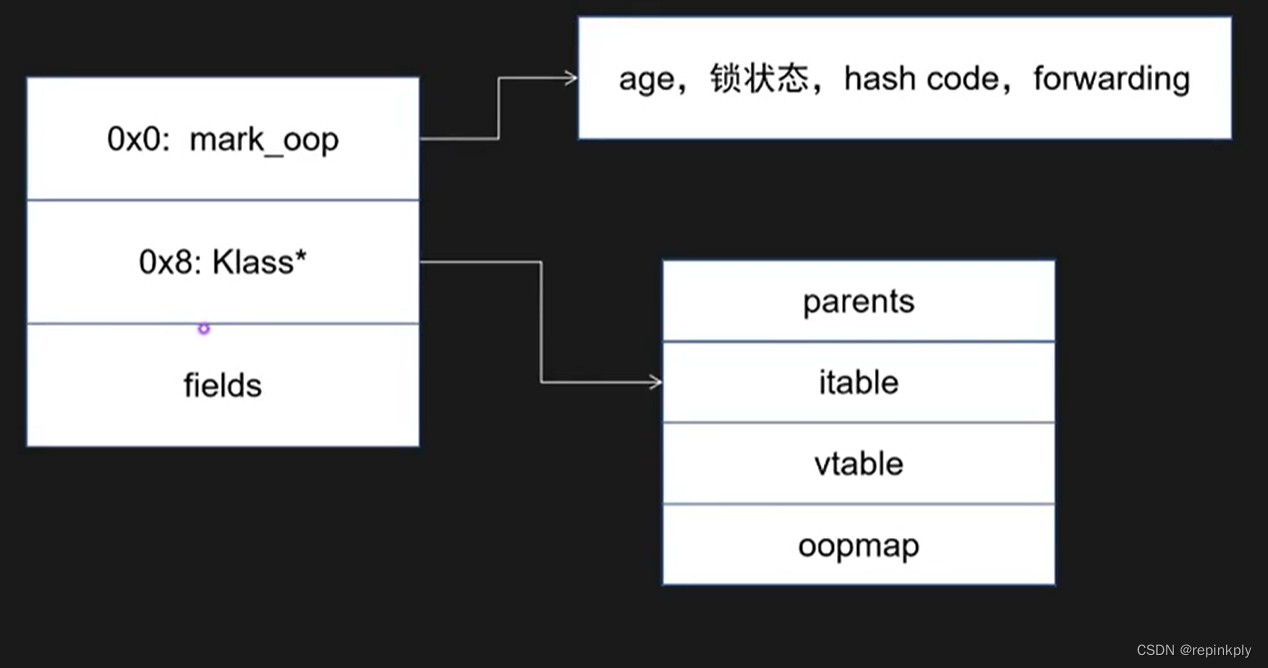
Java对象内存布局
python对象模型
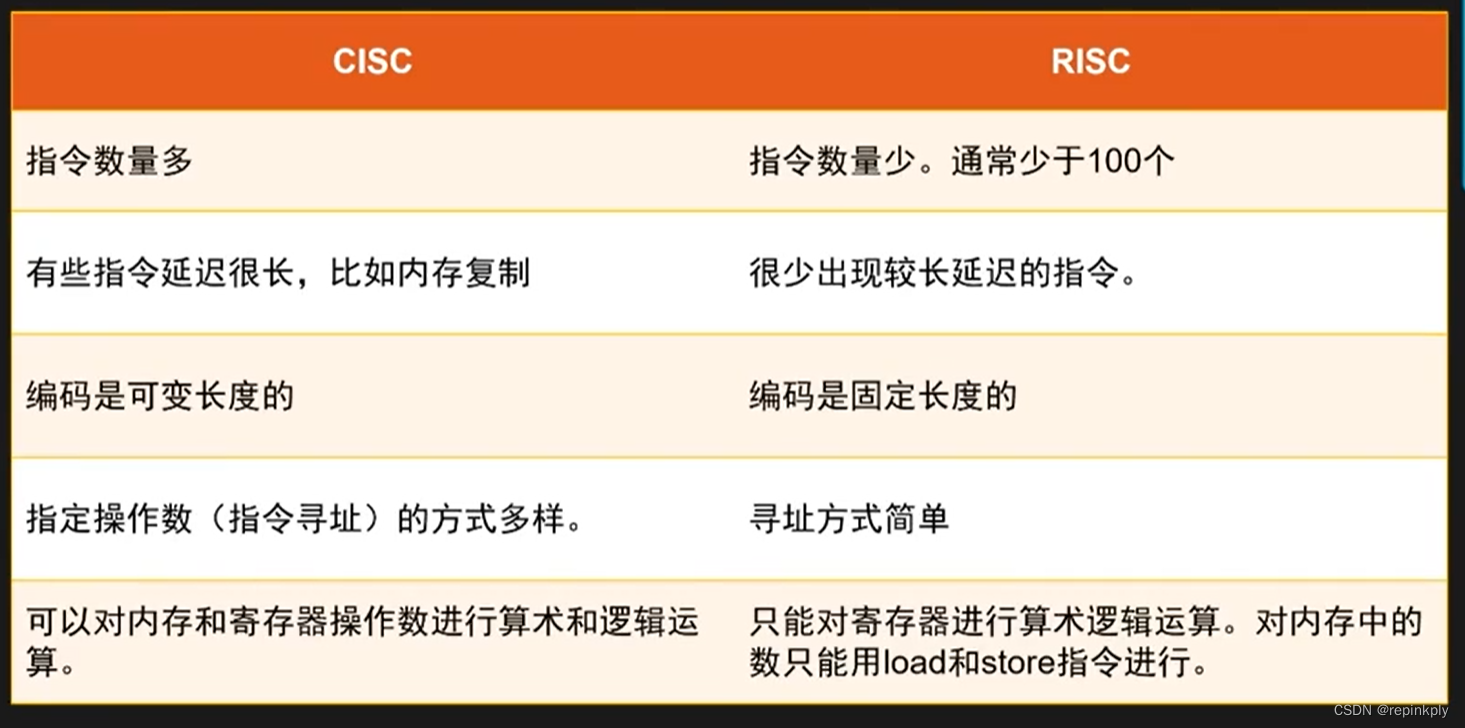
CPU 的设计思路大致分为两个流派,一个是复杂指令集(Complex Instruction Set Computing, CISC),另一个是精简指令集(Reduced Instruction Set Computing, RISC),前者的代表是 X86,后者的代表是 Arm 和 RISC-V。
RISC 的特点是指令长度短,运行速度快,但每条指令能做的事情比较少;CISC 的特点是 指令长度长,运行速度慢,但指令能做的事情多。相同的 C 代码,翻译成 RISC 指令,往往比 CISC 最终翻译出的二进制文件的体积更大。
我们还会讲解寻址模式。寻址就是在程序中如何定位地址,可以 类比成现实生活中在地图上定位某个地址的过程。这也是你在学习内存管理时的必备知识。
CISC vs RISC
概念和历史

CISC vs RISC

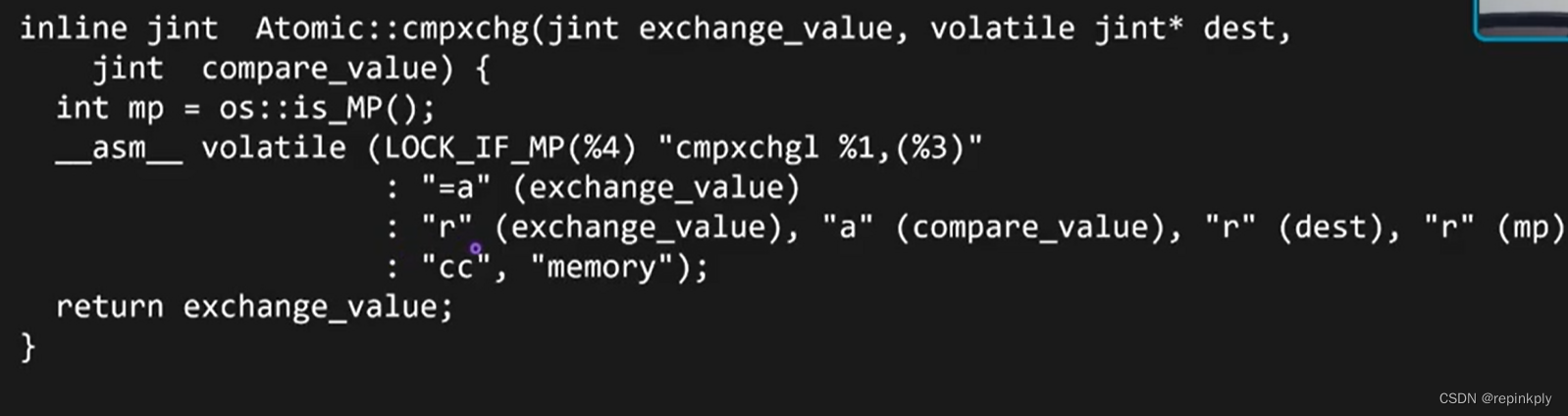
对比举例:X86的CAS(做原子操作的)
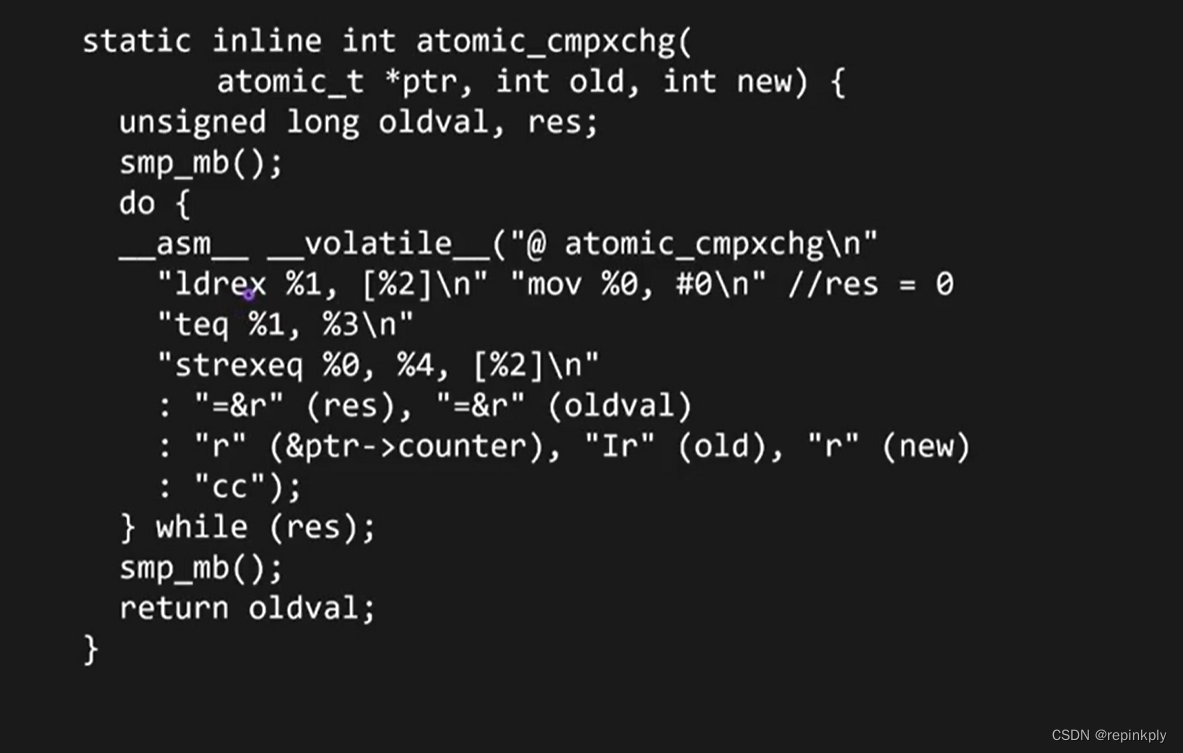
对比举例:ARM的CAS(做原子操作的)
指令寻址
指令中的操作数的寻址方式


各语言对象内存布局对比
C++内存布局
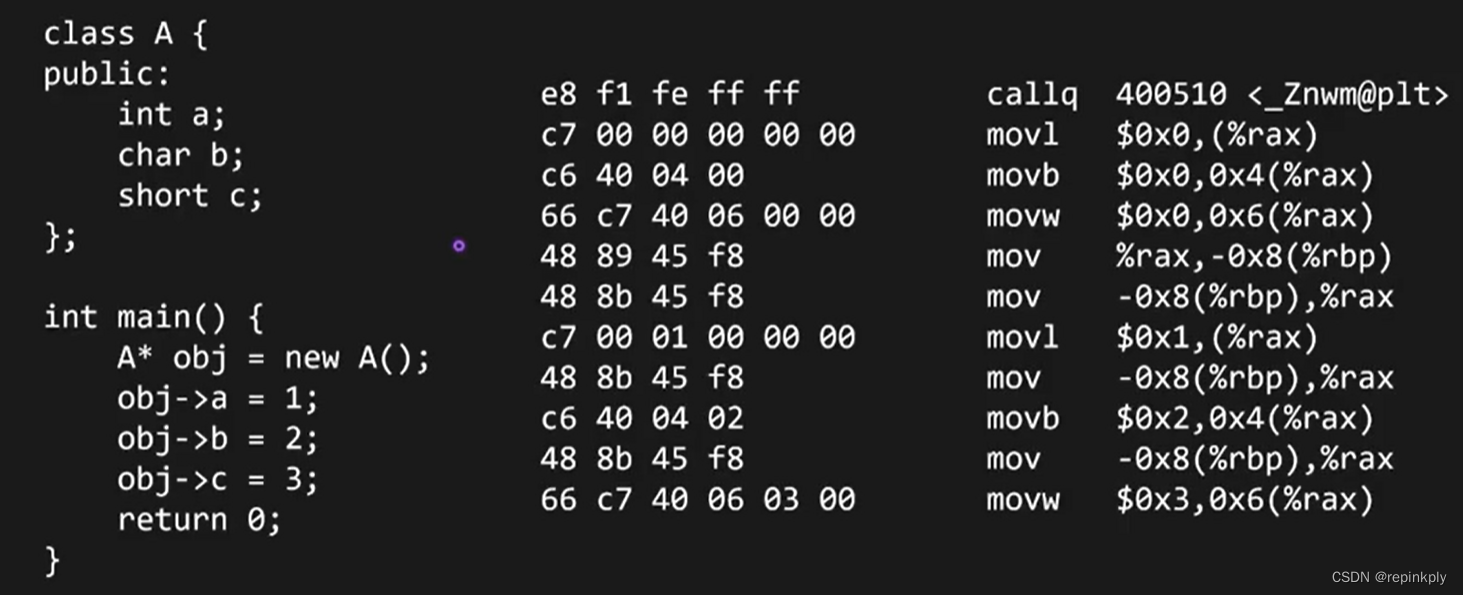
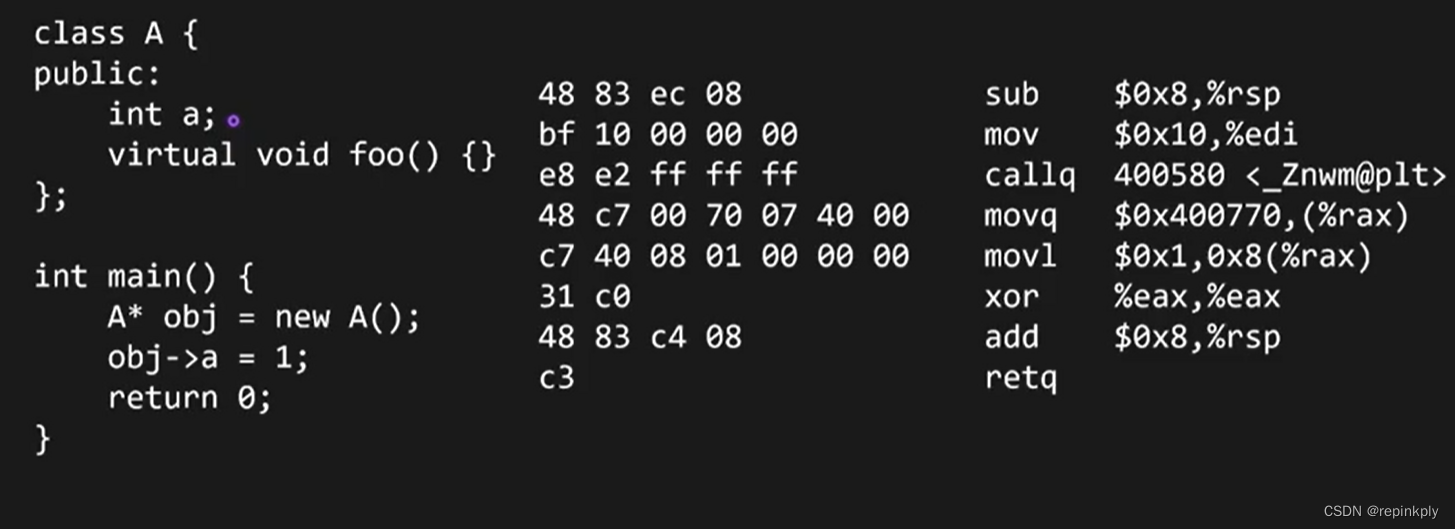
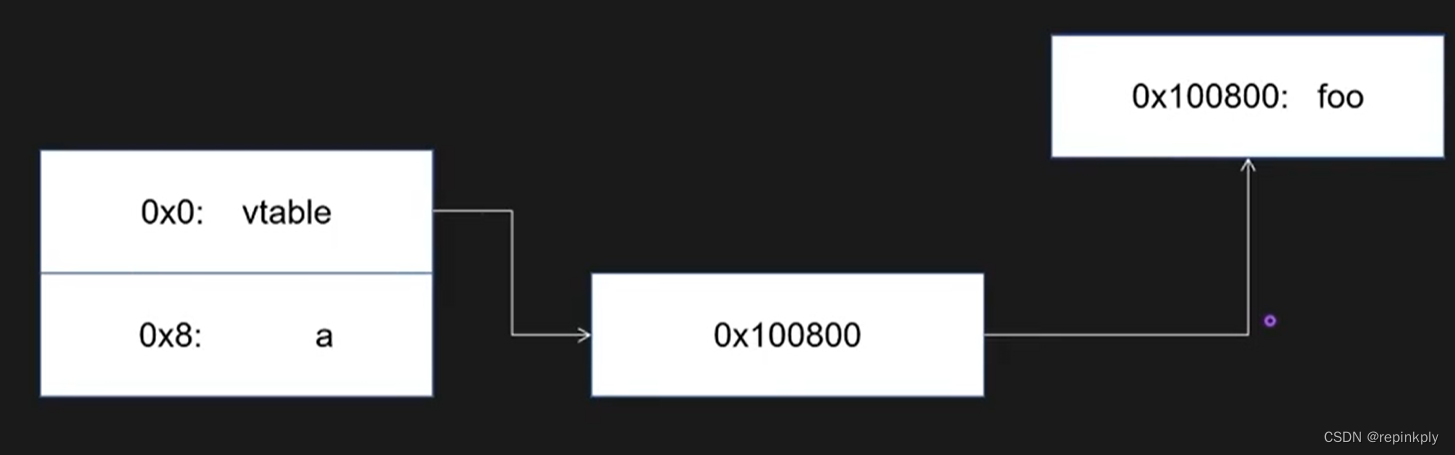
C++内存布局:虚函数
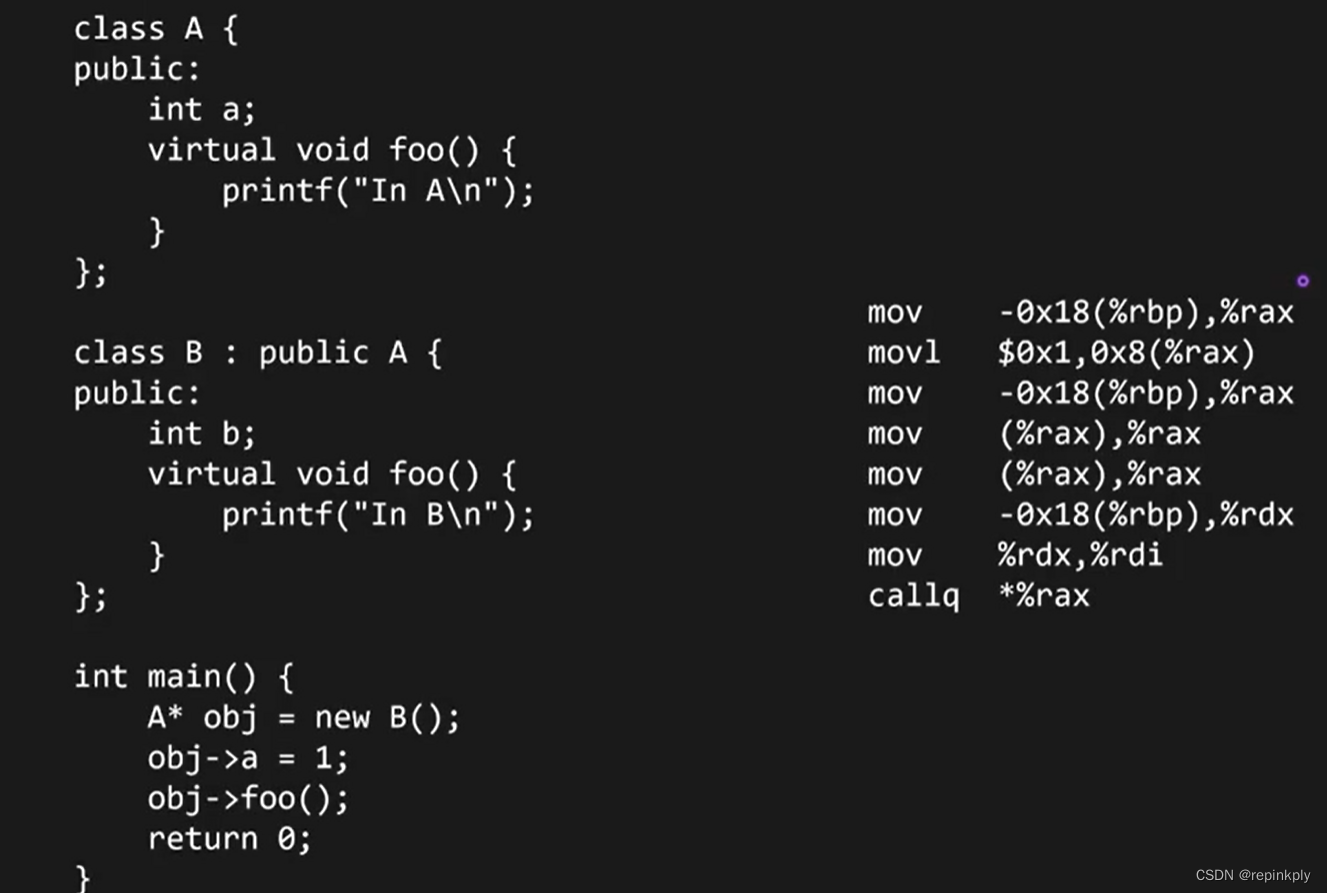
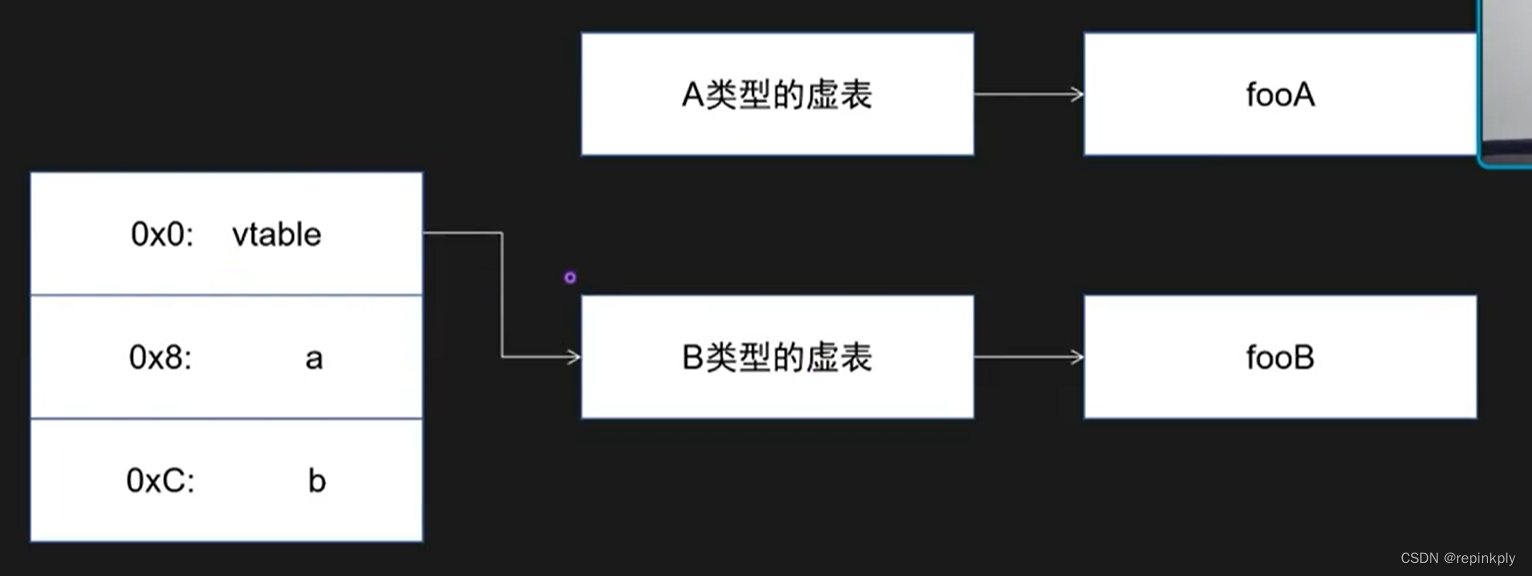
C++内存布局:继承
运行时识别
dynamic_cast 依赖虚表

、
理解编译单元

Java对象内存布局
python对象模型
