门户网站需要多少费用wordpress手机不能显示字体
随着网络技术的发展,越来越多的游戏爱好者选择通过自建服务器来享受游戏的乐趣。幻兽帕鲁作为一款备受喜爱的游戏,也有不少玩家想要自建服务器进行游戏。而在选择服务器地点时,很多玩家会想到使用香港服务器。那么,是否可以使用香港服务器来搭建幻兽帕鲁自建服务器呢?
首先,我们来了解一下香港服务器的特点。香港服务器具有带宽充足、网络环境稳定、地理位置优越等优点,因此在搭建游戏服务器方面具有很大的优势。这也是为什么很多游戏爱好者选择香港服务器来搭建游戏服务器的原因为。
那么,回到正题,幻兽帕鲁自建服务器是否可以使用香港服务器呢?答案是肯定的。实际上,很多幻兽帕鲁自建服务器的玩家都选择了香港服务器作为他们的游戏服务器。这是因为香港服务器的网络环境稳定、带宽充足,能够满足幻兽帕鲁游戏的需求。同时,香港服务器的地理位置也十分优越,对于中国大陆的玩家来说,延迟相对较低,游戏体验更加流畅。
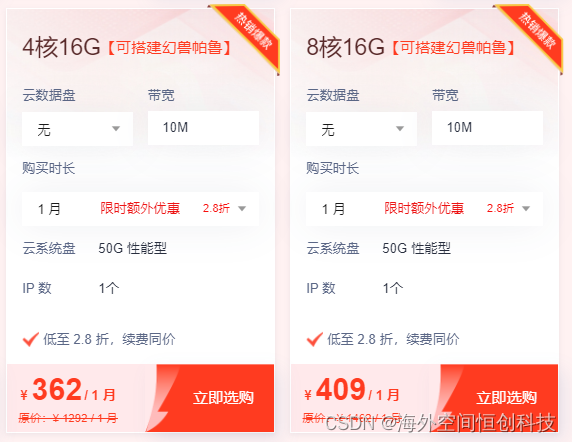
当然,选择使用香港服务器搭建幻兽帕鲁自建服务器也有一些需要注意的事项。首先,由于香港服务器的带宽和硬件配置较高,因此相应的成本也会比其他地区的服务器要高一些。其次,由于幻兽帕鲁游戏的特性,需要服务器的负载能力较强,因此在选择香港服务器时需要注意服务器的配置和性能是否能够满足游戏的需求。最后,还需要注意服务器的安全性和稳定性,确保游戏服务器的正常运行和玩家的游戏体验。
综上所述,幻兽帕鲁自建服务器可以使用香港服务器。选择使用香港服务器可以获得稳定的网络环境、充足的带宽和较低的延迟,能够满足幻兽帕鲁游戏的需求。但是在选择和使用香港服务器时,需要注意服务器的成本、配置和性能、安全性以及稳定性等方面的问题,以确保游戏服务器的正常运行和玩家的游戏体验。
对于想要自建幻兽帕鲁服务器的玩家来说,除了选择合适的服务器地点外,还需要注意服务器的硬件配置和软件设置等方面的问题。需要根据游戏的需求和服务器的性能进行合理的配置和优化,以确保服务器的稳定性和游戏的流畅性。同时,还需要注意服务器的安全问题,采取有效的安全措施,防止黑客攻击和服务器的数据泄露等安全风险。
总之,使用香港服务器搭建幻兽帕鲁自建服务器是一个不错的选择,但需要注意服务器的成本、配置和性能、安全性以及稳定性等方面的问题。只有选择合适的服务器和进行合理的配置和优化,才能保证游戏的流畅性和稳定性,为玩家带来更好的游戏体验。