还有什么类型的网站代客做网站
在上一章节中,我们介绍了Unity的旧版动画系统,本章节来介绍新版的Mecanim动画系统。新版的Mecanim动画系统实际是对旧版动画系统的升级。新版的Mecanim动画系统仍然是建立在动画片段的基础上的,只不过它给我们提供了一个可视化的窗口来编辑动画片段之间的切换逻辑。接下来,我们重新创建一个新的场景“SampleScene2.unity”。为了能够做区分,我们重新复制一份新的Elf的FBX文件到当前工程来。


接下来,我们选中“Elf2”里面的FBX文件,查看Inspector检视视图,
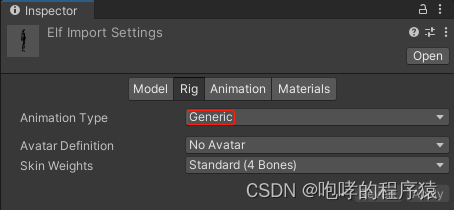
这里我们选择默认的“Generic”即可使用新版的Mecanim动画系统。然后我们再去“Animation”中重新分割四个动画片段,这个过程不再详细介绍了。
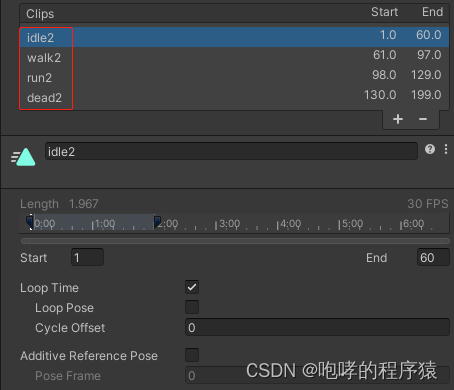
分割完毕,为了不混淆,我们给动画片段起了新的名字。接下来,我们将Elf2下的FBX文件拖拽到新场景中来。
我们上一个章节中介绍了,旧版动画系统使用的是“Animation”组件,而新版的动画系统使用的是“Animator”组件。因此,我们给“Elf”游戏对象添加这个组件,如下
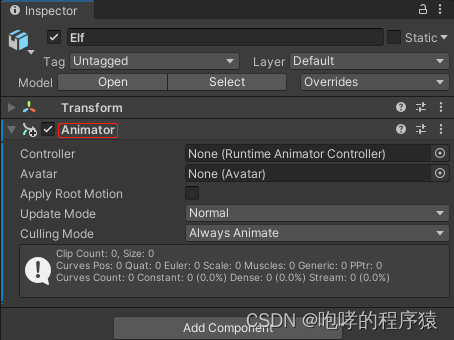
关于这个Animator组件,我们简单介绍一下。
首先介绍一下“Apply Root Motion”勾选项,如果勾选的话,行走动画的播放会同步调整Transform组件。如果不勾选的话,播放行走动画的时候,需要我们使用代码来控制Transform组件。动画片段中本身就是移动,旋转和缩放矩阵,因此使用动画片段播放的同时,是可以根据片段中的矩阵来同步Transform组件中的移动,旋转和缩放的。
然后再说一下Update Mode这个选项。Normal表示动画使用update方法进行更新。这个应该是默认吧。Animate Physics表示使用FixUpdate方法进行更新,一般用于和物体有交互的情况下。UnScaleTime表示无视timeScale进行更新,一般用于UI动画。
最后再说一下Culling model,它用来控制角色在场景中动画显示方式。默认值Always Animate表示角色总是会执行动画,即使角色不在摄像机范围内也执行动画。BaseOnRender表示当角色不在摄像机范围内时,角色仅仅播放自身带有Root Motion,而身体中的其他动画就不播放。
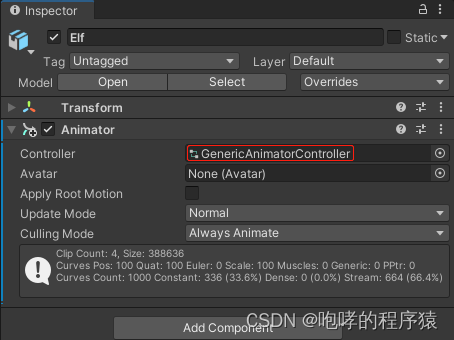
接下来,我们介绍“Animator”组件的第一个参数就是“Controller”,也就是动画控制器。它本质是一个文件,但是需要我们使用“Animator”窗口来编辑。请注意哦,一个是“Animator”组件,一个是“Animator”窗口,两者是不一样的。首先,我们在Asset资源面板中创建一个动画控制器,右击Asset资源面板空白处,选择“Create”->“Animator Controller”,我们将其重命名为“GenericAnimatorController”,它的文件类型后缀为“.controller”,我们也可以到工程目录的Asset文件夹下看到这个文件。

创建该文件完毕后,我们双击打开它,Unity会自动启动“Animator”窗口来打开它。
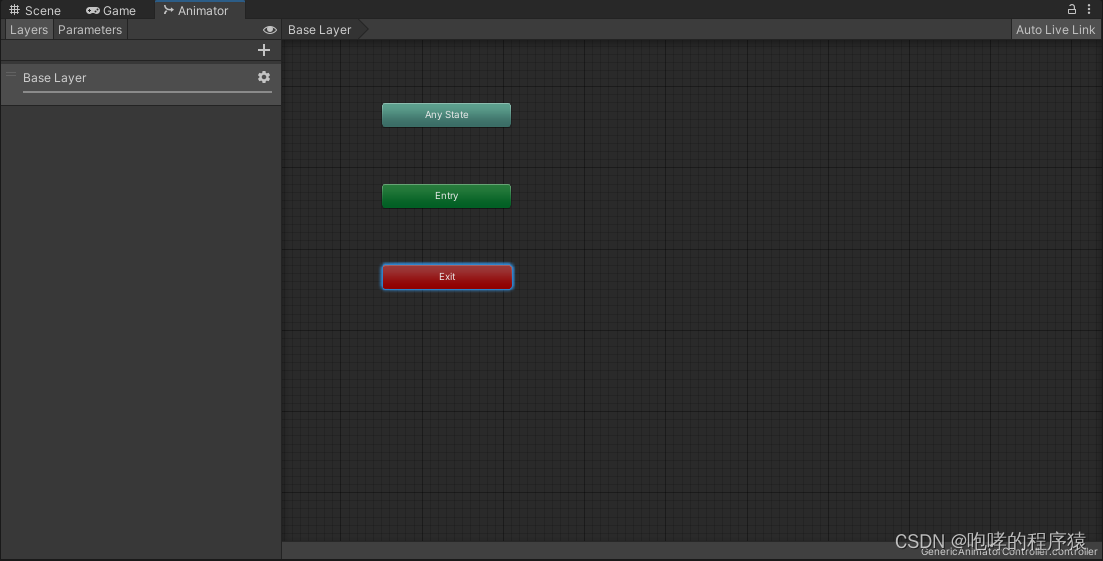
如上图所示,这个“Animator”窗口分为左右两部分,左边是动画层和动画参数编辑区域,右边是动画剪辑编辑区域。右边的区域可以使用鼠标滚轮进行缩放,也可以按下鼠标滚轮来拖动。我们首先介绍右边的区域,里面可以看到三个不同颜色的圆角矩形块,我们称之为“动画状态机”,其实可以简单理解为一个动画片段(两者概念相似)。“Any State”代表任意一个动画状态(动画片段),其作用是指向的动画片段在任意时刻都可以切换过去的状态,当然也包含自己切换自己。“Entry”表示进入“动画状态机”的默认动画状态(动画片段),该状态连接的动画片段就是进入状态机后要执行的第一个播放的动画片段。而“Exit”则表示离开“动画状态机”的动画状态(动画片段)。如果一个动画片段指向该出口,表示可以通过该状态退出当前动画状态机。既然是编辑动画片段,我们就先将动画片段拖拽进来吧。

我们选中“idle2”,“walk2”,“run2”和“dead2”四个动画片段,然后拖拽到“Animator”窗口右边的编辑区域。
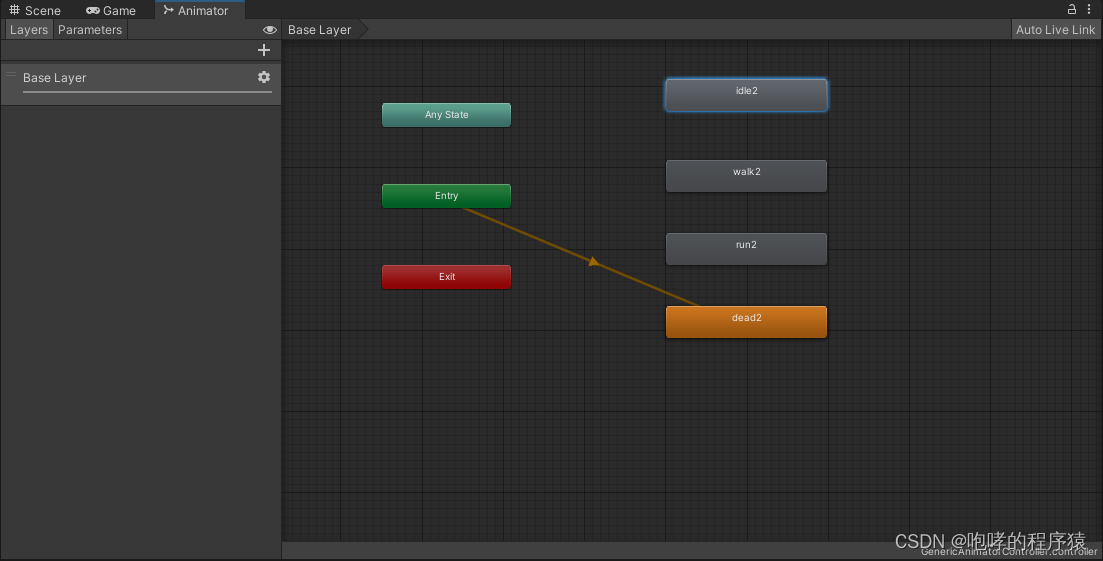
拖拽进来之后,我们发现Unity自动会将“Entry”的状态机连接到其中某一个动画片段,例如“dead2”这个动画片段。它代表的意思就是默认动画(橙色表示默认动画),回想一下我们使用“Animation”组件的时候,同样也设置过默认动画,道理是一样的。很显然,死亡动画是不对的,应该是待机动画“idle2”,如何修改呢?非常简单,我们只需要在“idle2”上右击,然后选择里面的“Set as Layer Default State”即可,如下所示:
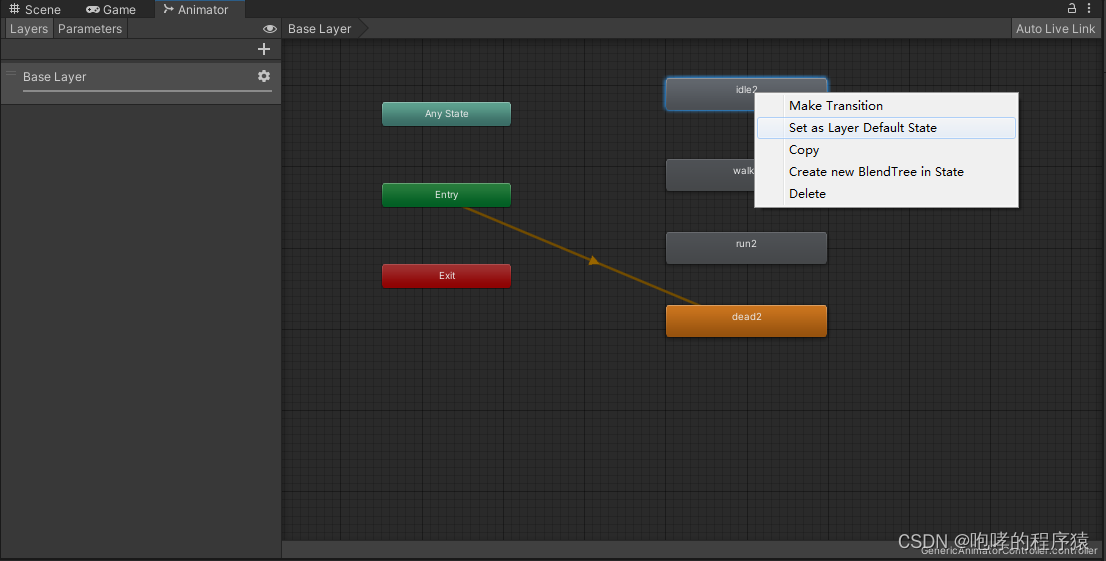
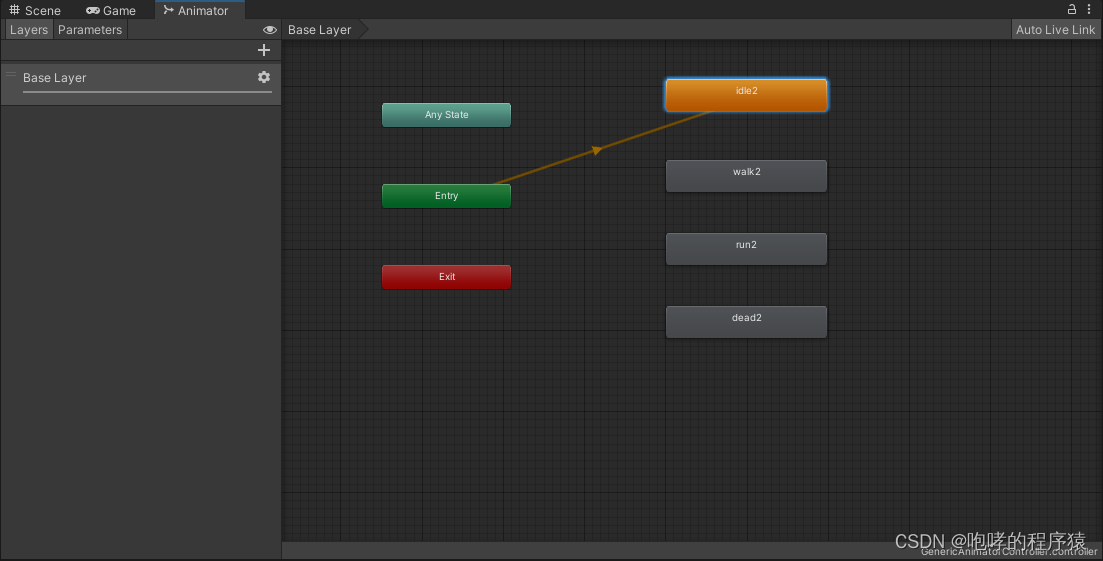
因为默认动画只有一个,因此,当我们设置idle2为默认动画的时候,之前的dead2就不是默认动画了,它从橙色变回了灰色。既然有了默认动画,那我们就看看如何播放它吧。回到我们的Scene视图,将我们的动画控制器“GenericAnimatorController.controller”文件拖拽到Elf游戏对象的Animator组件下的Controller项目下,
接下来,我们就可以运行工程,查看效果了。
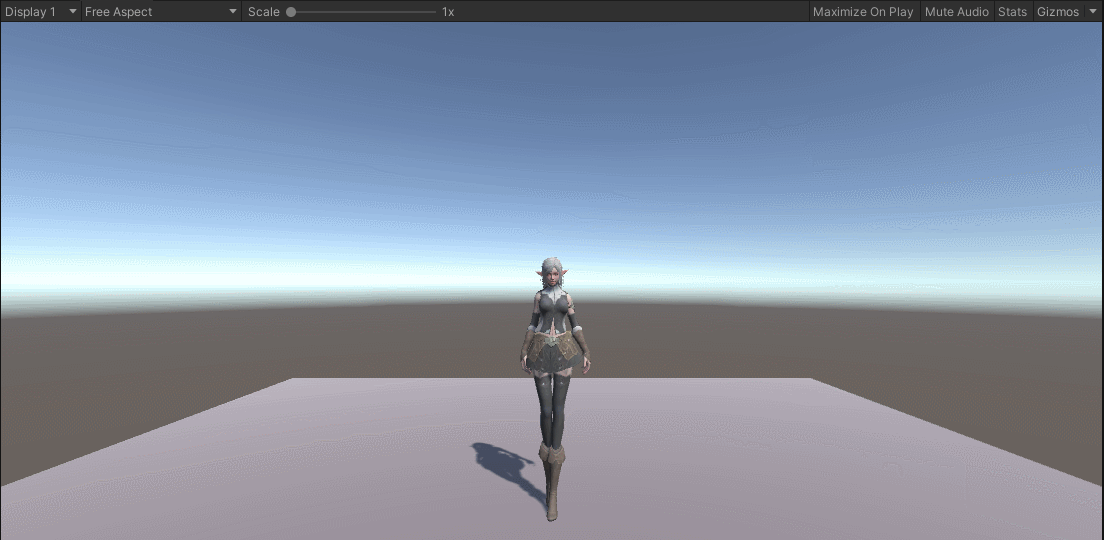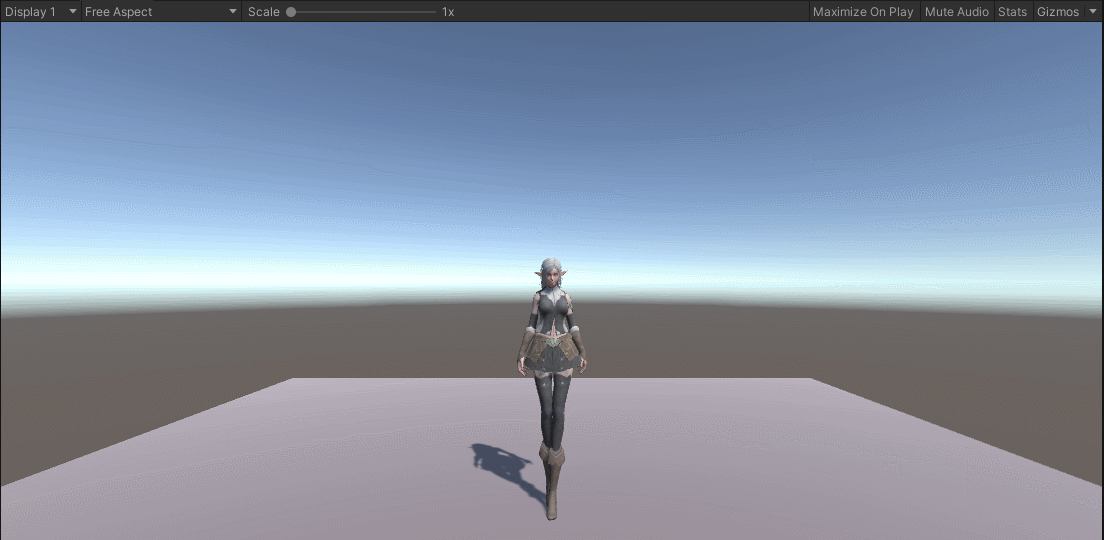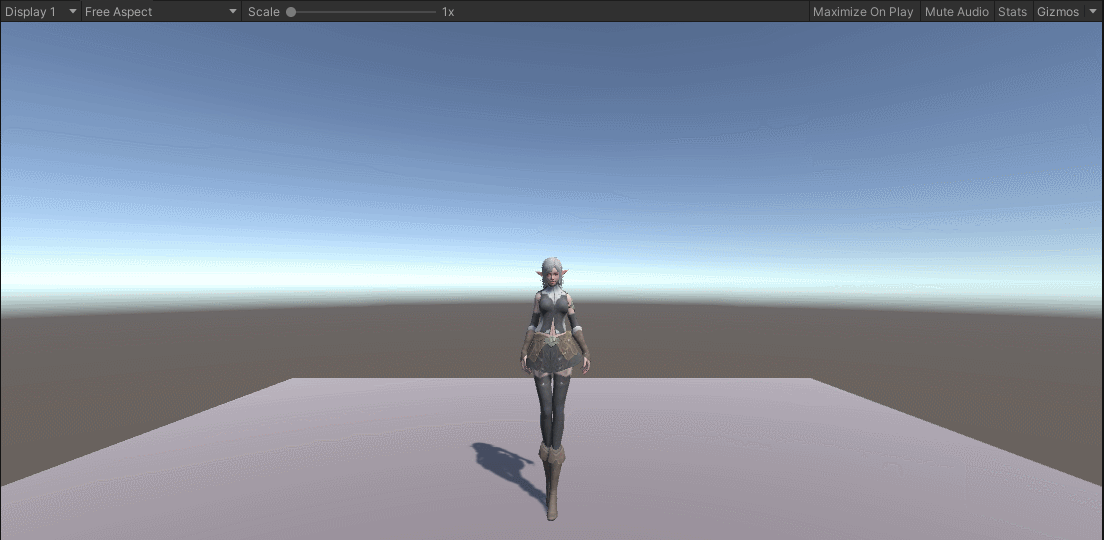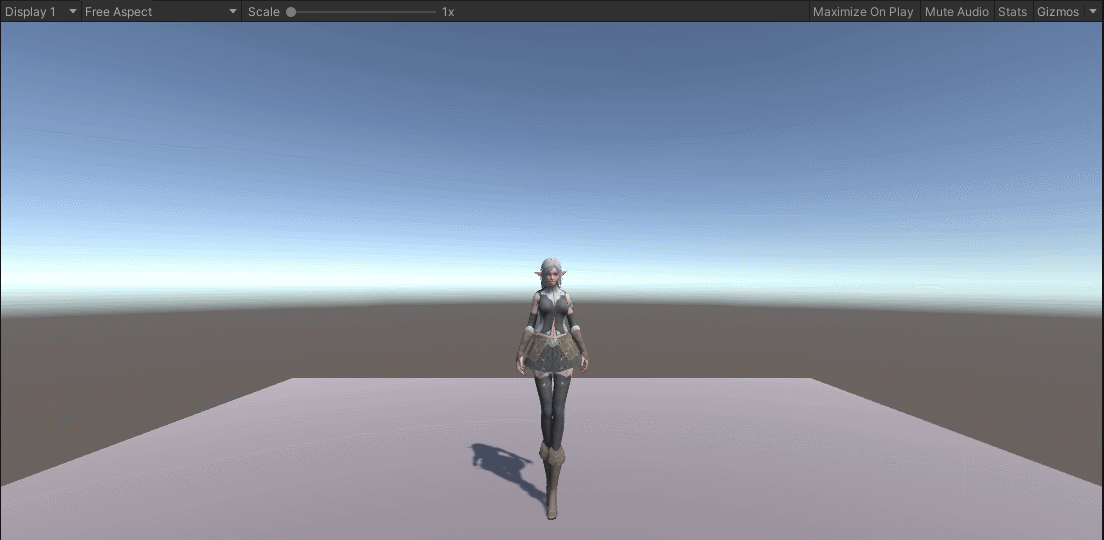
我们的默认动画“idle2”已经可以播放了。那么问题来了,如何播放其他动画呢?我们还需要回到“Animator”窗口中继续编辑我们的“GenericAnimatorController.controller”文件。在大部分的游戏中,基本上游戏角色默认都是待机状态,然后从待机状态切换到走路或者跑步状态。因此,我们可以从待机“idle2”向走路“walk2”和跑步“run2”分别做两个“Transiton”,翻译过来就是“过渡”的意思。其实,我们仔细想想,动画播放的本质就是从一个动画片段“过渡”到另一个动画片段。动画逻辑的复杂度也就在于此了,大量的“过渡”就会造成我们的动画播放逻辑非常的混乱。如何创建“idle2”到“walk2”的“Transiton”呢?我们在“idle2”上面右击,选择其中的“Make Transiton”,如下所示:
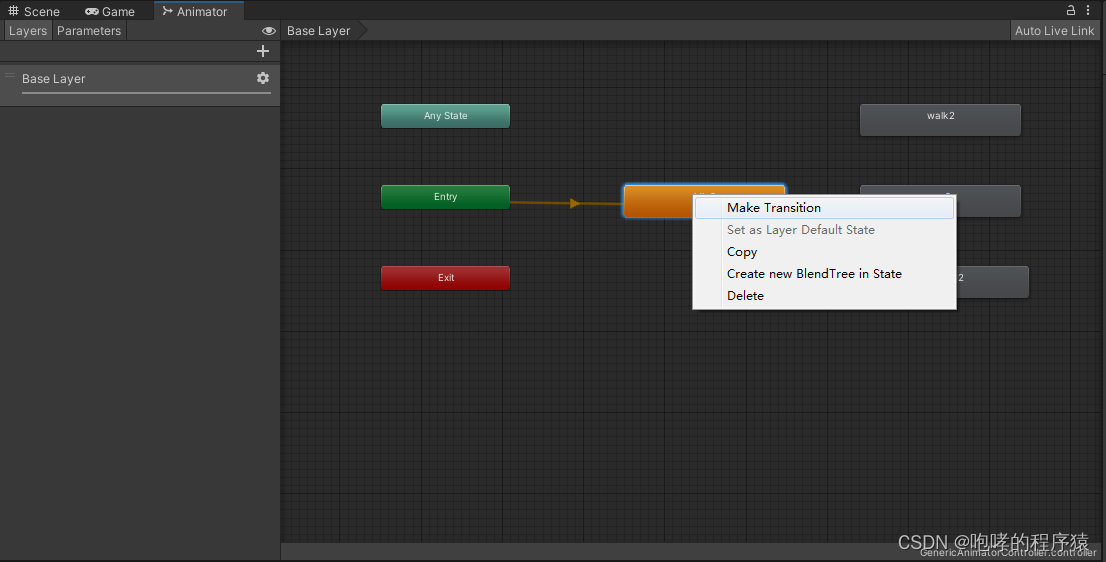
点击“Make Transiton”之后,我们移动鼠标,就会出现一条带箭头的线,
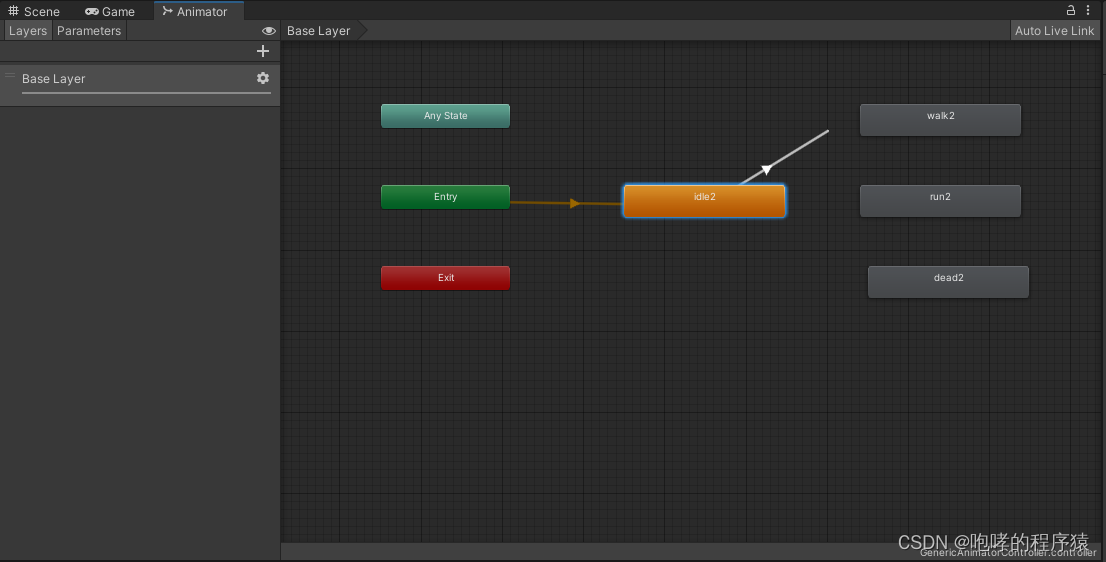
我们将线放置到“walk2”上面后鼠标点击完成,这样就完成了idle2到walk2的连接。我们继续右击idle2选择“Make Transiton”,将线放置到run2上面后鼠标点击完成。这样,我们就建立了两条“过渡”线了。
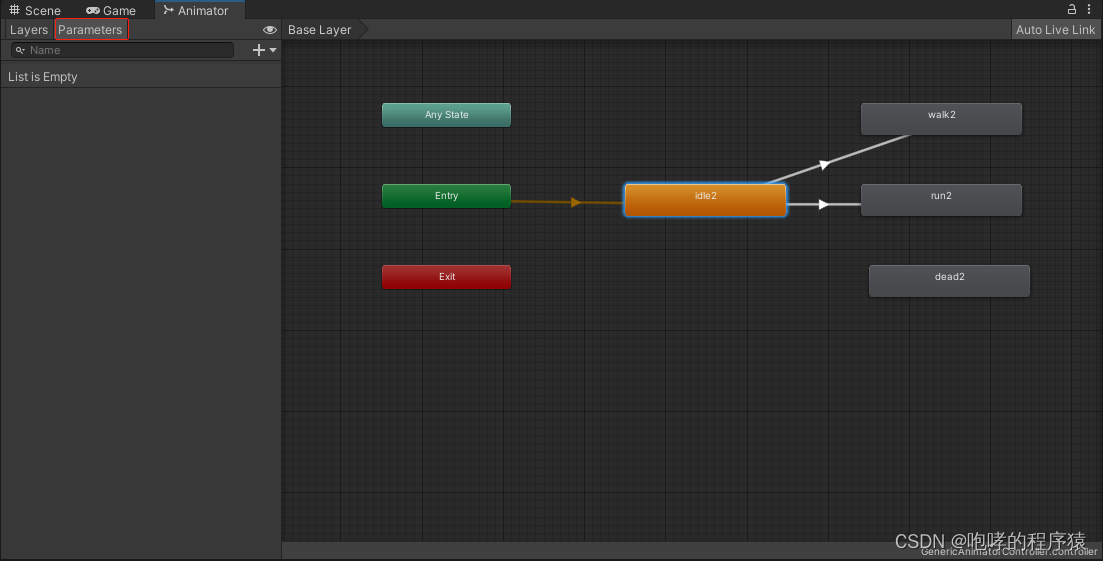
默认情况下,线是白色的,如果我们点击其中一条线的话,就会以蓝色显示。如果我们创建错的线,可以选择该线(蓝色显示)后按“delete”键删除即可。现在,我们已经创建了idle2到walk2和run2的过渡了,那么什么情况下回执行idle2到walk2的过渡呢?又会在什么情况下执行idle2到run2的过渡呢?这时候,我们需要继续设置“过渡条件”。这条线相当于一座桥,连同两个动画片段,而“过渡条件”就是“通行证”,有了对应的“通行证”,才能决定是idle2切换到walk2,还是idle2切换到run2。如何设置这个“过渡条件”呢?由于该部分内容太多了,我们下个章节继续介绍。
本课程涉及的内容已经共享到百度网盘:https://pan.baidu.com/s/1e1jClK3MnN66GlxBmqoJWA?pwd=b2id