安庆网站建设哪家好今天上海新闻综合新闻
1、下载
下载地址:下载 IntelliJ IDEA – 领先的 Java 和 Kotlin IDE

下载完成:

idea破解脚本下载链接:https://pan.baidu.com/s/1L5qq26cRABw8XuEn_CngKQ
提取码:6666
下载完成:

2、安装
1、双击idea的安装包,点击next

2、更改安装路径

3、根据需求勾选
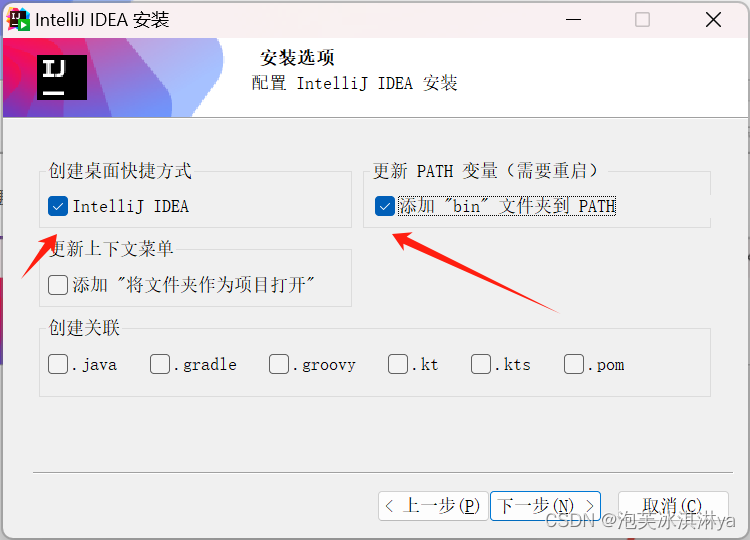
4、默认设置直接安装


5、安装完成选择稍后手动启动

3、破解
1、双击破解脚本如下图选择

2、点击browse选择idea安装路径下的 bin->idea64.exe文件


3、点击active激活

4、点击yes
出现以下界面即为破解成功:
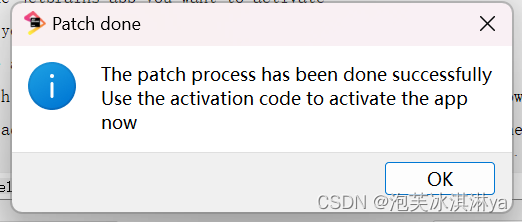
5、点击copy code 复制 激活码

6、进入到idea里面点击激活
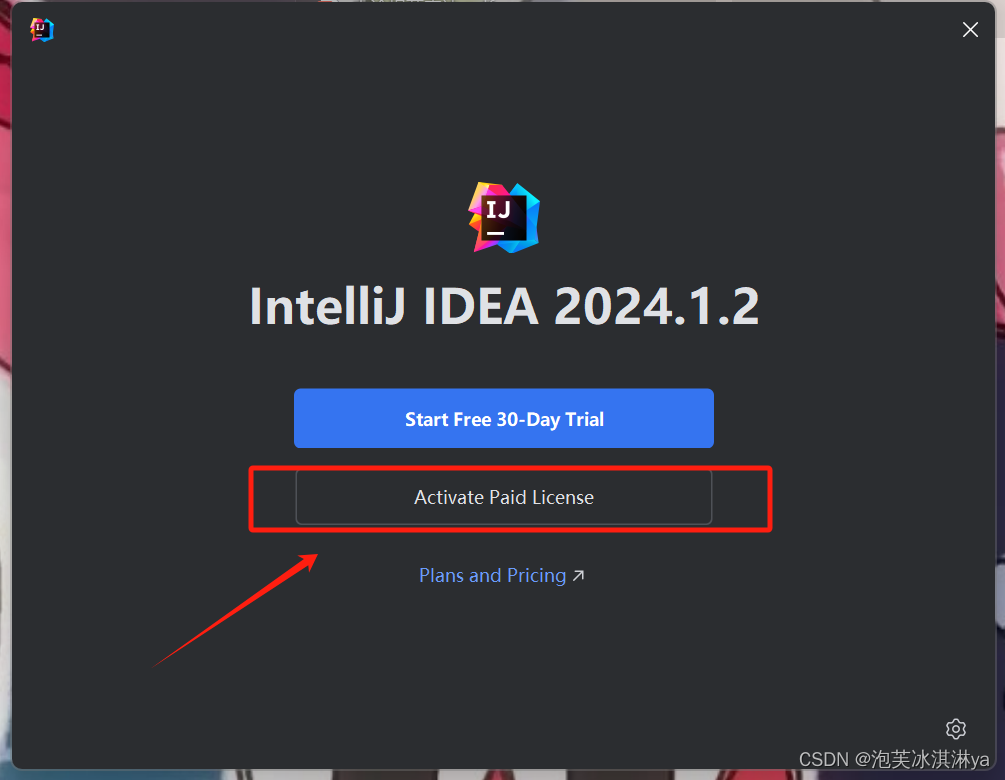
7、 直接粘贴 之前复制的激活码

8、激活成功

4、注意事项
激活成功后,不要升级IDEA版本,因为升级后需要重新破解!
激活成功后,补丁文件夹不要删除/移动!