山西响应式网站设计国内免费saas+crm
AHP权重计算:
需求:前端记录矩阵维度、上三角值,后端构建比较矩阵、计算权重值并将结果返回给前端
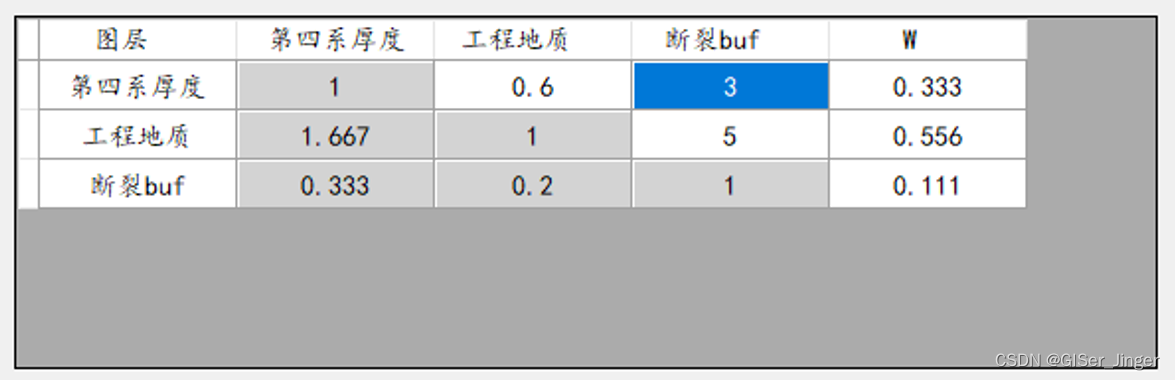
比较矩阵构建
如果你想要根据上三角(不包括对角线)的值来构建对称矩阵,那么你可以稍作修改上述的
generate_symmetric_matrix函数。在这个情况下,你将从矩阵的左上角开始填充上三角的值,然后利用对称性填充下三角的值。
def generate_symmetric_matrix_from_upper(i, upper_triangle_values): """ 根据上三角(不包括对角线)的值和矩阵维度生成对称矩阵 :param i: 矩阵的维度(i x i) :param upper_triangle_values: 上三角(不包括对角线)的值列表 :return: 生成的对称矩阵 """ if len(upper_triangle_values) > i * (i - 1) // 2: raise ValueError("提供的上三角值数量超过了上三角(不包括对角线)的元素总数。") # 初始化矩阵 matrix = [[1] * i for _ in range(i)] # 对角线初始化为1 # 填充上三角(不包括对角线)的值 index = 0 for row in range(i): for col in range(row + 1, i): # 从当前行的下一个元素开始(跳过对角线) matrix[row][col] = upper_triangle_values[index] index += 1 # 填充下三角的值(利用对称性) for row in range(i): for col in range(row): # 只遍历到当前行的前一个元素(不包括对角线) matrix[row][col] = 1/matrix[col][row] # 下三角的值等于上三角的值 return matrix # 示例使用
i = 3 # 矩阵维度
upper_triangle_values = [0.6, 3, 5] # 上三角(不包括对角线)的值
matrix = generate_symmetric_matrix_from_upper(i, upper_triangle_values) # 打印矩阵
for row in matrix: print(row)
- 在这个函数中,我们首先检查提供的上三角值的数量是否超过了实际需要的数量。然后,我们初始化一个所有对角线元素都为1的矩阵。接着,我们遍历上三角(不包括对角线)并填充提供的值。最后,我们利用对称性来填充下三角的值。
- 当你运行这个示例时,它将输出一个3x3的对称矩阵,其中上三角的值由
upper_triangle_values列表提供,而下三角的值则通过对称性从上三角复制而来。对角线上的值保持为1。
AHP权重计算
层次分析法(Analytic Hierarchy Process, AHP)是一种常用的多属性决策方法,它允许决策者将复杂的决策问题分解为多个子问题或属性,并通过两两比较的方式来确定这些子问题或属性的相对重要性。以下是一个简化的Python示例,展示了如何使用层次分析法求解权重值:
- 构造判断矩阵(通过专家打分等方式)
- 一致性检验
- 求解权重值
import numpy as np def calculate_consistency_ratio(ci, n): # 一致性指标RI的值与n(判断矩阵的阶数)有关 ri_values = { 1: 0.0, 2: 0.0, 3: 0.58, 4: 0.9, 5: 1.12, 6: 1.24, 7: 1.32, 8: 1.41, 9: 1.45, 10: 1.49 } ri = ri_values[n] cr = ci / ri return cr def calculate_ci(matrix): # 计算一致性指标CI n = matrix.shape[0] eigenvalues, _ = np.linalg.eig(matrix) max_eigenvalue = np.max(eigenvalues) ci = (max_eigenvalue - n) / (n - 1) return ci def calculate_weights(matrix): # 计算权重值 eigenvalues, eigenvectors = np.linalg.eig(matrix) max_eigenvalue = np.max(eigenvalues) max_eigenvector = eigenvectors[:, eigenvalues == max_eigenvalue] weights = max_eigenvector.flatten().real / np.sum(max_eigenvector.flatten().real) return weights def ahp_analysis(matrix): # AHP分析主函数 n = matrix.shape[0] ci = calculate_ci(matrix) cr = calculate_consistency_ratio(ci, n) if cr < 0.1: # 一般情况下,当CR<0.1时,认为判断矩阵的一致性是可以接受的 weights = calculate_weights(matrix) print("一致性检验通过,权重值为:", weights) else: print("一致性检验未通过,需要重新调整判断矩阵") # 示例判断矩阵(假设) # 注意:这里的判断矩阵应该是通过专家打分或其他方式构造的,并且应该满足互反性 A = np.array([ [1, 3, 5], [1/3, 1, 3], [1/5, 1/3, 1] ]) ahp_analysis(A)注意:
- 上述代码中的判断矩阵
A是假设的,实际应用中需要根据实际情况构造。- 一致性检验的阈值通常是0.1,但也可以根据具体需求进行调整。
- 判断矩阵的构造应该遵循AHP方法的规则,即对角线元素为1,且满足互反性(即
A[i][j] = 1 / A[j][i])。- 权重值是通过求解判断矩阵的最大特征值对应的特征向量得到的,并且需要对该特征向量进行归一化处理。
前后端设计
在前后端通信中,当前端需要传递两个参数给后端,其中一个参数是数组,另一个是int类型时,你需要在前端正确地构造请求,并在后端Flask应用中设计相应的路由和请求处理函数来接收这些参数。
前端(JavaScript 使用 fetch API)
假设你正在使用JavaScript的fetch API来发送POST请求,你可以将数组和int值作为JSON对象的一部分发送。这里是一个例子:
// 假设你的后端API的URL是'http://example.com/api/data'
const arrayParam = [1, 2, 3]; // 数组参数
const intParam = 42; // int类型参数 // 将参数包装在一个对象中
const dataToSend = { arrayParam: arrayParam, intParam: intParam
}; // 将对象转换为JSON字符串
const jsonData = JSON.stringify(dataToSend); fetch('http://example.com/api/data', { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: jsonData
})
.then(response => response.json())
.then(data => console.log(data))
.catch((error) => { console.error('Error:', error);
});后端(Flask)
在后端,你需要在Flask应用中创建一个路由,并使用request.json来获取前端发送的JSON数据。这里是一个例子:
from flask import Flask, request, jsonify app = Flask(__name__) @app.route('/api/data', methods=['POST'])
def receive_data(): if request.method == 'POST': # 从JSON中解析参数 array_param = request.json.get('arrayParam', []) # 默认值为空数组 int_param = request.json.get('intParam', None) # 默认值为None,你可以根据需要设置默认值 # 检查int_param是否为int类型 if int_param is not None and not isinstance(int_param, int): return jsonify({'error': 'intParam must be an integer'}), 400 # 在这里处理你的数据... # 例如,你可以返回接收到的参数作为确认 return jsonify({'message': 'Data received!', 'arrayParam': array_param, 'intParam': int_param}), 200 else: return jsonify({'error': 'Invalid request method'}), 405 if __name__ == '__main__': app.run(debug=True)在这个例子中,
receive_data函数首先检查请求方法是否为POST。然后,它从request.json中获取arrayParam和intParam。注意,我使用了get方法来安全地获取这些值,并为它们提供了默认值(对于arrayParam是一个空数组,对于intParam是None)。然后,它检查intParam是否是一个整数,如果不是,则返回一个错误响应。最后,它返回一个包含接收到的参数的JSON响应。
postman测试:
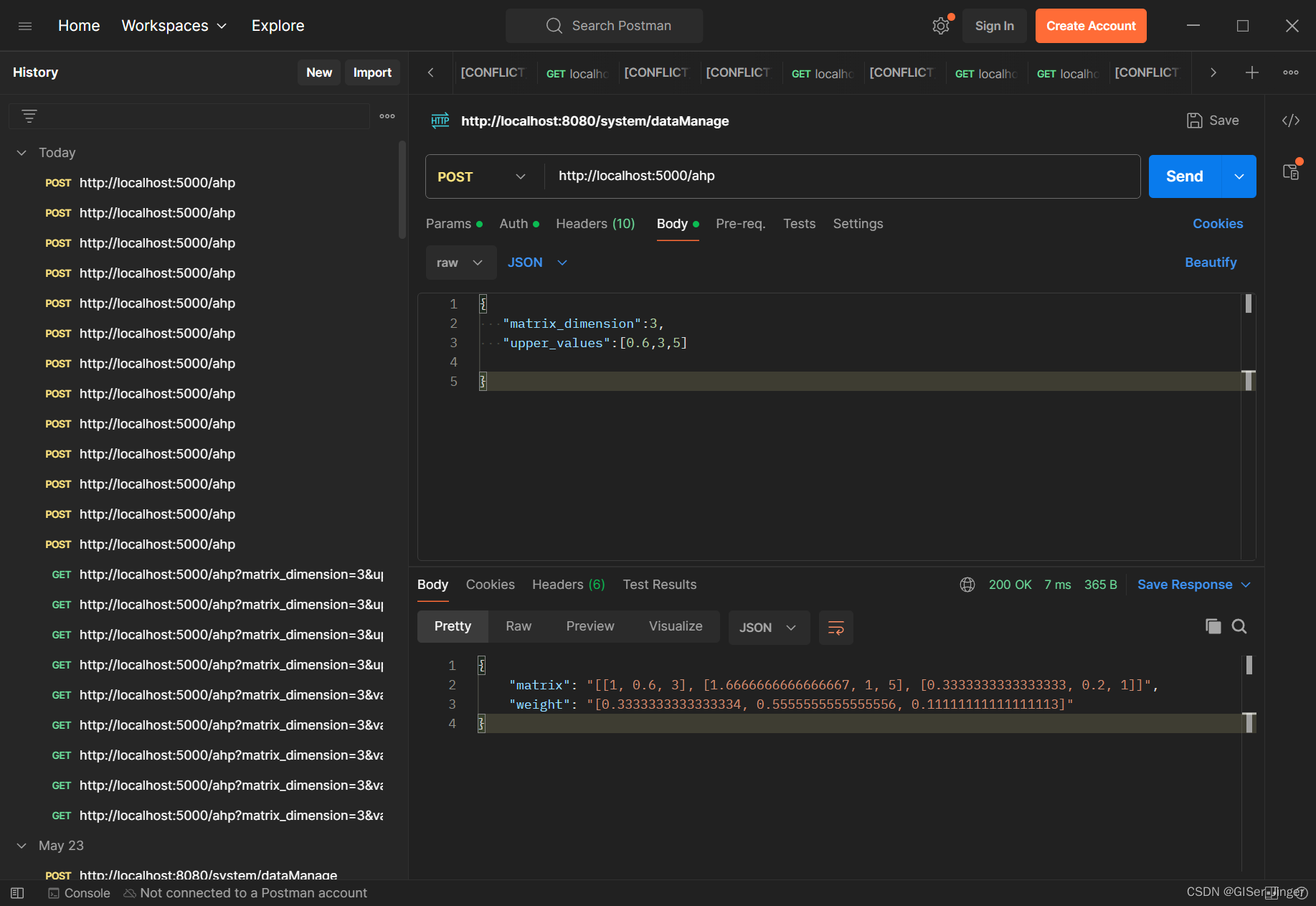
后端模块与接口 :
AHP.py
import jsonimport numpy as npdef calculate_consistency_ratio(ci, n):# 一致性指标RI的值与n(判断矩阵的阶数)有关ri_values = {1: 0.0, 2: 0.0, 3: 0.58, 4: 0.9, 5: 1.12,6: 1.24, 7: 1.32, 8: 1.41, 9: 1.45, 10: 1.49}ri = ri_values[n]cr = ci / rireturn crdef calculate_ci(matrix):# 计算一致性指标CIn = matrix.shape[0]eigenvalues, _ = np.linalg.eig(matrix)max_eigenvalue = np.max(eigenvalues)ci = (max_eigenvalue - n) / (n - 1)return cidef calculate_weights(matrix):# 计算权重值eigenvalues, eigenvectors = np.linalg.eig(matrix)max_eigenvalue = np.max(eigenvalues)max_eigenvector = eigenvectors[:, eigenvalues == max_eigenvalue]weights = max_eigenvector.flatten().real / np.sum(max_eigenvector.flatten().real)return weightsdef ahp_analysis(matrix):# AHP分析主函数n = matrix.shape[0]ci = calculate_ci(matrix)cr = calculate_consistency_ratio(ci, n)if cr < 0.1: # 一般情况下,当CR<0.1时,认为判断矩阵的一致性是可以接受的weights = calculate_weights(matrix)print("一致性检验通过,权重值为:", weights)else:print("一致性检验未通过,需要重新调整判断矩阵")return weightsdef generate_symmetric_matrix_from_upper(i, upper_triangle_values):"""根据上三角(不包括对角线)的值和矩阵维度生成对称矩阵:param i: 矩阵的维度(i x i):param upper_triangle_values: 上三角(不包括对角线)的值列表:return: 生成的对称矩阵"""if len(upper_triangle_values) != i * (i - 1) / 2:raise ValueError("提供的上三角值数量不匹配。")# 初始化矩阵matrix = [[1] * i for _ in range(i)] # 对角线初始化为1# 填充上三角(不包括对角线)的值index = 0for row in range(i):for col in range(row + 1, i): # 从当前行的下一个元素开始(跳过对角线)matrix[row][col] = upper_triangle_values[index]index += 1# 填充下三角的值(利用对称性)for row in range(i):for col in range(row): # 只遍历到当前行的前一个元素(不包括对角线)matrix[row][col] = 1/matrix[col][row] # 下三角的值等于上三角的值return matrix# 方法,前端传来矩阵维数+上三角值【row1Value1,row1Value2,row2Value2】数组,自动生成矩阵并返回AHP分析结果值
def cal_AHP_res(matrixDimension,upper_triangle_values):matrix = generate_symmetric_matrix_from_upper(matrixDimension,upper_triangle_values)A = np.array(matrix)matrix_res=json.dumps(matrix)arr= ahp_analysis(A)# 将其转换为 Python 列表list_arr = arr.tolist()# 将列表转换为 JSON 字符串res = json.dumps(list_arr)return matrix_res,resif __name__ == '__main__':# 生成矩阵示例i = 3 # 矩阵维度upper_triangle_values = [3, 0.75, 0.5] # 上三角(不包括对角线)的值matrix_res, res=cal_AHP_res(i,upper_triangle_values)//flask接口
@app.route('/ahp', methods=['POST'])
def getAHPRes():matrix_dimension=request.json.get('matrix_dimension')value = request.json.get('upper_values',[]) # 获取数值型值 valuesprint(len(value))matrix,weight= cal_AHP_res(matrix_dimension,value)return jsonify({'matrix': matrix,'weight':weight})