网站服务器作用网站制作公司珠海
目标:
1.在多平台调试启动Flutter程序运行
一、安卓模拟器
1.1 检查当前Flutter适配的版本
flutter doctor提供了Flutter诊断。
$ flutter doctor --verbose
/Users/zhouronghua/IDES/flutter/bin/flutter doctor --verbose
[✓] Flutter (Channel master, 2.13.0-0.0.pre.275, on macOS 11.7.10 20G1427 darwin-x64, locale zh-Hans-CN)• Flutter version 2.13.0-0.0.pre.275 at /Users/zhouronghua/IDES/flutter• Upstream repository git@github.com:flutter/flutter.git• Framework revision 8acbf54930 (2 years, 3 months ago), 2022-03-26 22:12:48 -0700• Engine revision eb84fd2666• Dart version 2.17.0 (build 2.17.0-239.0.dev)• DevTools version 2.11.4• Pub download mirror https://pub.flutter-io.cn• Flutter download mirror https://storage.flutter-io.cn[!] Android toolchain - develop for Android devices (Android SDK version 32.1.0-rc1)• Android SDK at /Users/zhouronghua/IDES/Android/sdk✗ cmdline-tools component is missingRun `path/to/sdkmanager --install "cmdline-tools;latest"`See https://developer.android.com/studio/command-line for more details.✗ Android license status unknown.Run `flutter doctor --android-licenses` to accept the SDK licenses.See https://flutter.dev/docs/get-started/install/macos#android-setup for more details.[!] Xcode - develop for iOS and macOS (Xcode 12.3)• Xcode at /Applications/Xcode.app/Contents/Developer✗ Flutter requires Xcode 13 or higher.Download the latest version or update via the Mac App Store.• CocoaPods version 1.11.3[✓] Chrome - develop for the web• Chrome at /Applications/Google Chrome.app/Contents/MacOS/Google Chrome[!] Android Studio (version 2022.1)• Android Studio at /Applications/Android Studio.app/Contents• Flutter plugin can be installed from:🔨 https://plugins.jetbrains.com/plugin/9212-flutter• Dart plugin can be installed from:🔨 https://plugins.jetbrains.com/plugin/6351-dart✗ Unable to find bundled Java version.• Try updating or re-installing Android Studio.[✓] IntelliJ IDEA Ultimate Edition (version 2022.1)• IntelliJ at /Applications/IntelliJ IDEA.app• Flutter plugin can be installed from:🔨 https://plugins.jetbrains.com/plugin/9212-flutter• Dart plugin can be installed from:🔨 https://plugins.jetbrains.com/plugin/6351-dart[✓] Connected device (2 available)• sdk gphone64 x86 64 (mobile) • emulator-5554 • android-x64 • Android 12 (API 32) (emulator)• Chrome (web) • chrome • web-javascript • Google Chrome 125.0.6422.142[✓] HTTP Host Availability• All required HTTP hosts are available1.1.1 Fix环境问题
安卓 toolchain 问题
问题一:cmdline-tools component is missing
根据提示安装cmdline
$ sdkmanager --install "cmdline-tools;latest"
问题二:Android license status unknown.
Exception in thread "main" java.lang.UnsupportedClassVersionError: com/android/sdklib/tool/sdkmanager/SdkManagerCli has been compiled by a more recent version of the Java Runtime (class file version 61.0), this version of the Java Runtime only recognizes class file versions up to 52.0
查看java版本
$ java -version
java version "1.8.0_144"
Java(TM) SE Runtime Environment (build 1.8.0_144-b01)
Java HotSpot(TM) 64-Bit Server VM (build 25.144-b01, mixed mode)
因为flutter支持1.8,此告警可以忽略。
1.1.2 安装Android Studio新版本
如果解决适配问题仍然存在问题的话,尝试下载AS最新版本。
1.2 创建安卓模拟器
创建Android toolchain对应版本的模拟器。
flutter版本:2.13.0-0.0.pre.275 模拟器采用的是Pixel 6 安卓32.1.0-rc1
1.2.1 创建一个新的Flutter项目
1.2.2 编译生成apk
AS--》Build菜单--》Build APK,编译生成新的APK。
编译成功以后,在
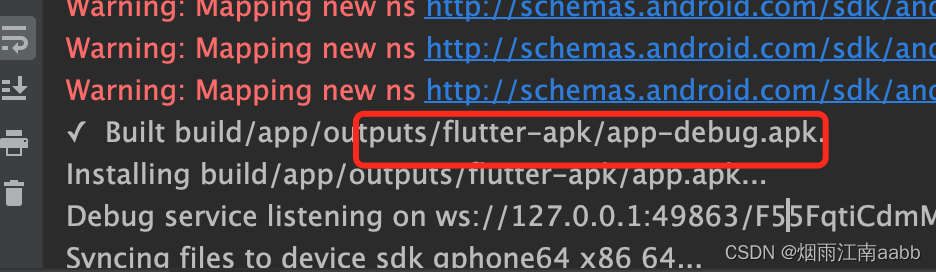
输出目录能看到flutter-apk下,生成的APK文件
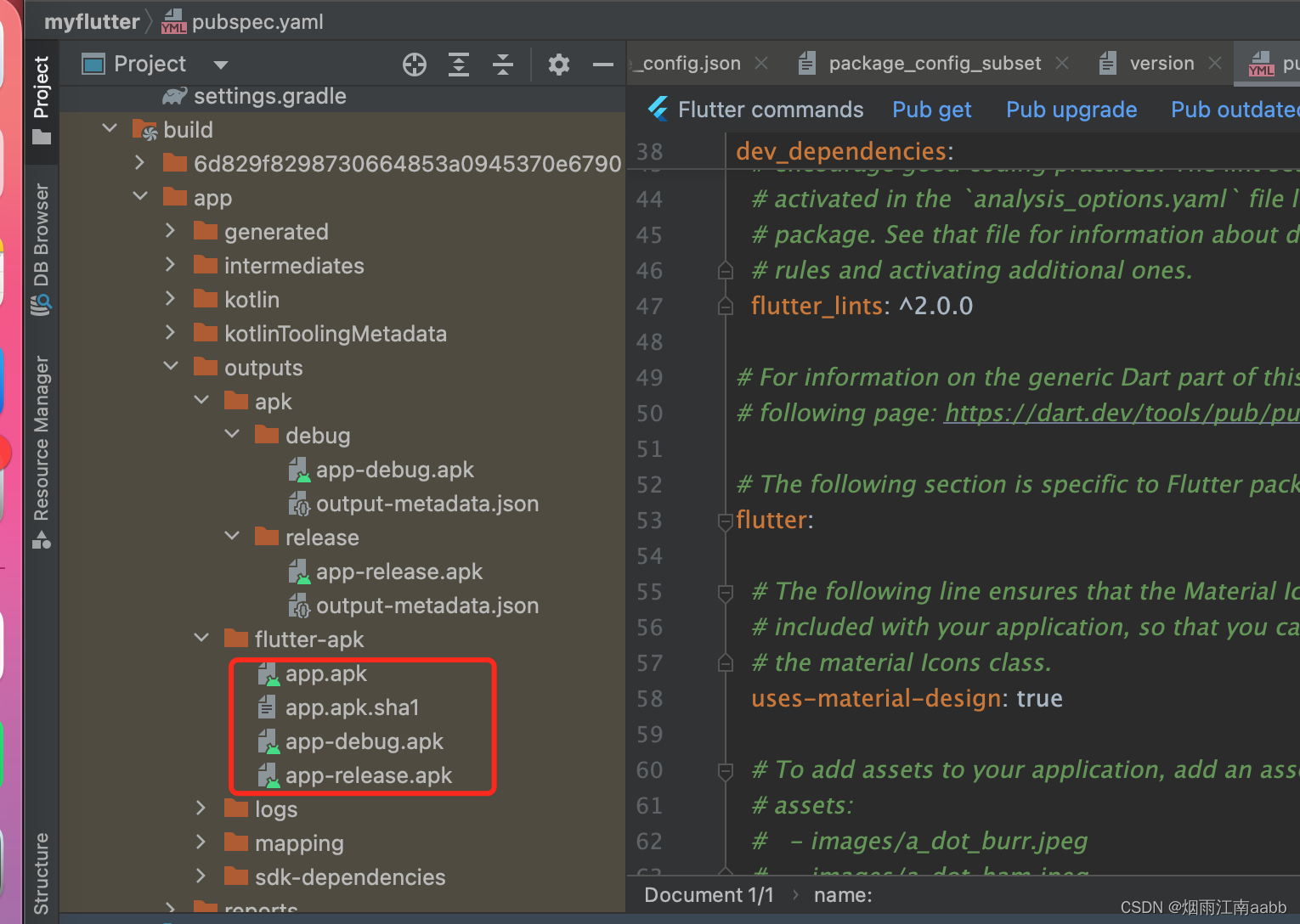
1.2.3 运行APK
手动安装APK运行,或者 设备选择模拟器,点击运行按钮,
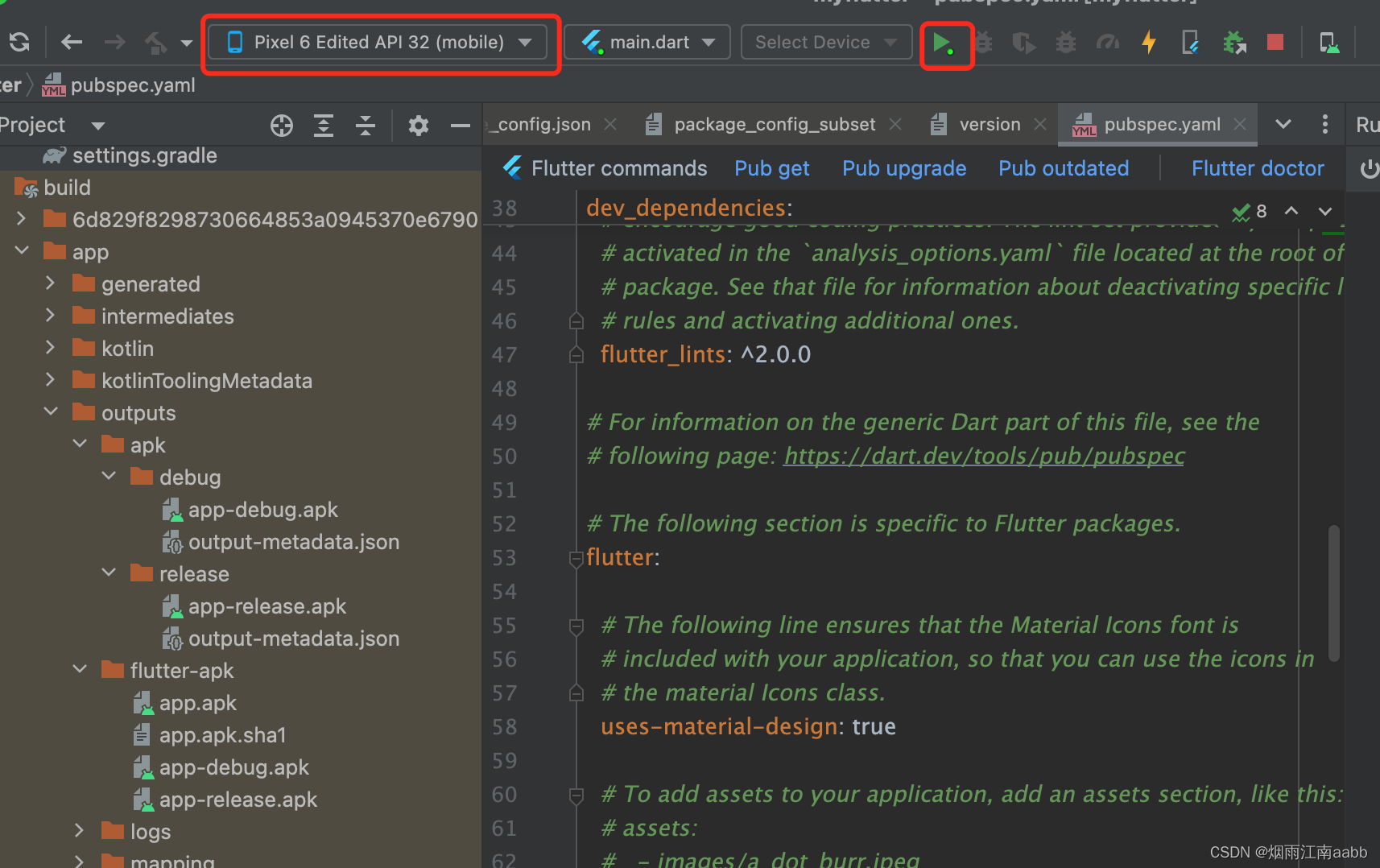
则将APK安装到模拟器并且运行。
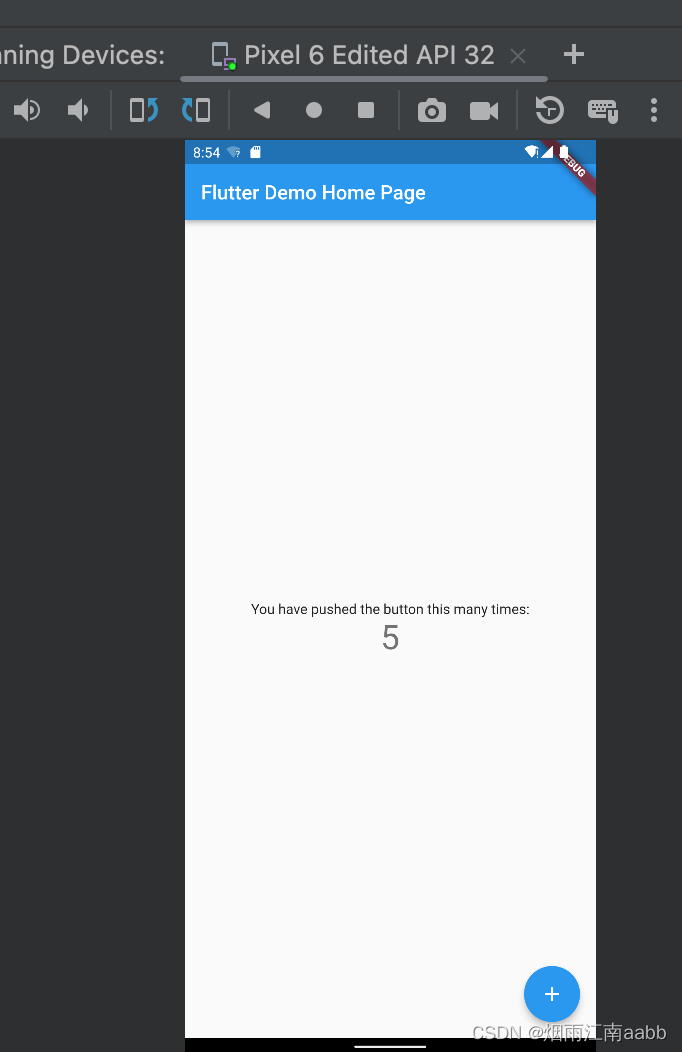
可以看到在模拟器中运行成功。 ^_^