网站的几种提交方式wordpress 插件表单 写入数据库
一、autograd—自动求导系统
torch.autograd.backward()
torch.autograd.backward()是PyTorch中用于计算梯度的函数。以下是对该函数的参数的解释:
功能:自动求取梯度
• tensors: 用于求导的张量,如 loss
• retain_graph : 保存计算图
• create_graph : 创建导数计算图,用于高阶求导
• grad_tensors:多梯度权重
tensors:需要计算梯度的张量或张量的列表。这些张量的requires_grad属性必须为True。grad_tensors:可选参数,用于指定关于tensor的外部梯度。默认为None,表示使用默认的梯度为1。retain_graph:可选参数,用于指定是否保留计算图以供后续计算。默认为None,表示根据需要自动释放计算图。create_graph:可选参数,用于指定是否创建计算图以支持高阶梯度计算。默认为False,表示不创建计算图。
该函数的作用是计算tensors中张量的梯度,使用链式法则将梯度传播到叶子结点。它会自动构建计算图,并使用反向传播算法计算梯度。
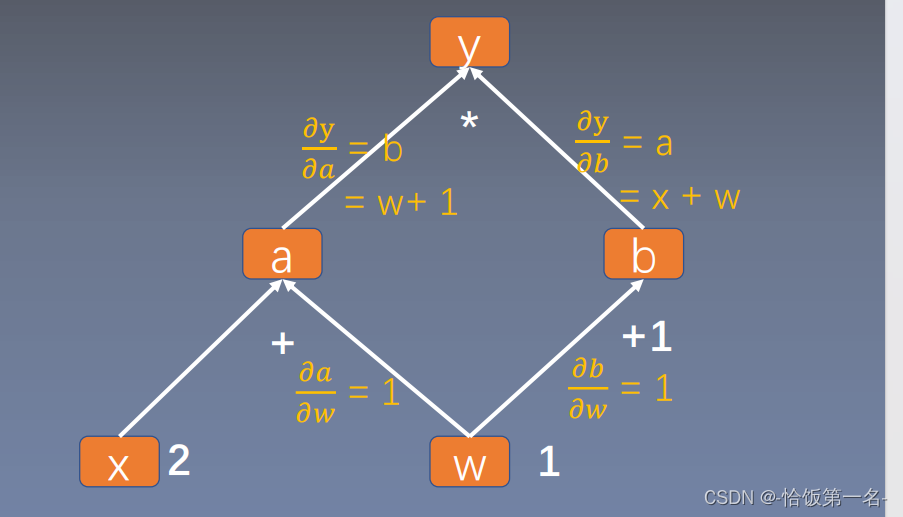
当y = (x + w) * (w + 1),a = x + w,b = w + 1,y = a * b时对于w的梯度的推导如下:
𝜕y/𝜕w = (𝜕y/𝜕a) * (𝜕a/𝜕w) + (𝜕y/𝜕b) * (𝜕b/𝜕w)
= b * 1 + a * 1
= b + a
= (w + 1) + (x + w)
= 2w + x + 1
= 2 * 1 + 2 + 1
= 5
因此,当y = (x + w) * (w + 1)时,对于w的梯度为5。

torch.autograd.grad()
torch.autograd.grad()是PyTorch中用于计算梯度的函数。以下是对该函数的参数的解释:
功能:求取梯度
• outputs: 用于求导的张量,如 loss
• inputs : 需要梯度的张量
• create_graph : 创建导数计算图,用于高阶求导
• retain_graph : 保存计算图
• grad_outputs:多梯度权重
outputs:需要计算梯度的标量或标量的列表。这些标量通常是模型的损失函数。inputs:关于哪些输入变量计算梯度。可以是单个张量或张量的列表。grad_outputs:可选参数,用于指定关于outputs的外部梯度。默认为None,表示使用默认的梯度为1。retain_graph:可选参数,用于指定是否保留计算图以供后续计算。默认为None,表示根据需要自动释放计算图。create_graph:可选参数,用于指定是否创建计算图以支持高阶梯度计算。默认为False,表示不创建计算图。
该函数的作用是计算outputs关于inputs的梯度。它会自动构建计算图,并使用反向传播算法计算梯度。
autograd小贴士:
- 梯度不自动清零
- 依赖于叶子结点的结点,requires_grad默认为True
- 叶子结点不可执行in-place
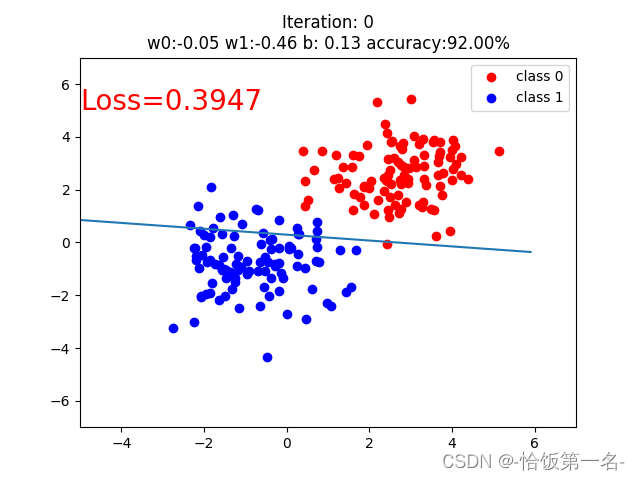
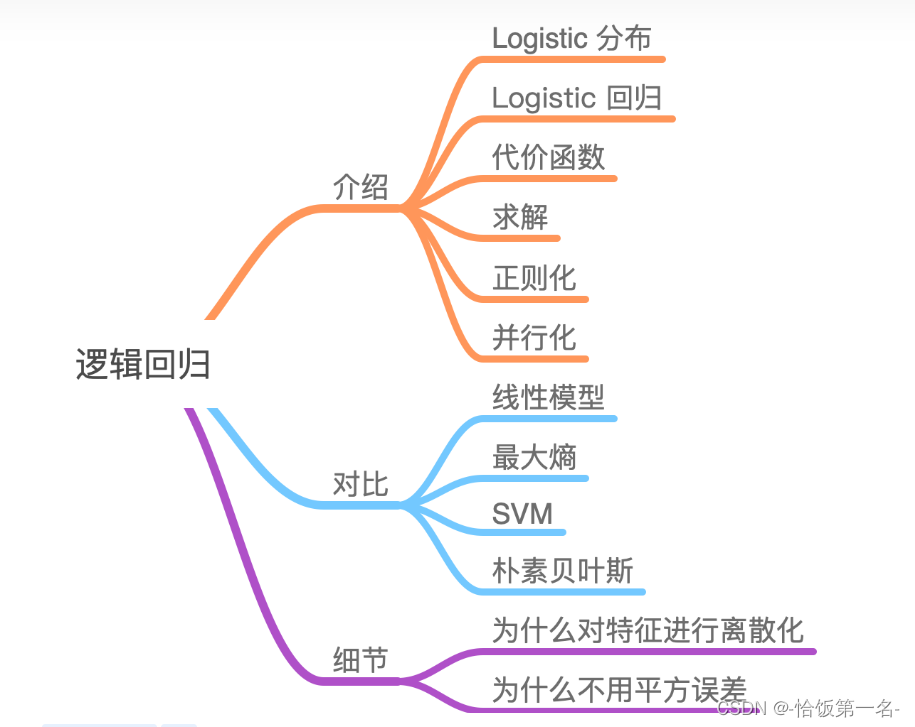
二、逻辑回归


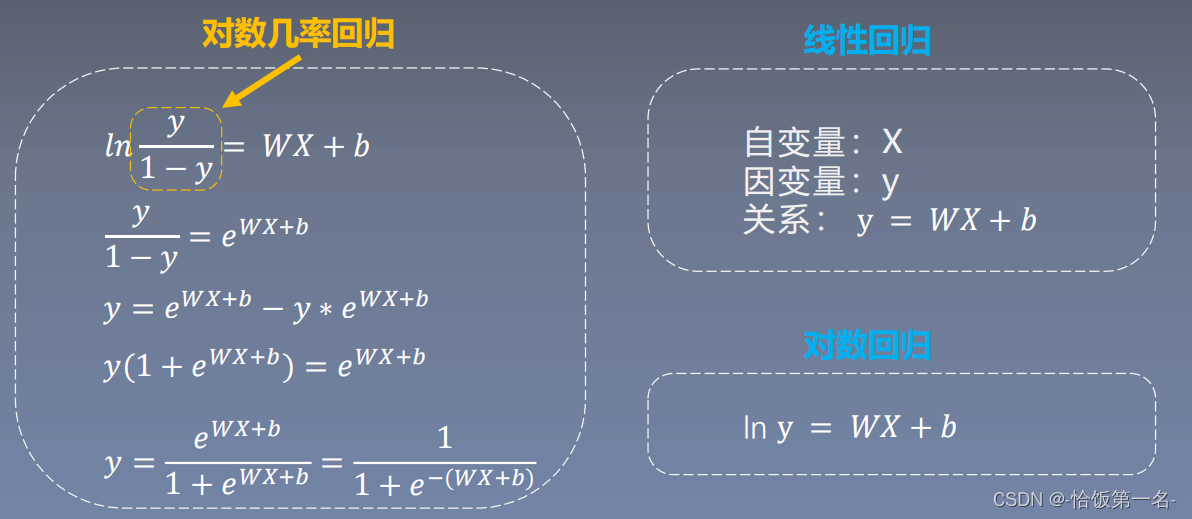
线性回归是分析自变量x与因变量y(标量)之间关系的方法
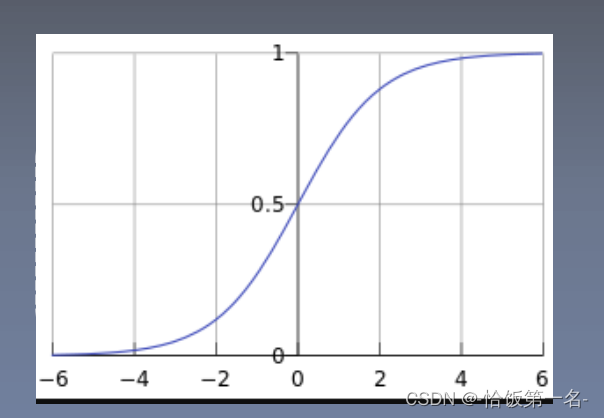
逻辑回归是分析自变量x与因变量y(概率)之间关系的方法