wordpress 文件权限设置,做网站和优化公司的宣传语,网站建设与运营课程总结,百度网站验证是前言
回滚提交到本地但是还没有 Push 上去的提交
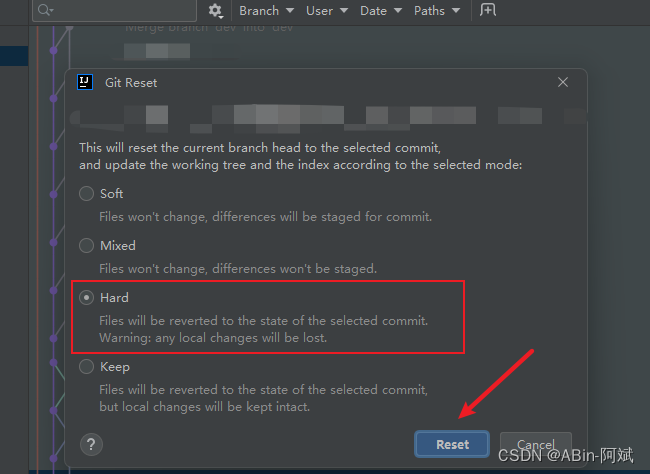
选择我们要回滚的节点,然后点击 git 选择 Reset Current Branch to… 再选择 Hard 。当我们点击 Reset 的时候,代码就会回滚到单前选中的这个版本前言
- 选择我们要回滚的节点,然后点击 git 选择 Reset Current Branch to… 再选择 Hard 。当我们点击 Reset 的时候,代码就会回滚到单前选中的这个版本