济南网站建设找聚搜网络大连百姓网免费发布信息网站
AEC-Q101车规认证是一种基于失效机制的分立半导体应用测试认证规范。它是为了确保在汽车领域使用的分立半导体器件能够在严苛的环境条件下正常运行和长期可靠性而制定的。AEC-Q101认证包括一系列的失效机制和应力测试,以验证器件在高温、湿度、振动等恶劣条件下的可靠性。

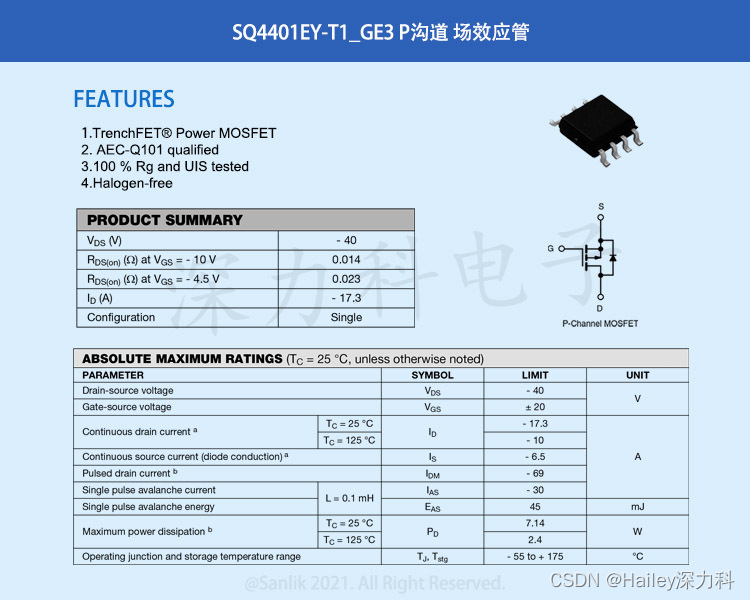
40V汽车级p沟道TrenchFET®功率MOSFET---SQ4401EY-T1_GE3,功率耗散最大值7.14W,采用8-SOIC(0.154",3.90mm 宽)封装,有效提升板级可靠性。SQ4401EY-T1_GE3通过AEC-Q101认证,节省PCB空间并降低成本,同时导通电阻低于其他封装MOSFET。
广泛的应用领域可用做消费电子、计算机及外设、网络通信、汽车电子、LED显示屏,手机,平板电脑等便携式设备中的负载开关。