域名和空间都有了怎么做网站河南省智慧团建
一、功能介绍
很多系统运行都依托数据库,不少IDE让开发实现快速开发的同时,也提供了方便快捷的打包工具。例如: Visual Studio集成的 Install Shield、Wix Toolkit; Android Studio 集成的 Gradle 等等,这些集成的打包工具,能够使用我们方便的做出msi、exe、apk等各种格式的安装包,但是数据库初始化这块却不尽人意,甚至完全没有此项功能。
在这个背景下,我们做了一款SQL语句执行工具,它支持创建数据库、多库执行,创建表、视图、存储过程 等DDL操作,也支持增、删、改、查 等DML操作;开发人员只需要将相应脚本按指定规则命名,并放进文件夹内,通过 里面的工具 自动生成“运行说明”文件,说明文件会自动指定好 脚本运行数据库(Data库、Meta库、Sys库)和 执行顺序(比如 创建视图前,先要创建表),保证SQL脚本顺序执行。
二、运行效果
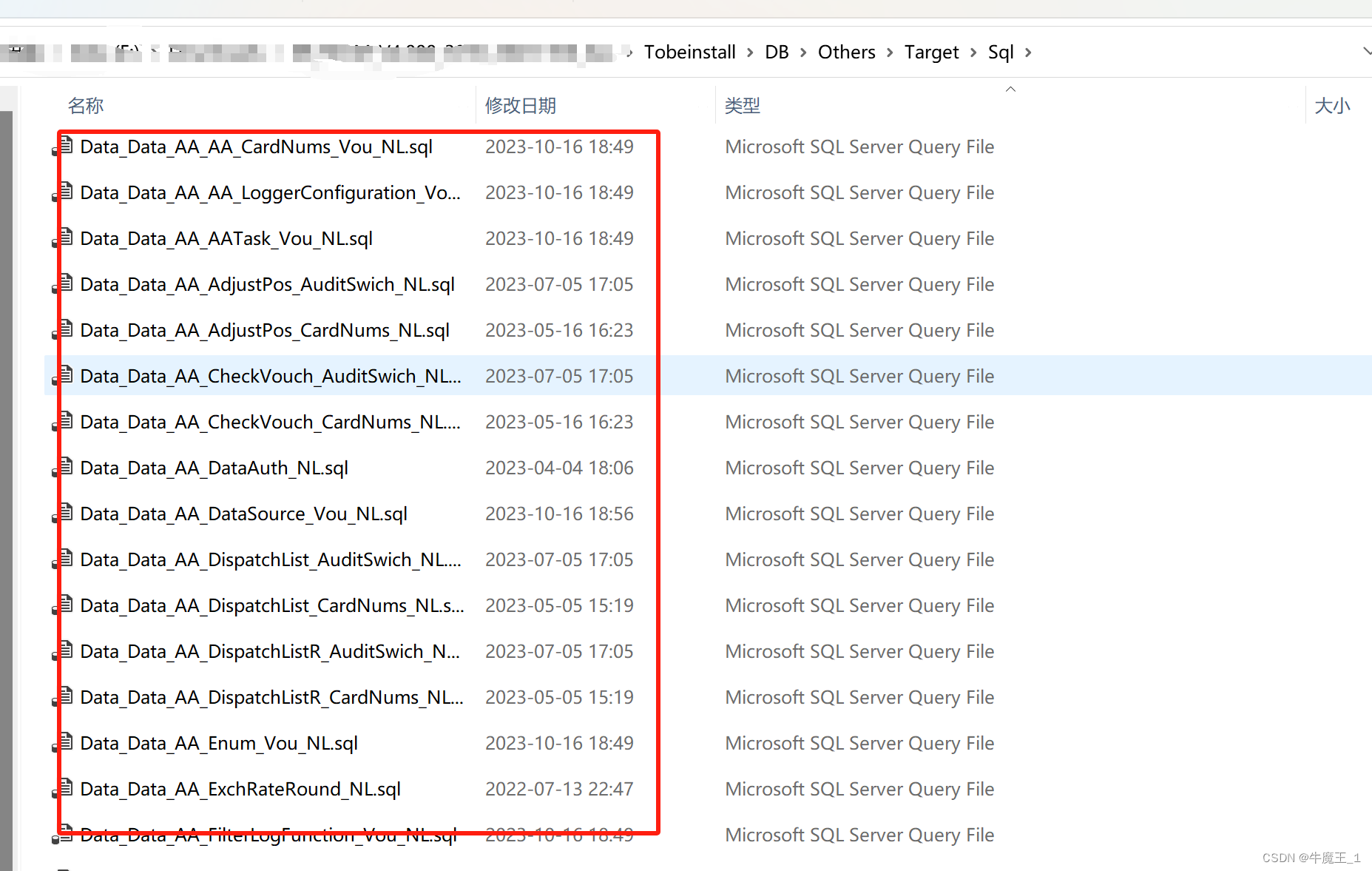
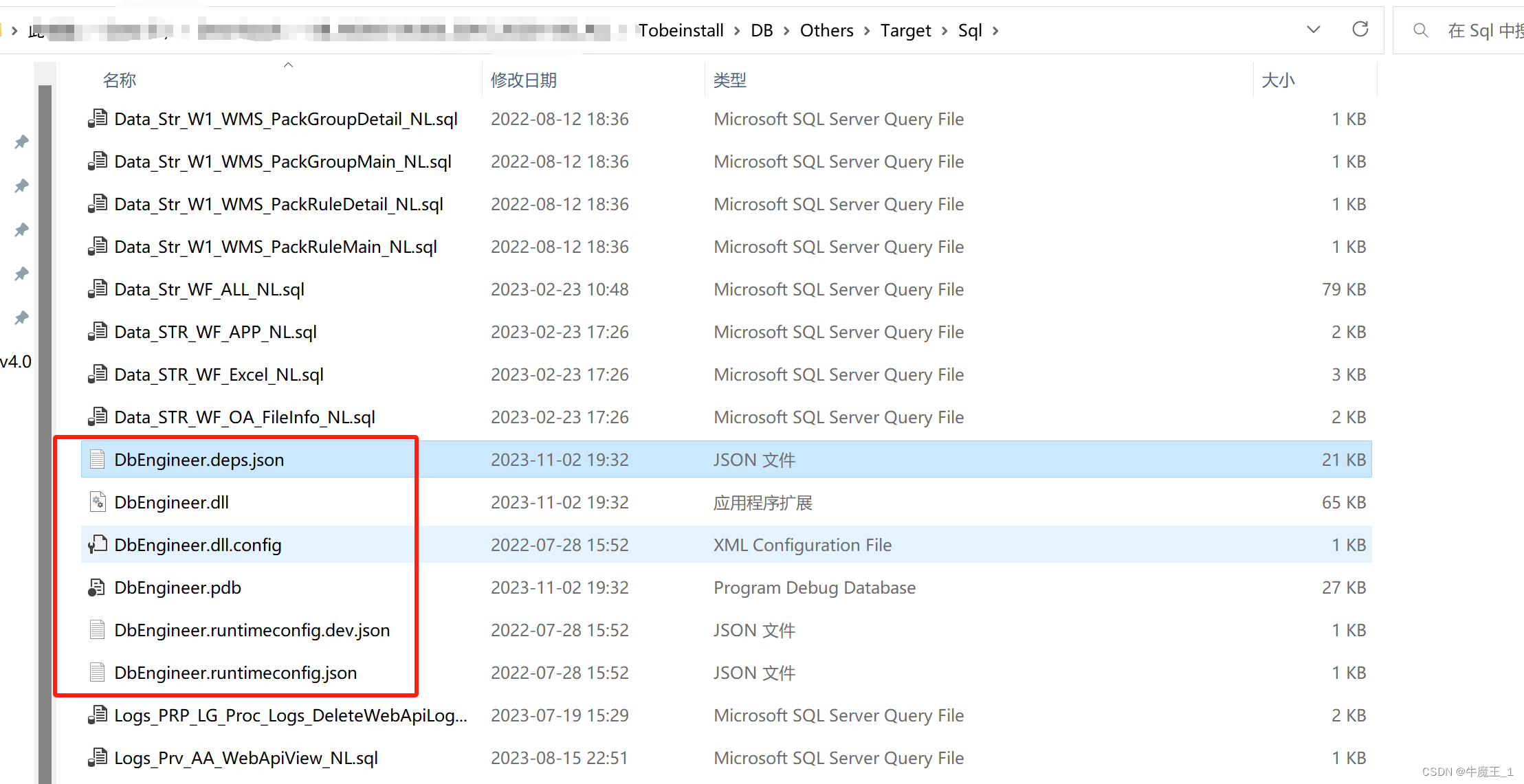
1. 放置脚本
开发人员写SQL语句,并按命名规则放入文件夹, Sql脚本 和 脚本执行器 DbEngineer.exe 放在同一个文件夹下即可。
当前示例 Tobeinstall代表安装包根目录,Sql脚本 和 脚本执行器 DbEngineer.exe 都放在Tobeinstall/DB/Others/Target/Sql 文件夹下。
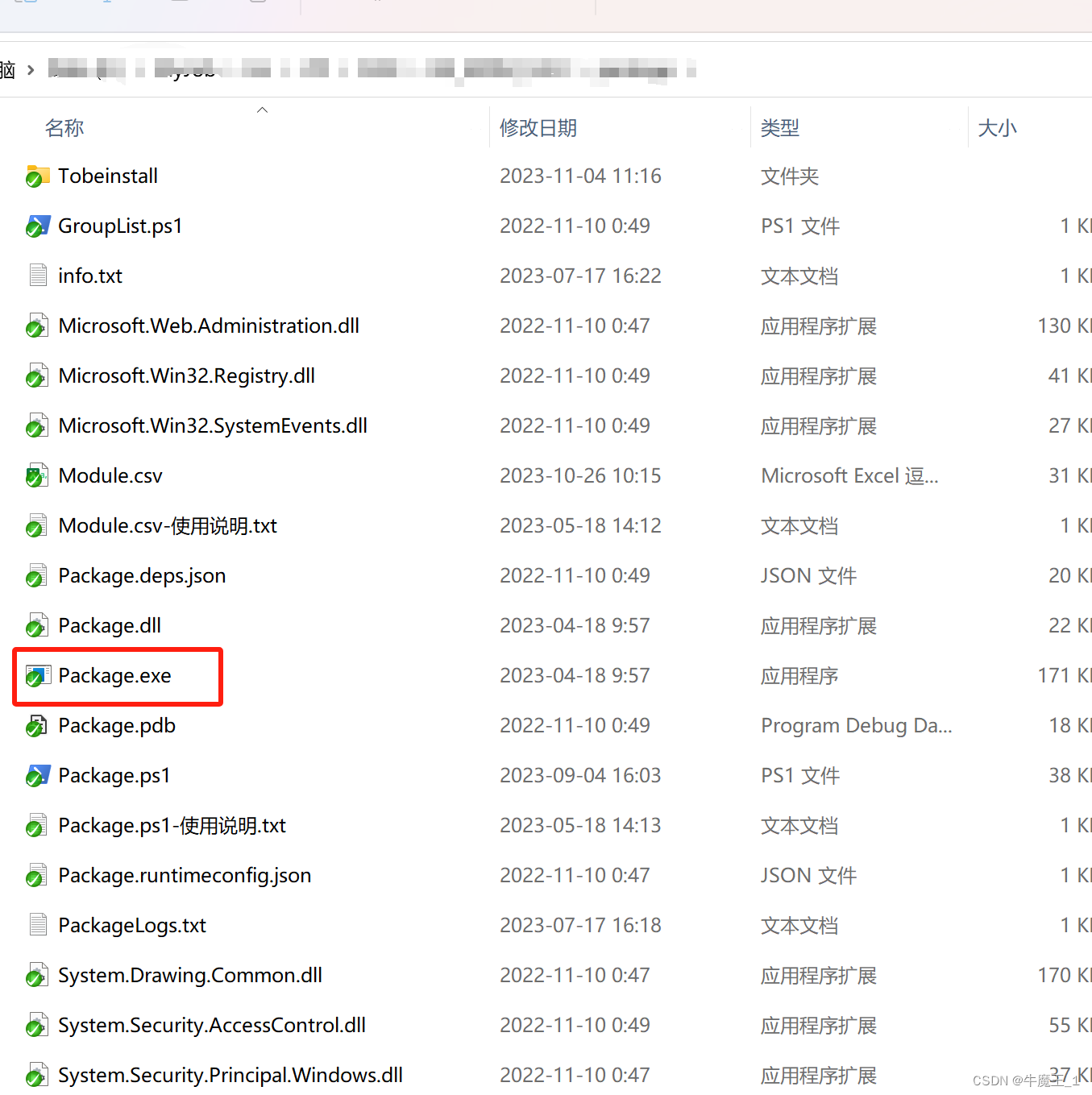
2. 生成运行说明
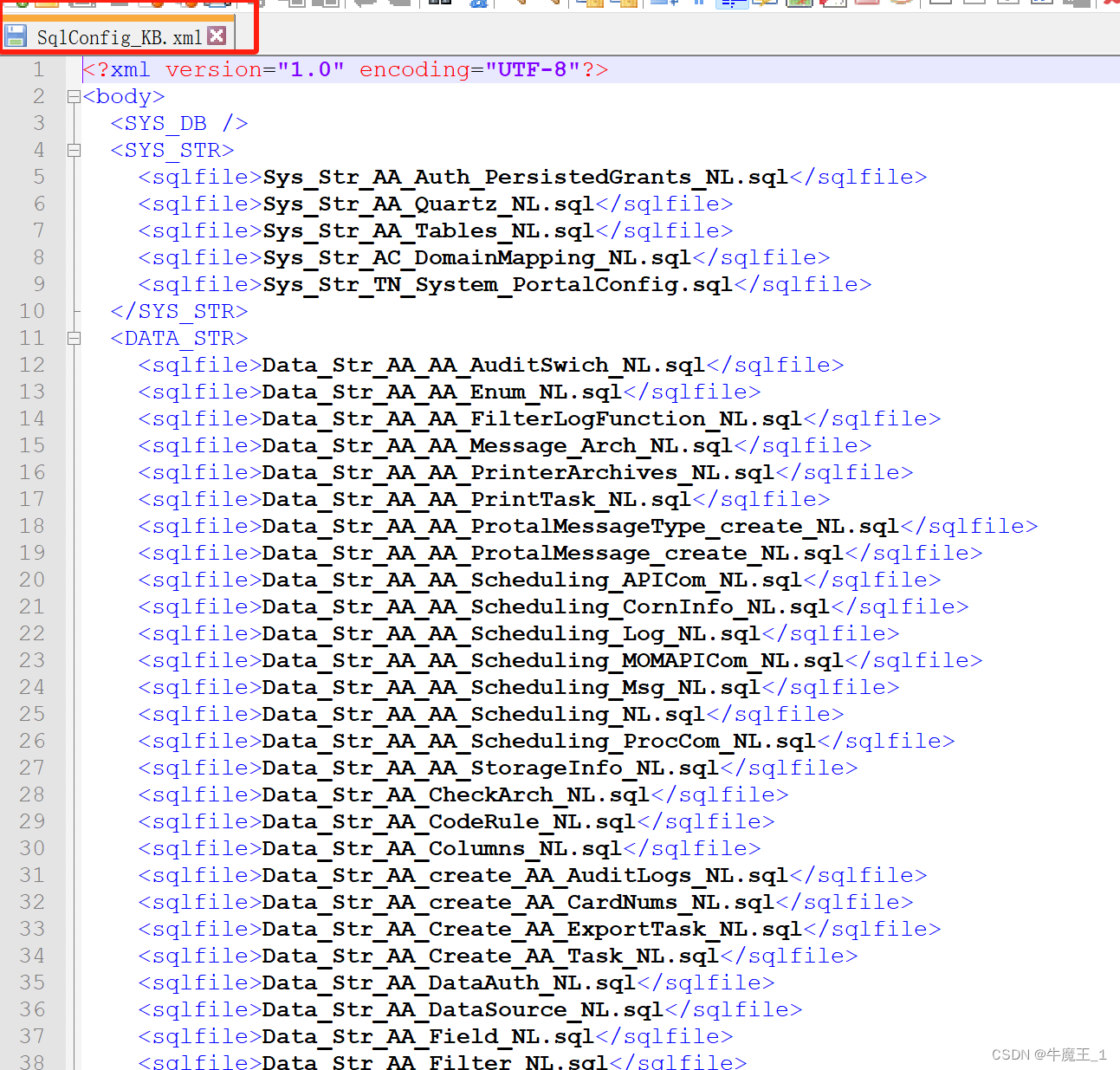
运行Package.exe生成“运行说明”文件,“运行说明”文件其实就是一个 XML,里面指明了脚本运行的数据库和顺序等信息。
如图,补丁包的“运行说明”文件 叫 SqlConfig_KB.xml,只需与脚本执行器DbEngineer.exe 放一个文件夹下即可。

3. 放进安装包
3.1 SqlConfig_KB.xml 与 DbEngineer.exe 放一个文件夹下。
3.2 安装包执行过程中,指定好运行DbEngineer.exe
4. 安装执行
最后只需拿着安装包到相应机器上执行即可,附加运行时截图。
如果脚本执行有错,错误信息会在窗体中显示出来,并告知是哪个脚本报错,方便开发人员查找问题并修改BUG。
如果脚本执行出错,会提供“继续执行”、“跳过” 两个操作给到实施人员,供实施人员灵活选择,在无关脚本报错的情况下,可以“继续执行” 减少部署次数。

工具可以提供给有需要的人使用,有需要的话,可以联系我。Q-3-0-4-4-1-8-2-0-0
