做个网站设计多少钱做论坛和做网站有什么区别
一、存储类型
存储类型可分为三类:DAS(直连式存储),NAS(网络附加存储),SAN(存储区域网络)。
1.1 DAS
定义:
DAS是指直连存储,即直连存储,可以理解为本地文件系统。这种设备直接连接到计算机的主板总线上,而计算机可以将其连接到常见的硬盘、U盘等块de上,这种设备很难共享。
特征:
DAS具有较低的购置成本和简单的配置。 使用过程与使用本地硬盘没有太大区别。 服务器要求只是一个外部SCSI端口,这使得它对小型企业非常有吸引力。
缺点:
(1)数据备份操作复杂。
(2)服务器本身很容易成为系统瓶颈。
(3)服务器出现故障,无法再访问数据。
(4)在多台服务器的系统中,设备分散,管理不方便。
1.2 NAS
定义:
NAS意味着网络区域存储,即它是network-connected.storage.It 通常,您使用本地存储空间与其他主机共享,并且通常通过C/S进行通信architecture.It 实现文件级共享。 计算机通常将共享设置识别为文件系统,其文件服务器管理锁以实现并发访问。网络文件系统以文件模块的形式共享,运行在应用层上。 常见的NAS是NFS和CIFS(FTP).
特征:
NAS实际上是一个带有瘦服务器的存储设备,这个瘦服务器实际上是一个网络文件服务器。NAS设备直接连接到TCP/IP网络,网络服务器通过TCP/IP访问管理数据network.As 一个瘦服务器系统,NAS是一个带有瘦服务器的存储设备,这个瘦服务器实际上是一个网络文件服务器。 它易于安装和部署,易于管理和使用。
缺点:
(1)由于存储的数据是通过网络传输的,容易出现数据泄露等安全问题。
(2)存储的数据通过网络传输,因此容易受到网络上其他流量的影响。 如果网络上有其他较大的数据流量,则对系统的性能造成严重影响。
(3)存储可能会对系统效率产生严重影响,因为它只能作为文件进行访问,而不能像正常文件系统中那样作为物理数据块进行访问。 例如,大型数据库不能使用nas作为存储方案。
1.3 SAN
定义:
SAN是运行在内核中的存储区域网络, 将其模拟为SCSI总线以使用传输网络。 每个主机的网卡对应SCSI总线中的一个发起端,服务器对应1个或多个目标。 要通过FC或TCP/IP封装SCSI数据包,它实现了块级共享,通常被识别为块设备,但需要特殊的锁管理软件来实现多主机并发访问。
特征:
SAN实际上是专门为独立于TCP/IP的存储而建立的专用网络network.At 目前,常见的SAN提供从2gb/S到4gb/S的传输速率。与此同时,由于SAN网络独立于数据网络而存在,因此访问速度非常快。 此外,SAN通常使用高端RAID阵列,因此SAN的性能在一些专业的网络存储技术中脱颖而出。由于SAN基于专用网络,因此非常方便,因为它具有非常高的可扩展性,无论您是要向SAN系统添加一定量的存储空间,还是要向使用存储空间的多个服务器
缺点:
(1)需要另建光纤网络,异地扩展比较困难。 (2)无论是SAN阵列机柜还是SAN所需的光纤通道交换机,价格都非常高。
1.4 应用场景
DAS相对较旧,但它非常适合数据量低,磁盘访问速度高的小型企业。
NAS主要适用于存储非结构化数据的文件服务器。 它受以太网速度的限制,但部署灵活,成本低。
SAN适用于大型应用和数据库系统,但缺点是成本更高,更复杂。
二、ftp协议
2.1 简介
FTP是FileTransferProtocol(文件传输协议)的英文简称,而中文简称为“文传协议”。用于Internet上的控制文件的双向传输。同时,它也是一个应用程序(Application)。基于不同的操作系统有不同的FTP应用程序,而所有这些应用程序都遵守同一种协议以传输文件。
ftp默认使用TCP协议的20、21端口与客户端进行通信
20端口用于建立数据连接,并传输文件数据
21端口用于建立控制连接,并传输FTP控制命令
2.2 ftp的数据连接模式
主动模式:服务器主动发起数据连接
被动模式:服务器被动等待数据连接
三、vsftpd的安装和配置
3.1 svftpd安装
rpm -qc vsftpd //检查vsftpd安装包是否存在,存在即不需要安装yum install -y vsftpd //yum 安装vsftpd
cd /etc/vsftpd
ls //切换到安装好vsftpd目录下查看文件
3.2 vsftpd中配置的作用
vsftpd初始化全局配置
vim /etc/vsftpd/vsftpd.conf
anonymous_enable=YES #开启匿名用户访问。默认已开启
local_enable=YES #允许系统用户进行访问
write_enable=YES #开放服务器的写权限(若要上传,必须开启)。默认已开启
anon_umask=022 #设置匿名用户所上传数据的权限掩码(反掩码)。
四、FTP实验
本次实验运用ftp服务,模拟实际运用场景,分别针对匿名用户访问,本地用户访问不同的管控方式和权限设置。实现安全场景下,也能进行双方传输的操作环境
4.1 实验一 :匿名用户访问本机
简单设置,让匿名用户拥有访问本机和各种权限
anon_umask=022 #设置匿名用户所上传数据的权限掩码(反掩码)。
anon_upload_enable=YES #允许匿名用户上传文件。默认已注释,需取消注释
anon_mkdir_write_enable=YES #允许匿名用户创建(上传)目录。默认已注释,需取消注释
anon_other_write_enable =YES #允许删除、重命名、覆盖等操作。需添加修改配置vim /etc/vsftpd/vsftpd.conf

重启vsftpd服务,关闭安全防护
[root CXK /etc/vsftpd] systemctl start vsftpd
[root CXK /etc/vsftpd] systemctl stop firewalld
[root CXK /etc/vsftpd] setenforce 0
[root CXK /etc/vsftpd]
测试1 获取文件
本访问端放入一个a.txt的文件

客户端获取文件

测试2 写入文件
为了发送的畅通,可以修改一下匿名用户访问的根目录权限
chmod 777 /var/ftp/pub/访问端准备一个文件,写入信息
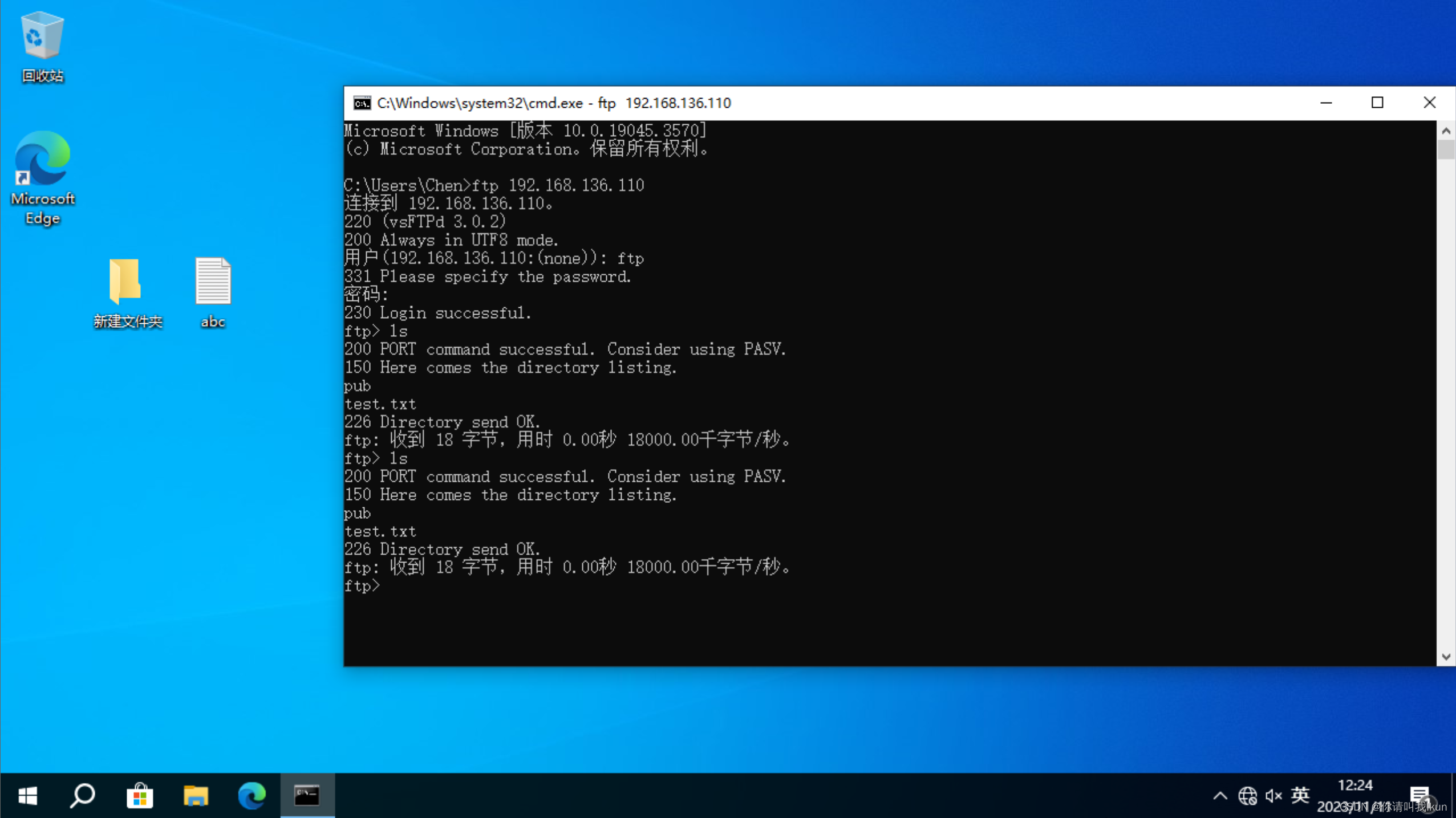



存在的缺点:匿名用户权限过高,存在安全隐患
4.2 设置本地用户验证访问ftp
4.2.1 设置本地用户可以访问ftp,禁止匿名用户登录
vim /etc/vsftpd/vsftpd.conf
local_enable=Yes #启用本地用户
anonymous_enable=NO #关闭匿名用户访问
write_enable=YES #开放服务器的写权限(若要上传,必须开启)
local_umask=077 #可设置仅宿主用户拥有被上传的文件的权限(反掩码)
systemctl restart vsftpd
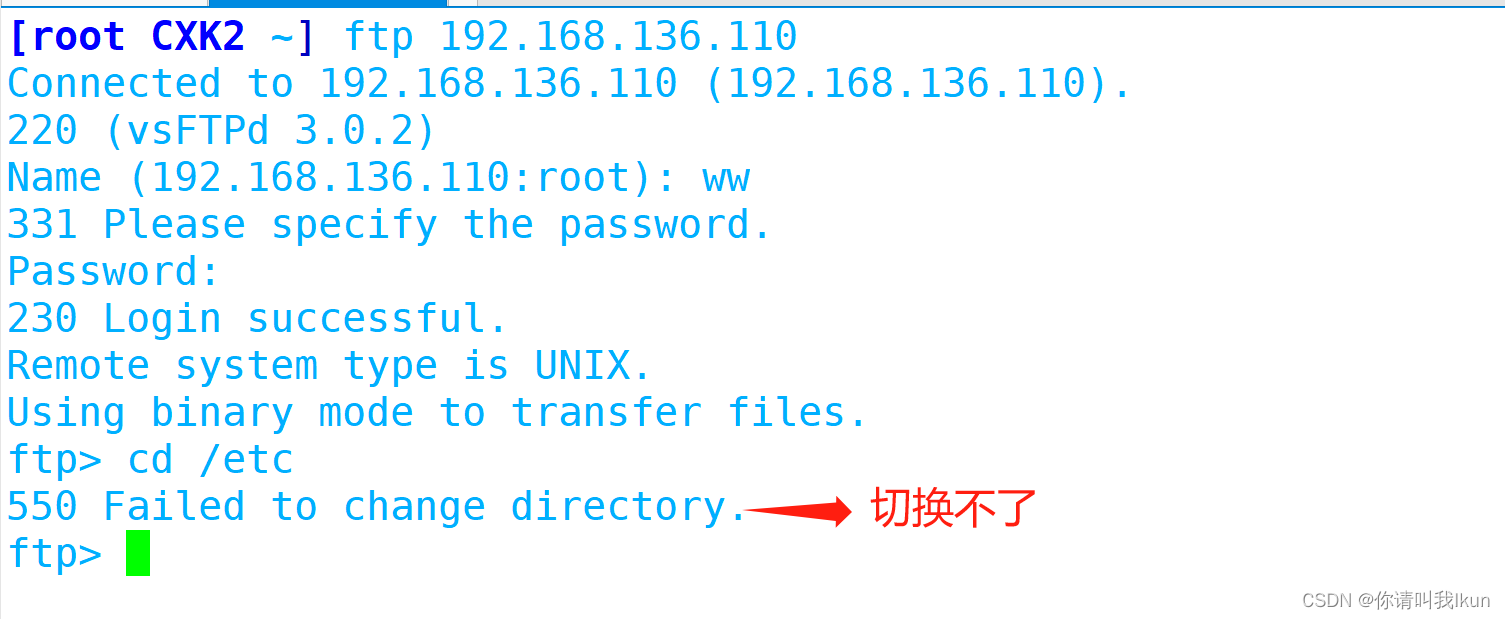
 安全隐患:本地用户访问可以随意切换目录
安全隐患:本地用户访问可以随意切换目录

4.2.2 对本地用户访问切换目录进行限制
添加切换目录的限制配置 :
vim /etc/vsftpd/vsftpd.conf
chroot_local_user=YES #将访问禁锢在用户的宿主目录中
allow_writeable_chroot=YES #允许被限制的用户主目录具有写权限
除此之外我们还能修改ftp服务访问时,宿主家目录,让它的家目录成为我们指定的地方
同样是修改 vsftpd.conf (在响应的版块添加即可,保存退出重启服务)
vim /etc/vsftpd/vsftpd.conf
修改匿名用户、本地用户登录的默认根目录
anon_root=/var/www/html #anon_root 针对匿名用户
local_root=/var/www/html #local_root 针对系统用户4.3 windows 可以通过windows的方式访问Linux主机端


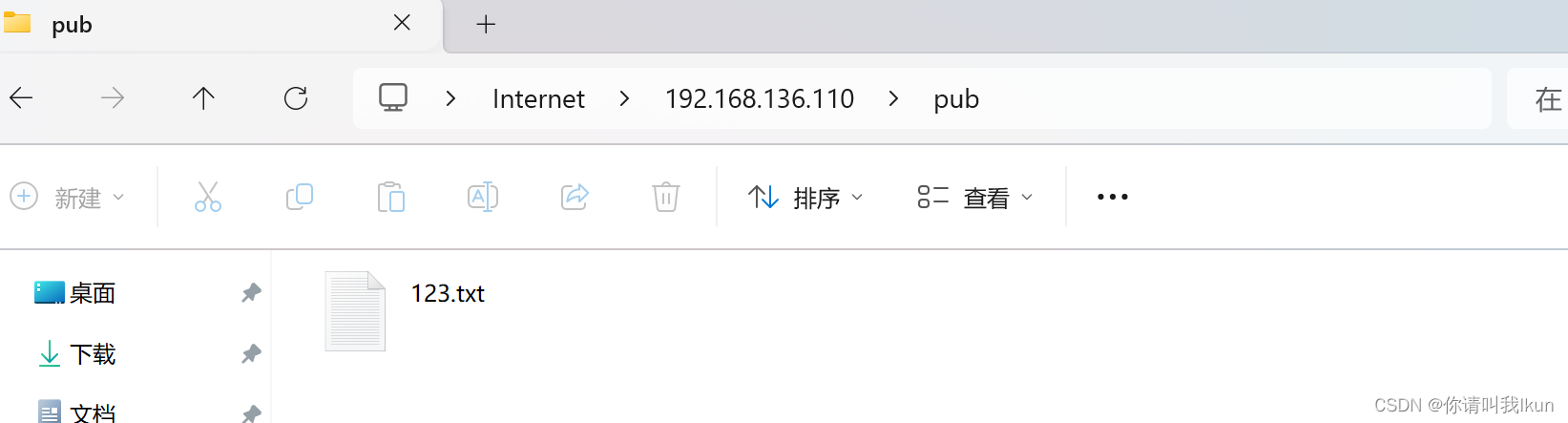
总结:
1. ftp的服务中有两个端口,一个20用于数据连接,一个21用户ftp传输控制指令。同时它使用的是TCP传输协议
2. ftp运用中可以又匿名登录和本地用户登录。匿名登录,没有密码限制,无法看清来访者,存在安全风险比较高。本地用户登录,也可以通过修改vsftp.conf 限制其切换目录。