哈尔滨双城区建设局网站外贸soho网站
文章目录
- 1. 安装Docker
- 2. 使用Docker拉取Excalidraw镜像
- 3. 创建并启动Excalidraw容器
- 4. 本地连接测试
- 5. 公网远程访问本地Excalidraw
- 5.1 内网穿透工具安装
- 5.2 创建远程连接公网地址
- 5.3 使用固定公网地址远程访问
本文主要介绍如何在Ubuntu系统使用Docker部署开源白板工具Excalidraw,并结合cpolar内网穿透工具实现公网远程访问绘制流程图。
Excalidraw是一款手绘风格流程图、示意图、架构图在线绘制工具,界面简洁,交互细致,上手简单,操作习惯和大部分制图软件相似。使用Docker部署Excalidraw容器非常简单,只需一行命令即可快速实现本地部署。
1. 安装Docker
本教程操作环境为Linux Ubuntu系统,在开始之前,我们需要先安装Docker。
在终端中执行下方命令:
添加Docker源
# Add Docker's official GPG key:
sudo apt-get update
sudo apt-get install ca-certificates curl gnupg
sudo install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg# Add the repository to Apt sources:
echo \"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
安装Dokcer包
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
通过运行映像来验证 Docker 引擎安装是否成功
sudo docker run hello-world
2. 使用Docker拉取Excalidraw镜像
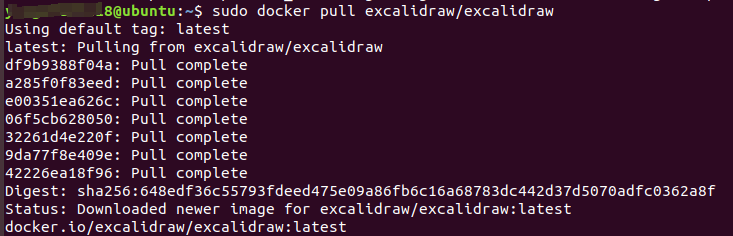
sudo docker pull excalidraw/excalidraw
然后执行查看镜像命令:
sudo docker images
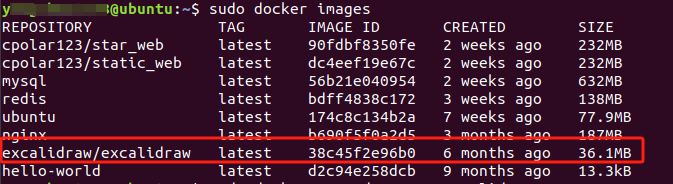
可以看到成功拉取了Excalidraw镜像。
3. 创建并启动Excalidraw容器
成功拉取Excalidraw镜像后,我们可以使用该镜像创建并运行一个Excalidraw容器。
在终端执行以下命令:
$ sudo docker run -d --name excalidraw -p 5000:80 excalidraw/excalidraw
参数说明:
- –name excalidraw:本例容器名称为excalidraw,大家可以自己起名。
- -p 5000:80: 端口进行映射,将本地 5000 端口映射到容器内部的 80 端口。
- **-d ** :设置容器在在后台一直运行。

然后执行下方命令查看容器是否正在运行:
sudo docker ps

可以看到刚才创建的Excalidraw容器正在运行中。
4. 本地连接测试
现在我们可以通过浏览器直接访问 localhost:5000 端口的 Excalidraw 服务:
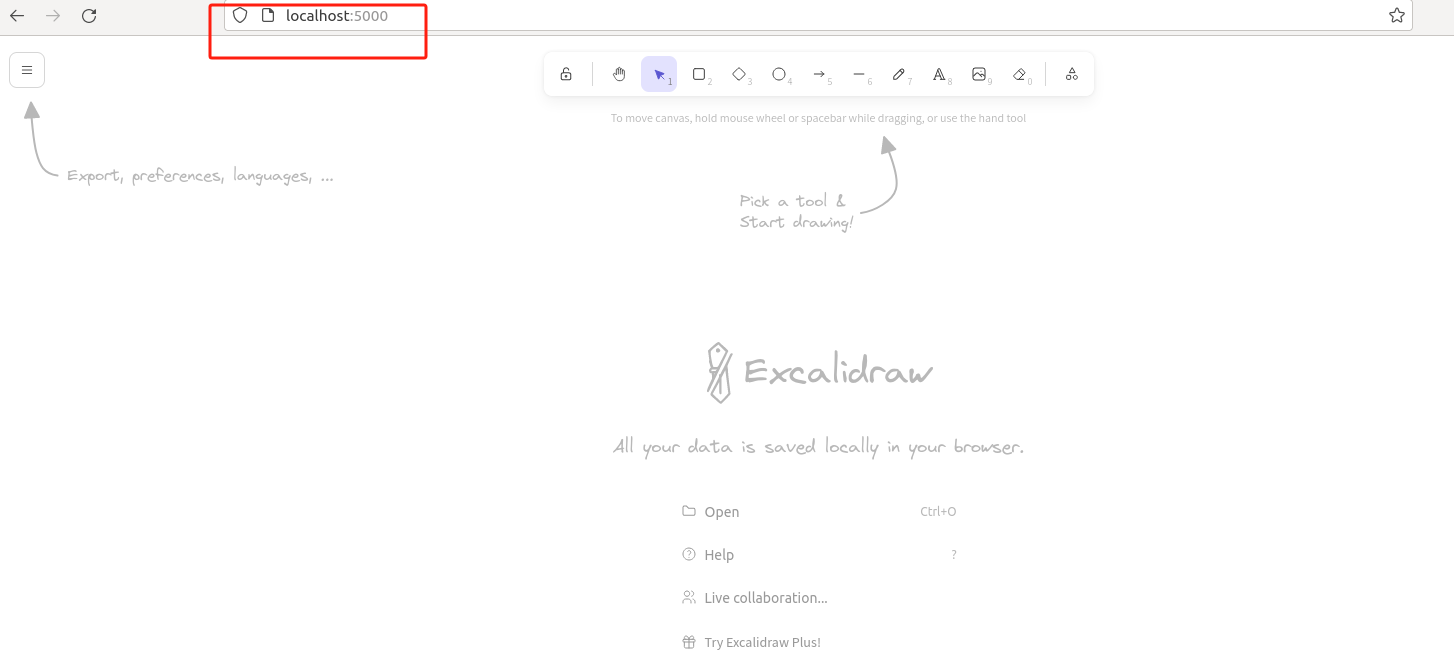
可以看到,本地连接 Excalidraw 服务测试成功。
5. 公网远程访问本地Excalidraw
不过我们目前只能在本地连接刚刚使用docker部署的Excalidraw服务,如果身在异地,想要远程访问在本地部署的Excalidraw容器,但又没有公网ip怎么办呢?
我们可以使用cpolar内网穿透工具来实现无公网ip环境下的远程访问需求。
5.1 内网穿透工具安装
下面是安装cpolar步骤:
cpolar官网地址: https://www.cpolar.com
- 使用一键脚本安装命令
curl -L https://www.cpolar.com/static/downloads/install-release-cpolar.sh | sudo bash
- 向系统添加服务
sudo systemctl enable cpolar
- 启动cpolar服务
sudo systemctl start cpolar
cpolar安装成功后,在外部浏览器上访问Linux 的9200端口即:【http://服务器的局域网ip:9200】,使用cpolar账号登录,登录后即可看到cpolar web 配置界面,结下来在web 管理界面配置即可。
5.2 创建远程连接公网地址
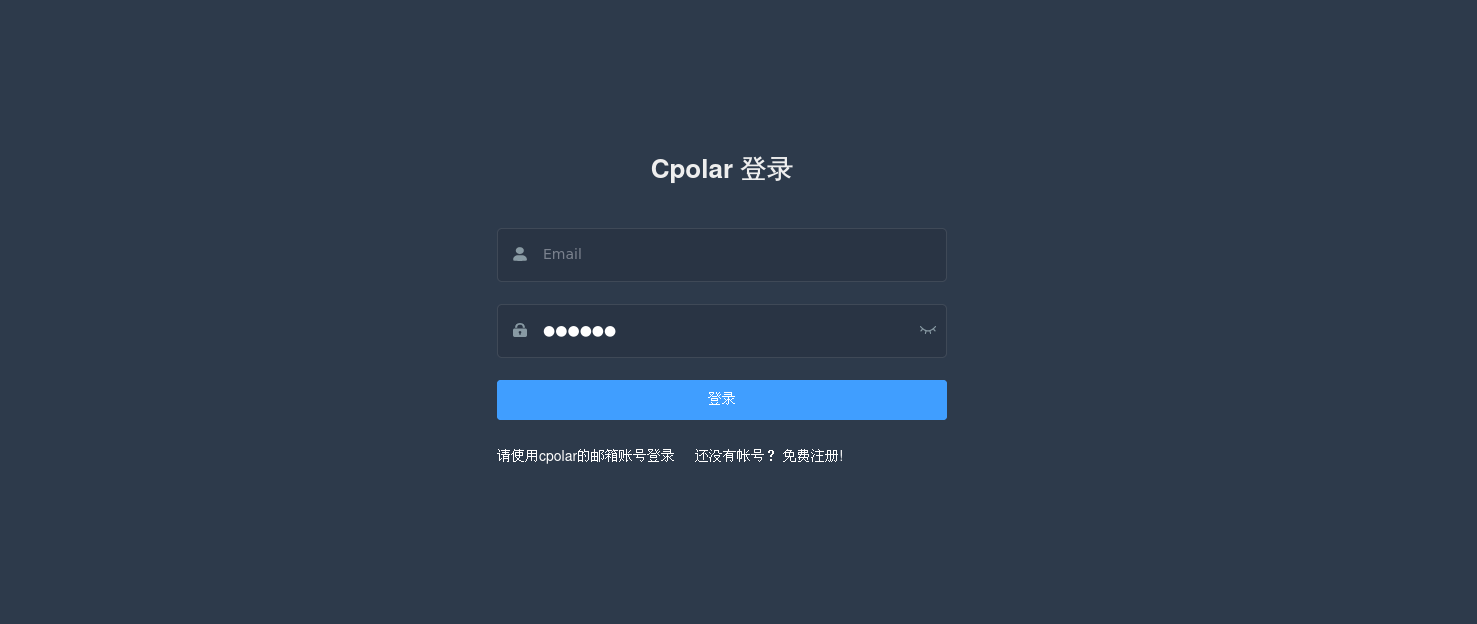
登录cpolar web UI管理界面后,点击左侧仪表盘的隧道管理——创建隧道:
- 隧道名称:可自定义,注意不要与已有的隧道名称重复,本例使用了:exdraw
- 协议:http
- 本地地址:5000
- 域名类型:随机域名
- 地区:选择China Top
点击创建
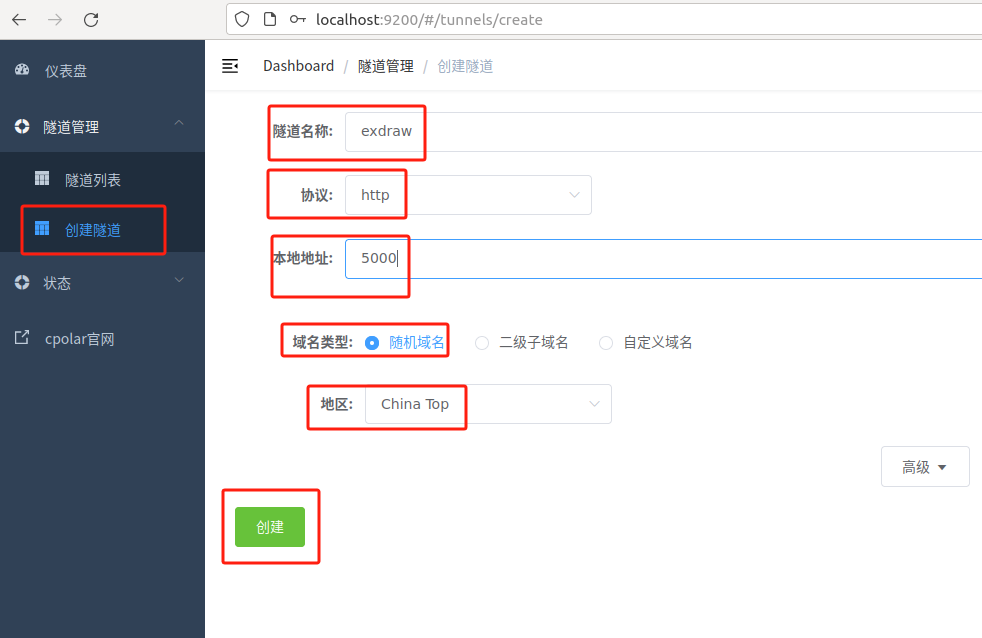
创建成功后,打开左侧在线隧道列表,可以看到刚刚通过创建隧道生成了两个公网地址,接下来就可以在其他电脑(异地)上,使用任意一个地址在浏览器中访问即可。
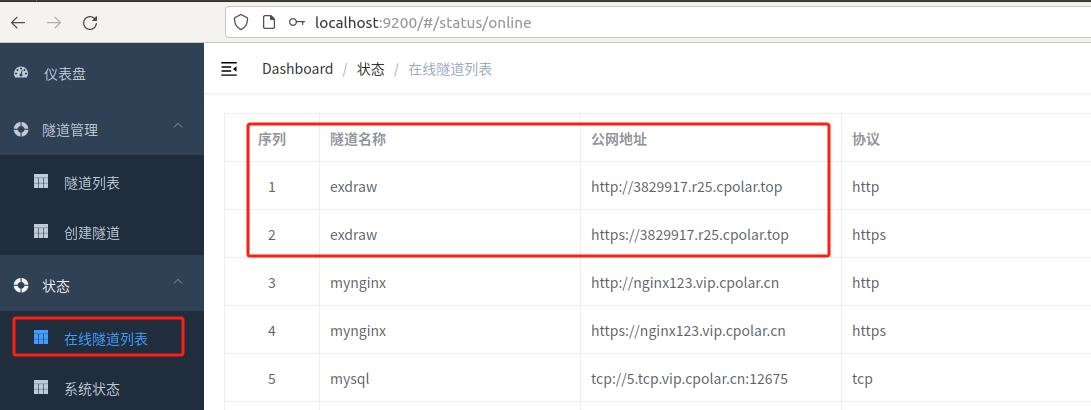
如下图所示,成功实现在公网环境访问本地部署的Excalidraw服务!
小结
为了方便演示,我们在上边的操作过程中使用了cpolar生成的HTTP公网地址隧道,其公网地址是随机生成的。
这种随机地址的优势在于建立速度快,可以立即使用。然而,它的缺点是网址是随机生成,这个地址在24小时内会发生随机变化,更适合于临时使用。
如果有长期远程访问本地Excalidraw服务的需求,但又不想每天重新配置公网地址,还想地址好看又好记,那我推荐大家选择使用固定的二级子域名方式来远程访问。
5.3 使用固定公网地址远程访问
登录cpolar官网,点击左侧的预留,选择保留二级子域名,地区选择China VIP,设置一个二级子域名名称,点击保留,保留成功后复制保留的二级子域名名称,这里我填写的是exdraw,大家也可以自定义喜欢的名称。

保留成功后复制保留成功的二级子域名的名称:exdraw,返回登录Cpolar web UI管理界面,点击左侧仪表盘的隧道管理——隧道列表,找到所要配置的隧道exdraw,点击右侧的编辑:
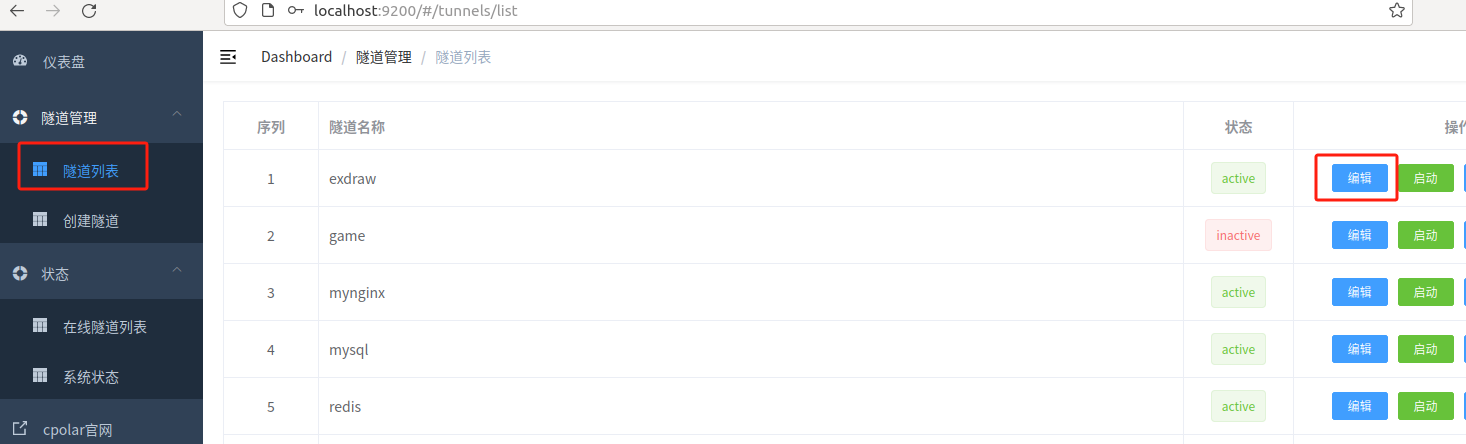
修改隧道信息,将保留成功的二级子域名配置到隧道中
- 域名类型:选择二级子域名
- Sub Domain:填写保留成功的二级子域名:exdraw
- 地区:选择China VIP
点击更新(注意,点击一次更新即可,不需要重复提交)
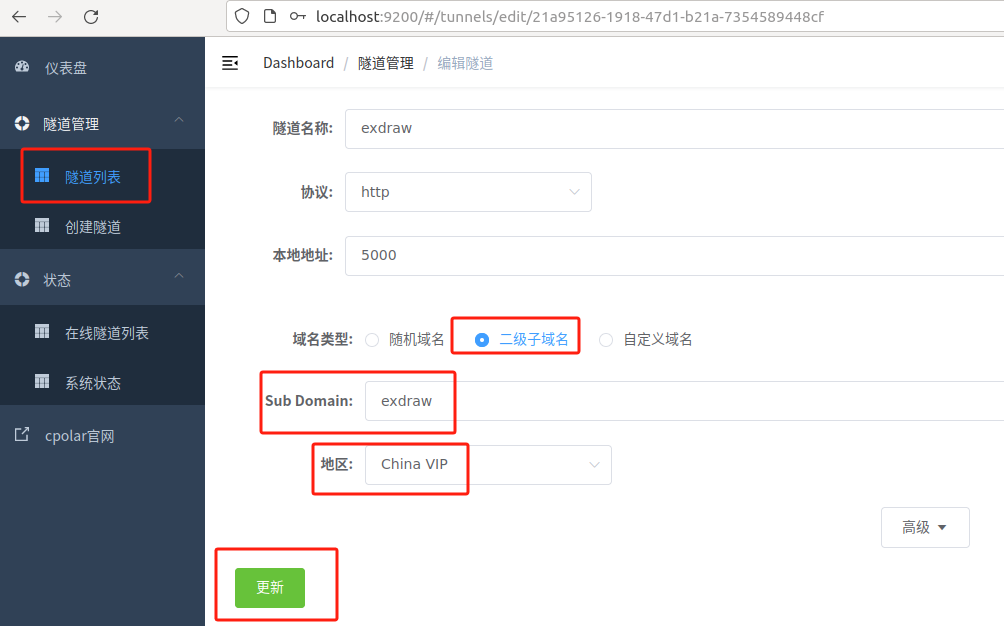
更新完成后,打开在线隧道列表,此时可以看到公网地址已经发生变化,地址名称也变成了固定的二级子域名名称的域名:
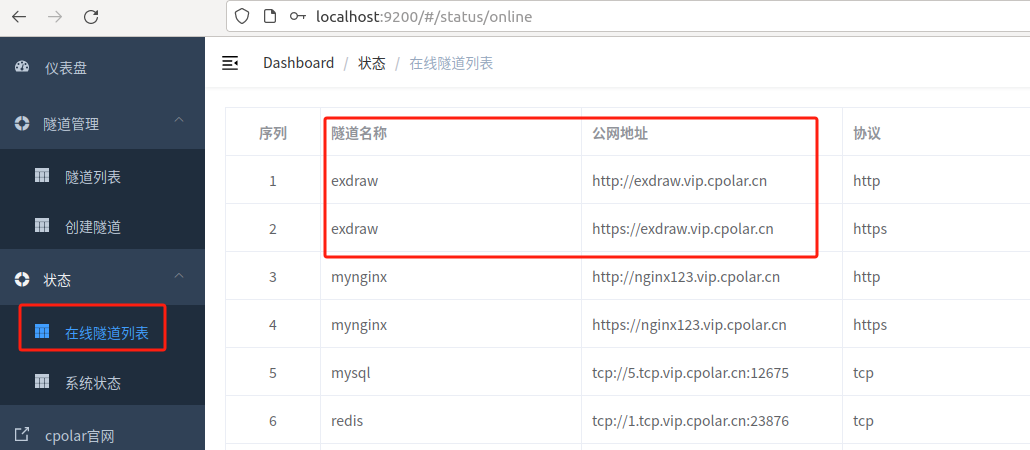
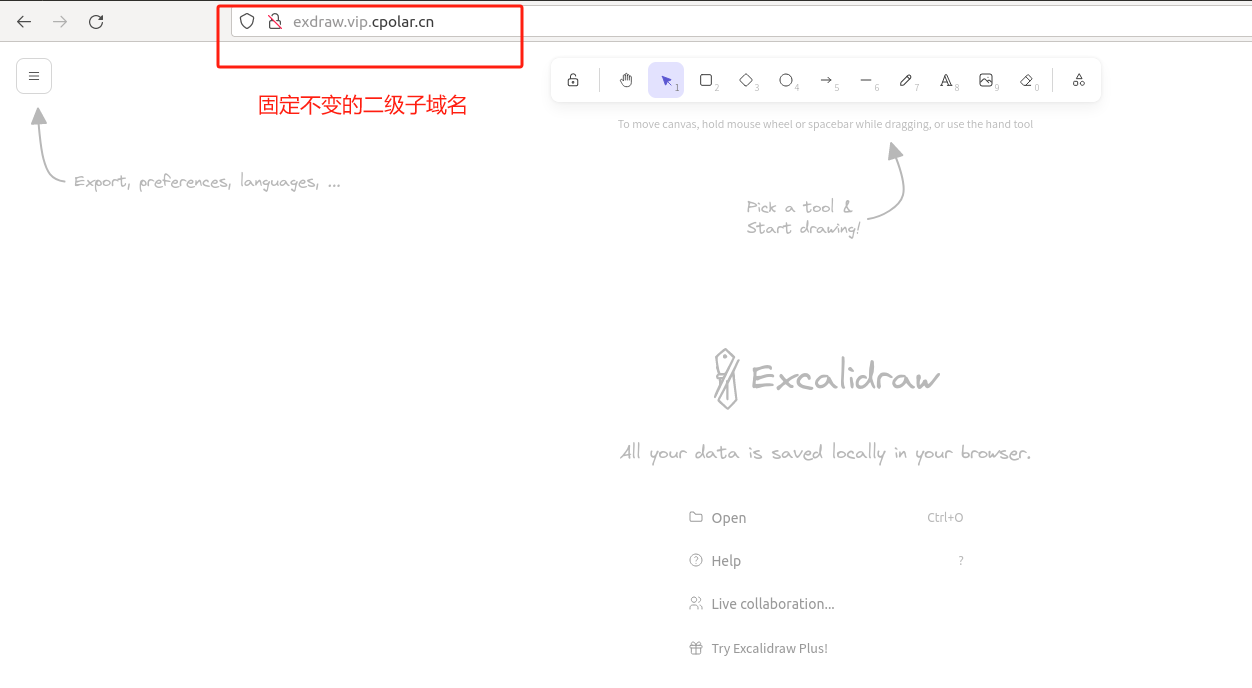
最后,我们使用任意一个固定公网地址在浏览器访问,可以看到访问成功,这样一个固定且永久不变的公网地址就设置好了,随时随地都可以远程访问本地部署的Excalidraw服务了!
以上就是如何在Ubuntu系统使用Docker部署Excalidraw容器,并结合cpolar内网穿透工具实现公网远程访问内网本地服务的全部流程,感谢您的观看。