大网站制作公司微网站 和移动站
目录
按覆盖范围分类
个人区域网(PAN)
局域网(LAN)
城域网(MAN)
4. 广域网(WAN)
按使用场景和性质分类
公网(全球网络)
外网
内网(私有网络)
按传输介质和技术分类
有线网络
无线网络
特殊网络类型
虚拟局域网(VLAN)
存储区域网络(SAN)
网络桥接
接入网
按网络拓扑结构分类
总线型网络
星型网络
树型网络
环型网络
网状型网络
按交换方式分类
电路交换
报文交换
分组交换
按覆盖范围分类
个人区域网(PAN)
定义:个人区域网是一种短距离无线通信网络,用于连接个人设备,如智能手机、智能手表、无线耳机等。
技术:通常使用蓝牙、NFC(近场通信)等无线技术。
特点:
覆盖范围小,通常不超过10米。
设备间通信速度快,延迟低。
主要用于个人设备之间的数据传输和互联。
局域网(LAN)
定义:局域网是在有限地理区域内(如家庭、办公室、校园等)连接多台计算机和其他设备的网络。
技术:有线局域网通常使用以太网技术,无线局域网则使用Wi-Fi等技术。
特点:
传输速度快,延迟低。
易于配置和管理。
可以是有线或无线连接。
支持多种设备接入,如计算机、打印机、服务器等。
城域网(MAN)
定义:城域网是覆盖一个城市或城市周边地区的网络,用于连接多个局域网或提供城市范围内的数据传输服务。
技术:通常使用光纤、微波等高速传输技术。
特点:
覆盖范围较大,但小于广域网。
提供高速、可靠的数据传输服务。
支持多种业务应用,如电话、互联网、视频传输等。
4. 广域网(WAN)
定义:广域网是连接不同地理位置的局域网或其他网络的计算机网络,通常跨越城市、国家甚至全球。
技术:使用公共或专用线路(如光纤、卫星、微波等)作为传输介质。
特点:
覆盖范围广泛,可以连接全球范围内的网络。
提供远程通信和数据传输服务。
面临复杂的网络拓扑结构和传输挑战。
按使用场景和性质分类
公网(全球网络)
定义:公网是指连接全球范围内所有计算机、服务器和移动设备的庞大网络,如互联网。
特点:
开放性强,允许全球范围内的设备相互通信和数据传输。
提供丰富的资源和服务,如电子邮件、网页浏览、文件传输等。
面临安全挑战,需要采取多种安全措施来保护数据传输和隐私。
外网
定义:外网是指连接不同局域网或其他外网的公共网络,用于实现远程通信和数据共享。
特点:
通常与公网重叠,但更侧重于连接不同地点的局域网。
提供远程访问和数据传输服务,如VPN(虚拟专用网络)等。
需要采取安全措施来保护数据传输和隐私。
内网(私有网络)
定义:内网是指仅允许组织内部设备访问的受限网络。
特点:
安全性高,提供内部资源的共享和保护。
可以是局域网的一部分或整个组织内部的网络。
需要采取访问控制和安全措施来保护内部资源。
按传输介质和技术分类
有线网络
定义:有线网络是通过物理线缆(如双绞线、同轴电缆、光纤等)连接设备的网络。
技术:以太网、同轴电缆网络等。
特点:
传输速度快,稳定性好。
布线复杂,需要专业的安装和维护。
移动性差,设备位置固定。
无线网络
定义:无线网络是通过无线信号(如Wi-Fi、蓝牙等)连接设备的网络。
技术:Wi-Fi、蓝牙、Zigbee等。
特点:
便捷灵活,覆盖范围广。
易于部署和使用。
但易受干扰和攻击,安全性相对较低。
特殊网络类型
虚拟局域网(VLAN)
定义:虚拟局域网是一种通过逻辑方式将局域网设备划分为多个虚拟网段的技术。
特点:
提高网络性能和资源利用率。
实现隔离和安全性,防止广播风暴和恶意攻击。
不受物理拓扑限制,易于配置和管理。
存储区域网络(SAN)
定义:存储区域网络是一种将存储设备共享池连接到多个服务器的专用高速网络。
特点:
提供高性能的数据存储和访问能力。
支持数据备份、恢复和灾难恢复等功能。
适用于大型企业和数据中心等需要高效数据存储和管理的场景。
网络桥接
定义:网络桥接是一种连接不同网络段的技术,用于扩展网络范围或简化配置。
特点:
实现跨物理位置的设备通信和数据传输。
简化IP地址管理,提高网络连通性。
可以用于连接不同类型的网络(如有线和无线)。
综上所述,网络类型繁多且各具特色。在选择和使用网络类型时,需要根据实际需求和环境条件进行综合考虑,以确保网络的稳定性、安全性和高效性。
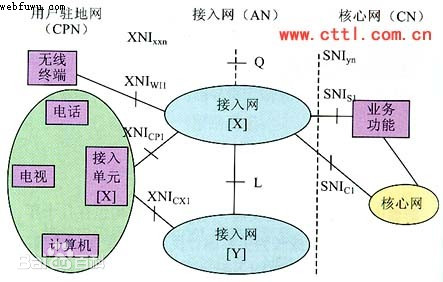
接入网
定义:接入网是骨干网络到用户终端之间的所有设备组成的网络,它通常被称为“最后一千米”网络。
特点:
接入方式多样,包括铜线、光纤、光纤同轴电缆混合接入和无线接入等。
是整个网络系统的瓶颈,因为骨干网通常采用光纤结构,传输速度快,而接入网的传输速度相对较慢。
按网络拓扑结构分类
总线型网络
定义:总线型网络是由一条高速共享总线连接多个节点形成的网络。
特点:
结构简单灵活,易于扩充。
信道利用率高,但容易产生访问冲突。
传输速率高,但可靠性相对较差。
星型网络
定义:星型网络是以中央节点为中心,多个节点通过点到点的方式与中央节点连接形成的网络。
特点:
网络结构简单,便于管理和控制。
延迟较小,误码率较低。
但网络共享能力较差,通信线路利用率不高。
树型网络
定义:树型网络是将多级星型网络按层次方式排列形成的网络。
特点:
结构简单,成本低。
节点扩充方便灵活,路径选择简单。
但除叶子节点及其相连的链路外,其他节点或链路故障会影响整个网络。
环型网络
定义:环型网络中的各个节点通过环路接口连接在一条首尾相连的闭合环型通信线路中。
特点:
信息或数据在网络中沿固定方向流动,路径唯一。
可靠性较高,可以自动旁路故障节点。
但当节点过多时,网络响应时间会变长。
网状型网络
定义:网状型网络中的各节点之间的连接呈网状交错,节点之间存在多条路径可达。
特点:
可靠性高,传输时延小。
资源易于共享,控制复杂。
适用于广域网等大规模网络。
按交换方式分类
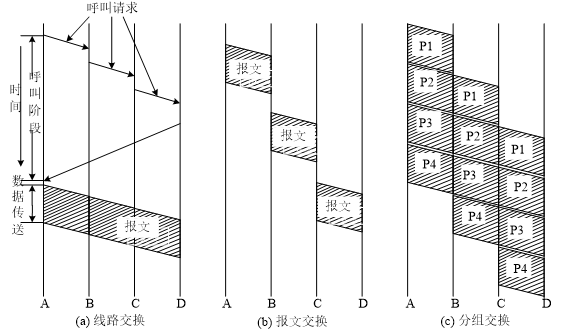
电路交换
定义:电路交换是以电路连接为交换目的的通信方式,通信双方必须在建立连接后才能开始通信。
特点:
建立连接时间长,线路利用率低。
一旦建立连接,就独占线路,无纠错机制。
但传输延迟小,适用于实时性要求高的通信。
报文交换
定义:报文交换不需要在两个通信节点之间建立专用通道,节点将需要发送的信息组成数据报文,通过存储/转发的方式在网络中传输。
特点:
报文大小不一,造成缓冲区管理复杂。
大报文传输延迟长,存储转发效率低。
出错后整个报文需要重发,可靠性较低。
分组交换
定义:分组交换是将数据分成多个分组进行传输的交换方式,每个分组包含用户数据块、目的地址和管理信息。
特点:
存储量要求小,转发速度快。
转发延迟小,适用于交互式通信。
若某个分组出错,则仅重发该分组,效率高。
各分组可通过不同路径传输,可靠性高。
数据传输前不需要建立端到端的通路,灵活性高。
有强大的纠错机制、流量控制和路由选择功能。