常州网站建设开发云 wordpress
内容来源于:易道云信息技术研究院VIP课
项目需求:
为游戏增加VIP功能-自动化助手。自动化助手做的是首先要说一下背景,对于授权游戏来讲它往往年限都比较老,老游戏和新游戏设计理念是不同的,比如说老游戏基本上在10年以前的游戏它设计的时候都是你要玩命的练级、打怪、打装备就这样大量的消耗我们的时间,但是我们现在的10年以后的新的游戏国产游戏设计理念是它是要求每个人差距都是相同的,就是我们之间是没有差距的,就是只要你每天上来玩三个小时大家都一样,没有高低差距,将来的差距主要体现在技术方面,但授权游戏不是这样的,授权游戏因为是老游戏,所以它还是要练级、打怪,但是想一下有谁能手动的在这个年代手动的打怪坚持下来,这是不可能的没有人能坚持,所以就迎来的我们现在的这个需求,如果它手动打怪不可能,将来用户最大的选择就是去卖外挂,既然它去买外挂,所以我们游戏的运营方说既然你要去买外挂,那我还不如去提供给你一个比较好用的自动化助手,来帮助你能够快速的练级,这样的话我也能够保证功能在可控范围内,现在靶场游戏当年它们在运营这款游戏的时候,它们也是这样做的,到这就能明白要做的自动化助手大概是个什么东西了,但是现阶段只做界面,只实现自动化助手的显示,后续会慢慢的扩充自动化助手,帮助玩家有一个更好的游戏体验,游戏中本身是有一个辅助性的设定的,但是它比较鸡肋,如果是非vip它还是只能用游戏本身的自动化药水\(图1),如果是vip当再按自动化药水设定的时候就显示,我们全新的功能,就是我们提供的自动化助手功能,也就是当是vip时就把原本的自动化药水按钮改成自动化助手[vip],对于非vip,就还是叫原来的自动化药水,使用自动化药水功能时就弹出一个提示,可以开通vip使用更高级的自动化助手功能,就是说对于非vip的玩家来说你得告诉它你有这个东西你得去买
需求拆解:
第一个功能:
首先找到自动化药水按钮的功能在什么地方,自动化药水还有快捷键(T键)所以它是有两个接口,所以除了要处理按钮点击还要处理快捷键的点击,然后它还有个接口如图3。所以它是一共有三个入口点,所以接下来要去分析每一个入口点,这里有一个技巧,就是三个入口点它会不会为每个入口点单独设计一套功能,它们三个界面都是一样的所以本质上它们三个都还是调用的一个地方,但是这三个地方的调用逻辑往往是不一样的,尤其是快捷键的逻辑更是不一样的,所以要有一个基本的概念,这三个不管逻辑再不一样,开头可能不一样,往底层是一定会调用一个共同的地方,所以我们只需要在共同的地方看有没有机会去做一个统一的处理,这样的效果是最好的,做处理就是根据是不是vip来处理,如果不是vip就继续运行原本的代码,如果是vip这个时候就要弹出我们自己的窗口,这样第一个功能就搞定了。
第二个功能:
第二个功能修改菜单比较麻烦,有两个方法,第一个方法这个自动药水设定数据是存在客户端里,在客户端里一定有个文本文档或者有一个配置文件留了界面上的一些东西,它加载游戏的时候它一定是把这个数据给加载进来最后通过某种索引或者某种东西,来把这个东西加载进来,就这样的一种方式,首先找到客户端的文本文档就能修改客户端,客户端的文件是压缩了的首先要解压,但解压它是有自己的算法的,需要自己写解压。第二个方式,启动的时候它会加载相关的配置文件到内存里,然后自动化药水设定是一个ui、是一个按钮,按钮上的文本和内存里的数据它一定有就是按钮初始化的时候一定要根据内存里,把这个内存里的文本读到按钮里,一定有这样的一个过程,我们就要找这个过程,然后从这个过程里下手脚,然后游戏它读文本内存的时候一定会想办法访问这块内存,然后游戏怎样得到这个内存我们就怎样得到这个内存,我们得到内存之后就可以随意的修改文本了。
第三个功能:
找到游戏中信息提示的接口,实现我们想要的信息,比如玩家不是vip,我们要弹框提示它我们有自动化助手,如果弹一个MessageBox这样就很掉价很不和谐,如果用图4里的提示效果就会比MessageBox好很多,我们未必能调用图4的提示,但要尽量努力去用这样的方式。
图1:

通过判断血量然后按快捷栏里的东西,快捷栏如图2:

图2:下图红框里是快捷栏,也就是自动化药水是通过把药水放到快捷栏上,通过快捷栏来操作,这是游戏本身的一个功能
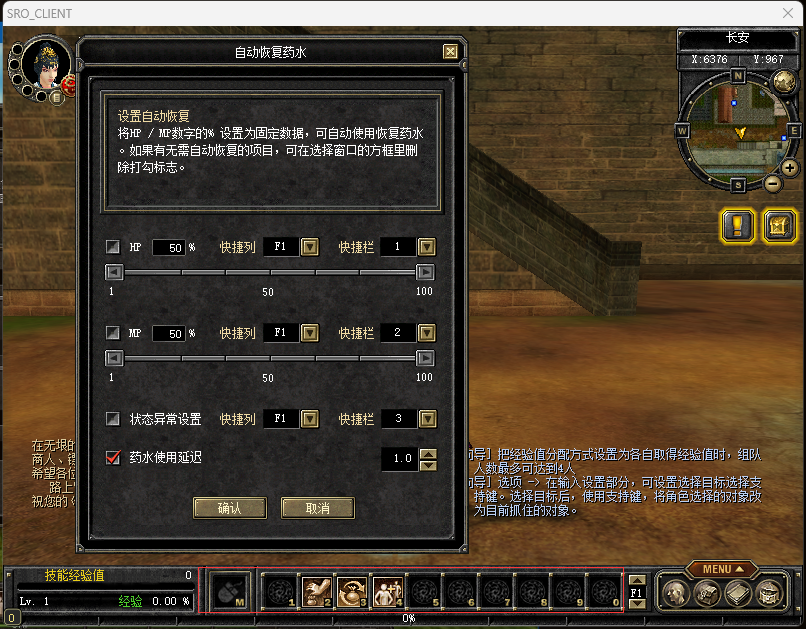
图3:
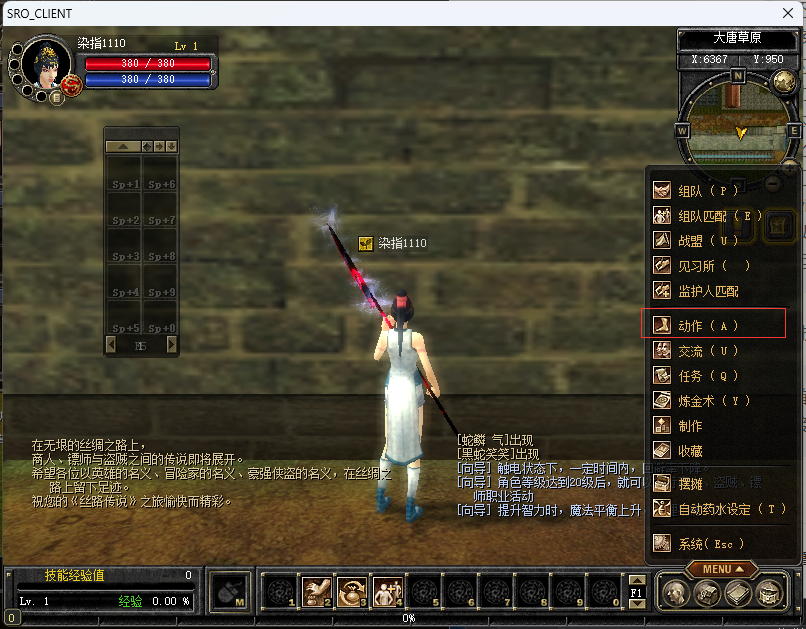
通过鼠标右键点击也可以弹出自动化药水
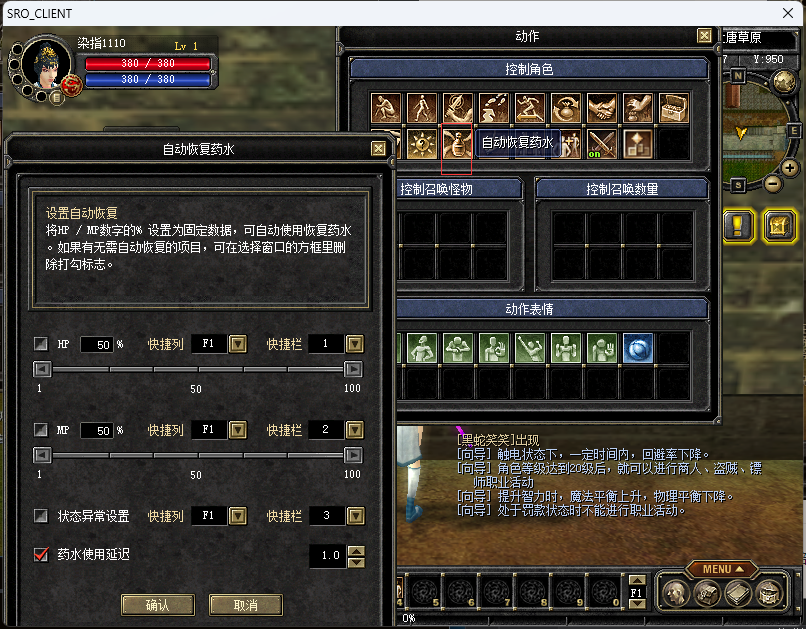
图4:

