防城港市建设工程质量监督站网站广告公司网站开发

文章目录
- Slice vs Map:基本概念
- 内存分配和性能
- Fasthttp 中的 SliceMap
- 性能优化的深层原因
- HTTP Headers 的特性
- CPU 预加载特性
- 结论
Fasthttp 是一个高性能的 Golang HTTP 框架,它在设计上做了许多优化以提高性能。其中一个显著的设计选择是使用 slice 而非 map 来存储数据,尤其是在处理 HTTP headers 时。
为什么呢?
本文将从简单到复杂,逐步剖析为什么 Fasthttp 选择使用 slice 而非 map,并通过代码示例解释这一选择背后高性能的原因
Slice vs Map:基本概念
首先,这个设计选择背后有着深思熟虑的考量,主要围绕性能优化展开。在深入探讨之前,我们需要理解 slice 和 map 在 Go 语言中的基本概念和性能特点。

- Slice:Slice 是对数组的封装,它提供了一个动态大小的、灵活的视图。Slices 的底层实际上是数组,这意味着它们的元素在内存中是连续存储的。
- Map:Map 是一种无序的键值对的集合,它通过哈希表实现。Map 提供了快速的查找、添加和删除操作,但这些操作的性能并不总是稳定。
内存分配和性能
在高性能的应用场景中,内存分配和回收是性能的关键因素之一。Fasthttp 在这方面做了优化:
Slice 的内存效率
由于 slice 的元素在内存中是连续存储的,它们访问速度快,且能有效利用 CPU 缓存。此外,slice 可以通过重新切片来复用已有的数组,减少内存分配和垃圾回收的压力。
Map 的内存开销
相比之下,map 的内存开销较大。在 map 中,键和值通常是散布在内存中的,这导致 CPU 缓存利用率不高。而且,map 的增长通常涉及重新哈希和重新分配内存,这些操作在性能敏感的应用中可能成为瓶颈。
Fasthttp 中的 SliceMap
Fasthttp 选择使用自定义的 sliceMap 结构来存储键值对,而非标准的 map。下面是 sliceMap 的一个简化版本和它的 Add 方法:
type kv struct {key []bytevalue []byte
}type sliceMap []kvfunc (sm *sliceMap) Add(k, v []byte) {kvs := *smif cap(kvs) > len(kvs) {kvs = kvs[:len(kvs)+1]} else {kvs = append(kvs, kv{})}kv := &kvs[len(kvs)-1]kv.key = append(kv.key[:0], k...)kv.value = append(kv.value[:0], v...)*sm = kvs
}
在这个设计中,sliceMap 通过以下方式优化性能:
减少内存分配
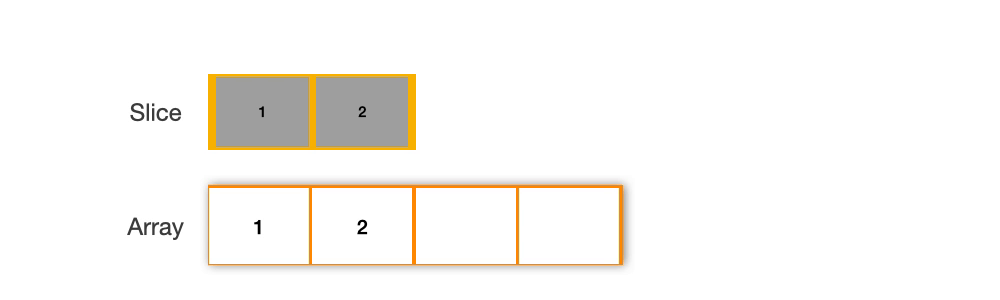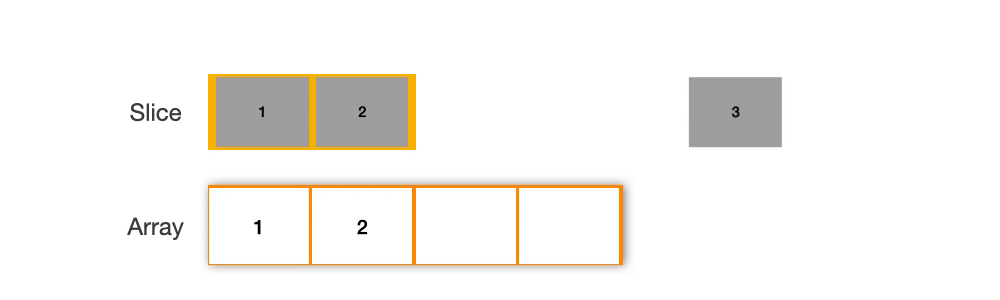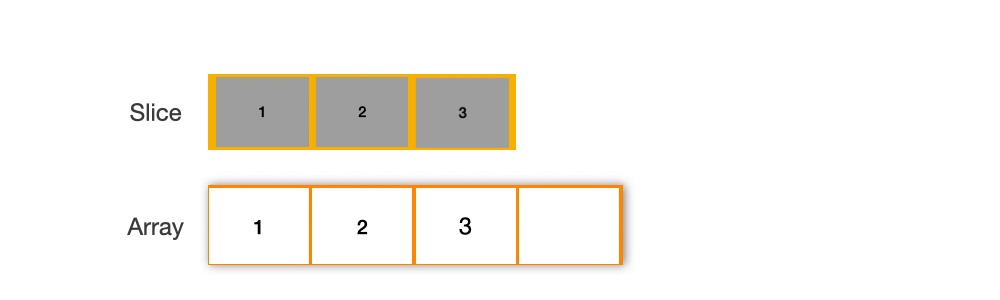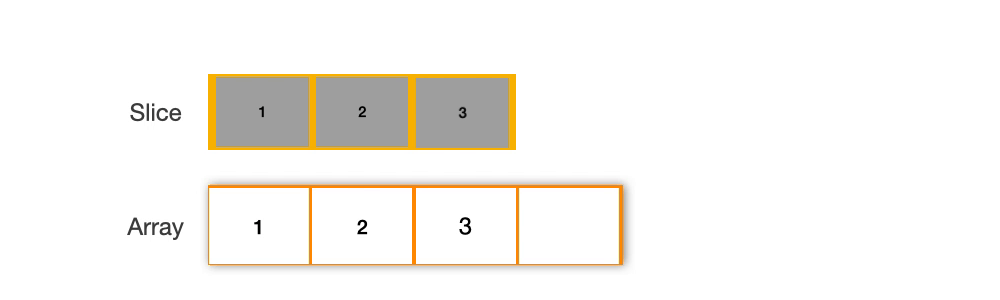
通过在现有的 slice 上进行操作,sliceMap 尽可能地复用内存。当容量足够时,它通过重新切片 kvs = kvs[:len(kvs)+1] 来扩展 slice,避免了额外的内存分配。
减少垃圾回收压力
由于 slice 的元素是连续存储的,它可以更有效地被垃圾回收器处理,减少了垃圾回收的开销。而且,由于内存是复用的,垃圾回收的次数也大大减少。
性能优化的深层原因
Fasthttp 使用 sliceMap 而非 map 的决策不仅仅是基于内存和性能的考量,还有更深层的原因:
HTTP Headers 的特性
在处理 HTTP 请求时,通常 headers、query 参数或 cookies 的数量并不多。这意味着即使使用线性搜索,查找效率也不会成为性能瓶颈。
相比之下,虽然 hash map 提供了理论上接近 O(1) 的查找效率,但实际使用中也有其开销和复杂性。
- 首先,hash map 的哈希计算本身就需要时间。
- 其次,哈希碰撞时,hash map 要额外处理来解决碰撞,这可能涉及到链表遍历或重新哈希等操作。
这些因素在元素数量较少时可能会抵消 hash map 在查找效率上的理论优势,而 slice 则才是更优质的选择。
CPU 预加载特性
由于 slice 的内存布局是连续的,它符合 CPU 缓存的工作原理,即一次性加载相邻数据。这种连续性使得 CPU 在访问一个 slice 元素后,能预加载相邻元素到缓存中,提高后续访问的速度。
因此,顺序访问 slice 时,缓存命中率高,减少了对主内存的访问次数,从而提高了性能。
结论
Fasthttp 的设计选择反映了对性能细节的深入理解和精心优化。通过使用 slice 而非 map,Fasthttp 在内存分配、垃圾回收以及 CPU 缓存利用等方面实现了优化,为高性能的 HTTP 应用提供了坚实的基础。这种设计不仅仅是技术上的选择,更是对实际应用场景和性能需求的深入洞察。