北京网站公司制作长春网络哪家好
总目录 iOS开发笔记目录 从一无所知到入门
文章目录
- Intro
- Developer Documentation 打开方式
- 菜单栏点击 | 快捷键方式
- 另一种打开方式
Intro
2016年我在学校学Java的时候,要查某个Java类/方法的用法还得自己手动下载一种.chm格式的开发文档文件,方便离线查看。
该文档大致就是以下在线文档的离线版:https://docs.oracle.com/javase/8/docs/api/index.html
现在是2023年,学iOS开发,使用的是Xcode14.2:

iOS开发的文档服务已经集成到Xcode中了(一些旧版本的Xcode可能需要你自己下载一些文档压缩包,导入才可以使用)。
时代变了。
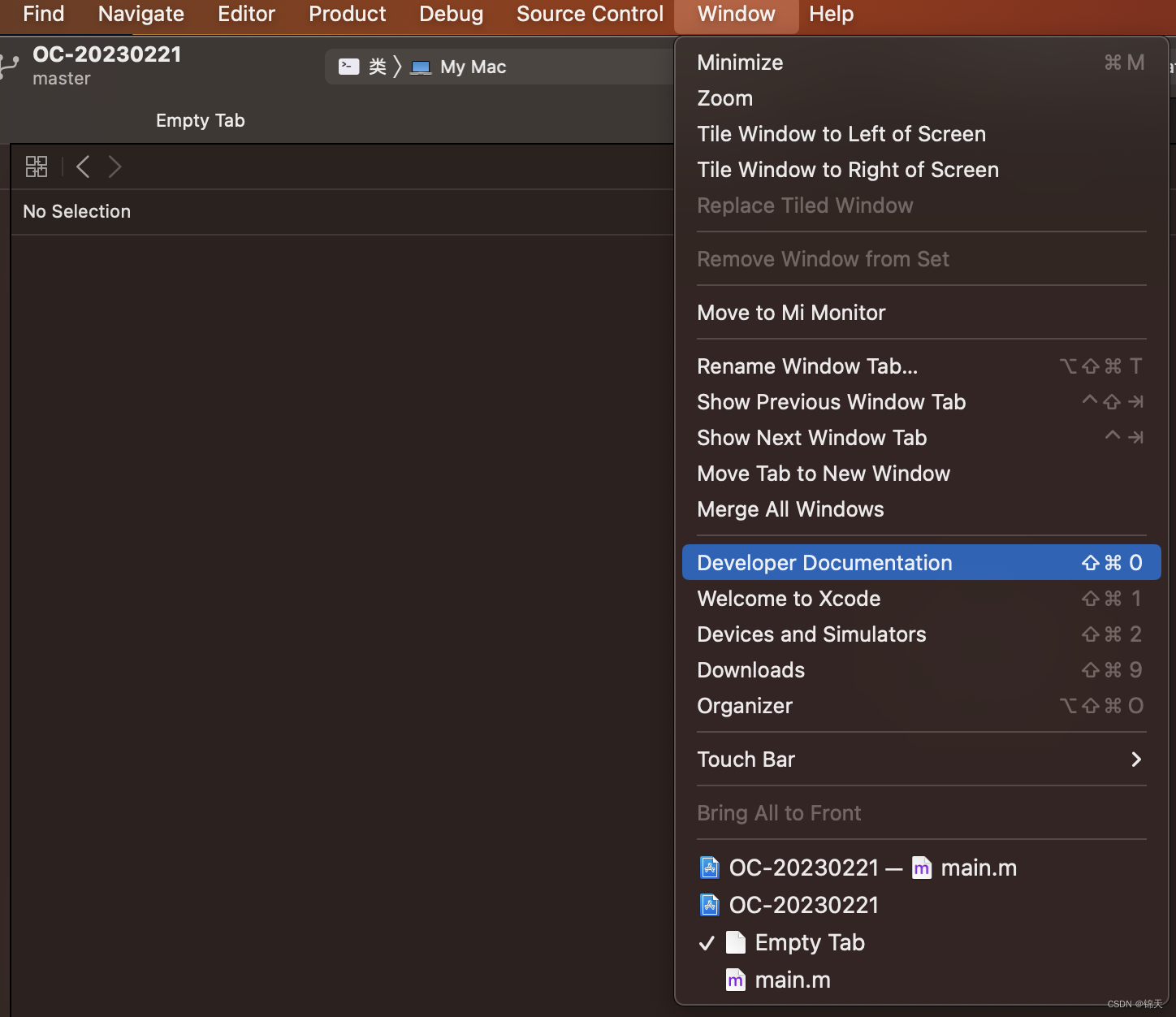
Developer Documentation 打开方式
菜单栏点击 | 快捷键方式
依次点击菜单: Window --> Developer Documentation 或直接按快捷键Command+Shift+0即可呼出开发者文档界面。
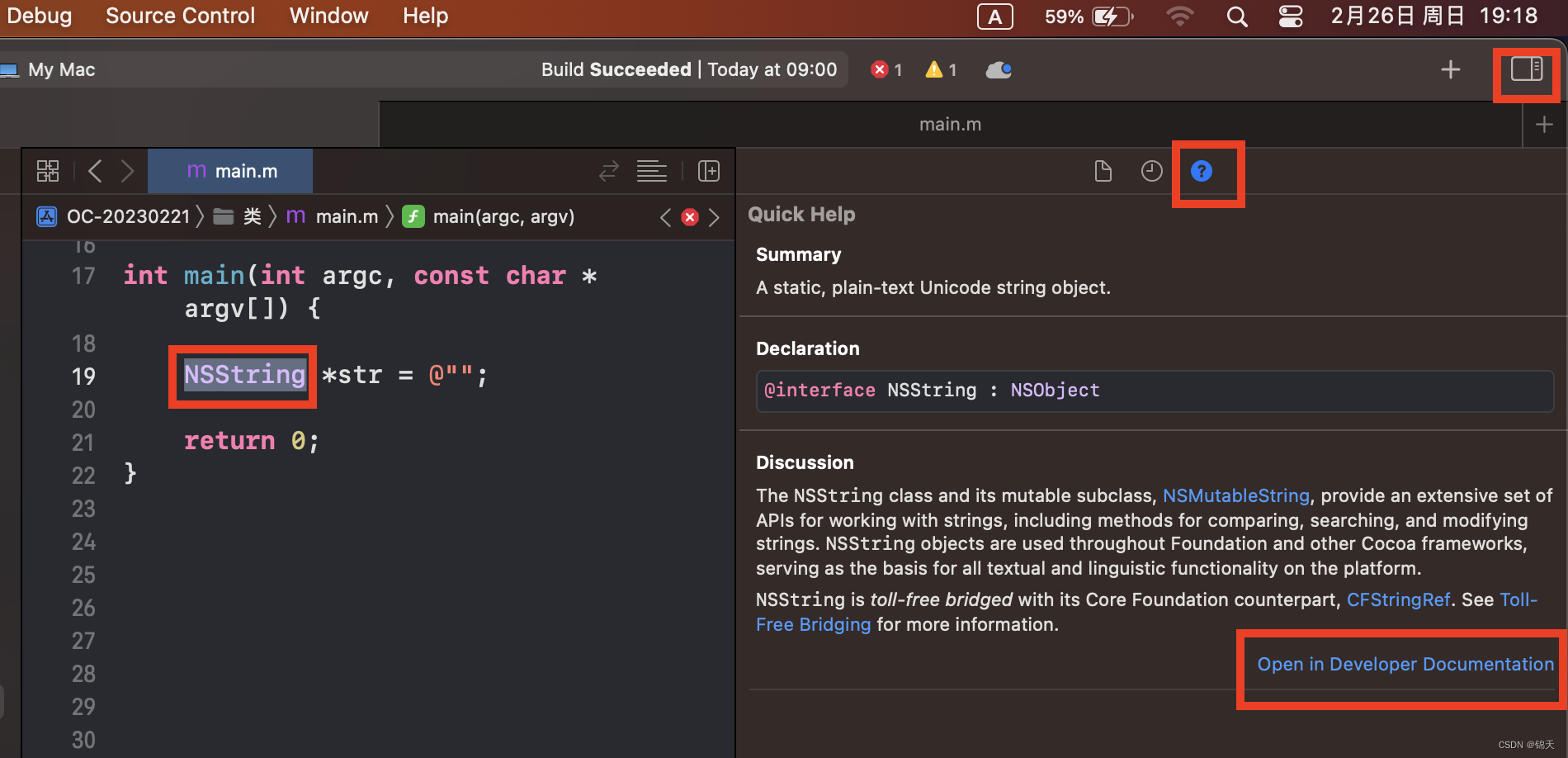
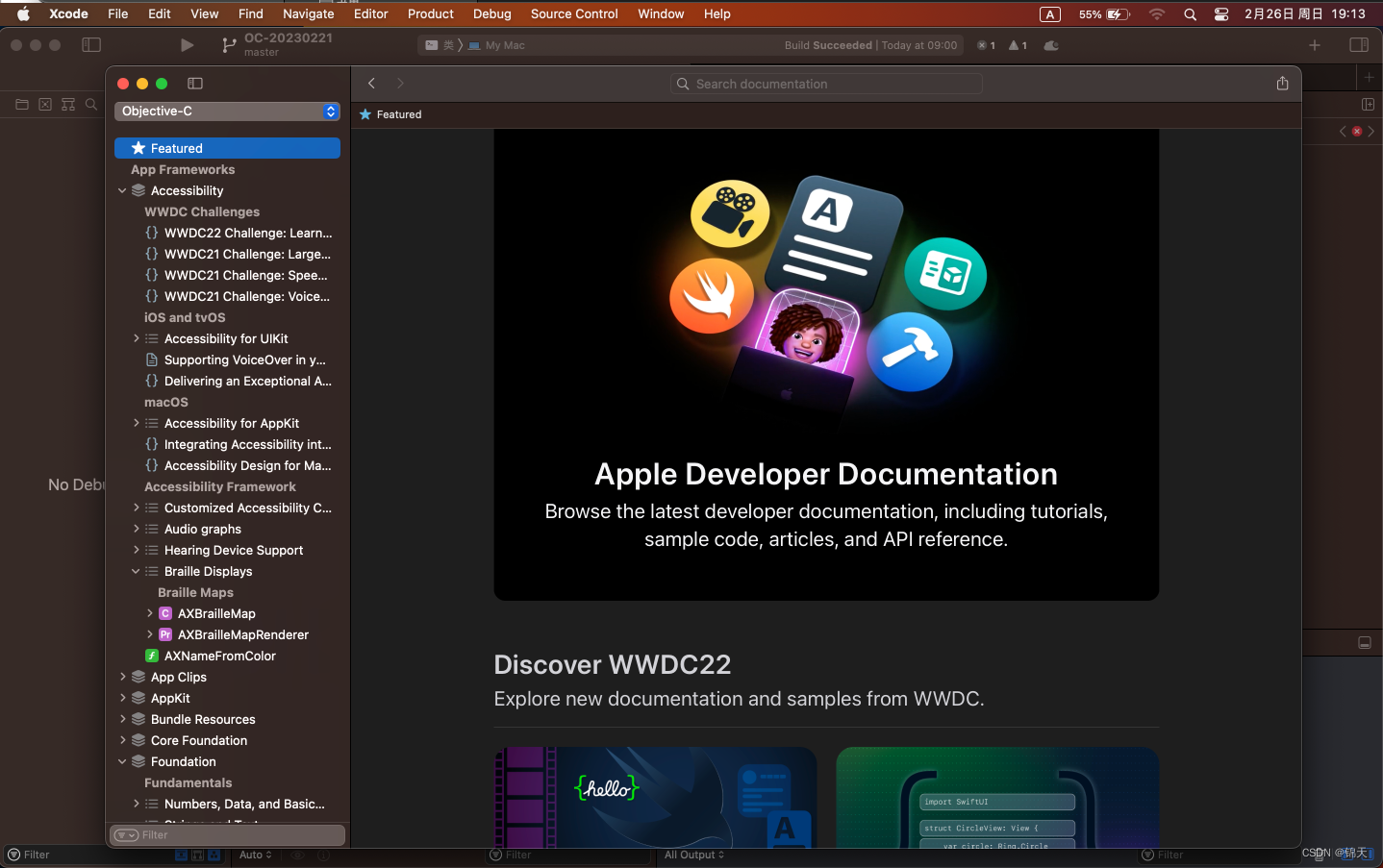
开发者文档界面:
你可以搜索某个类名(左下角Filter处检索),以查看该类的文档:
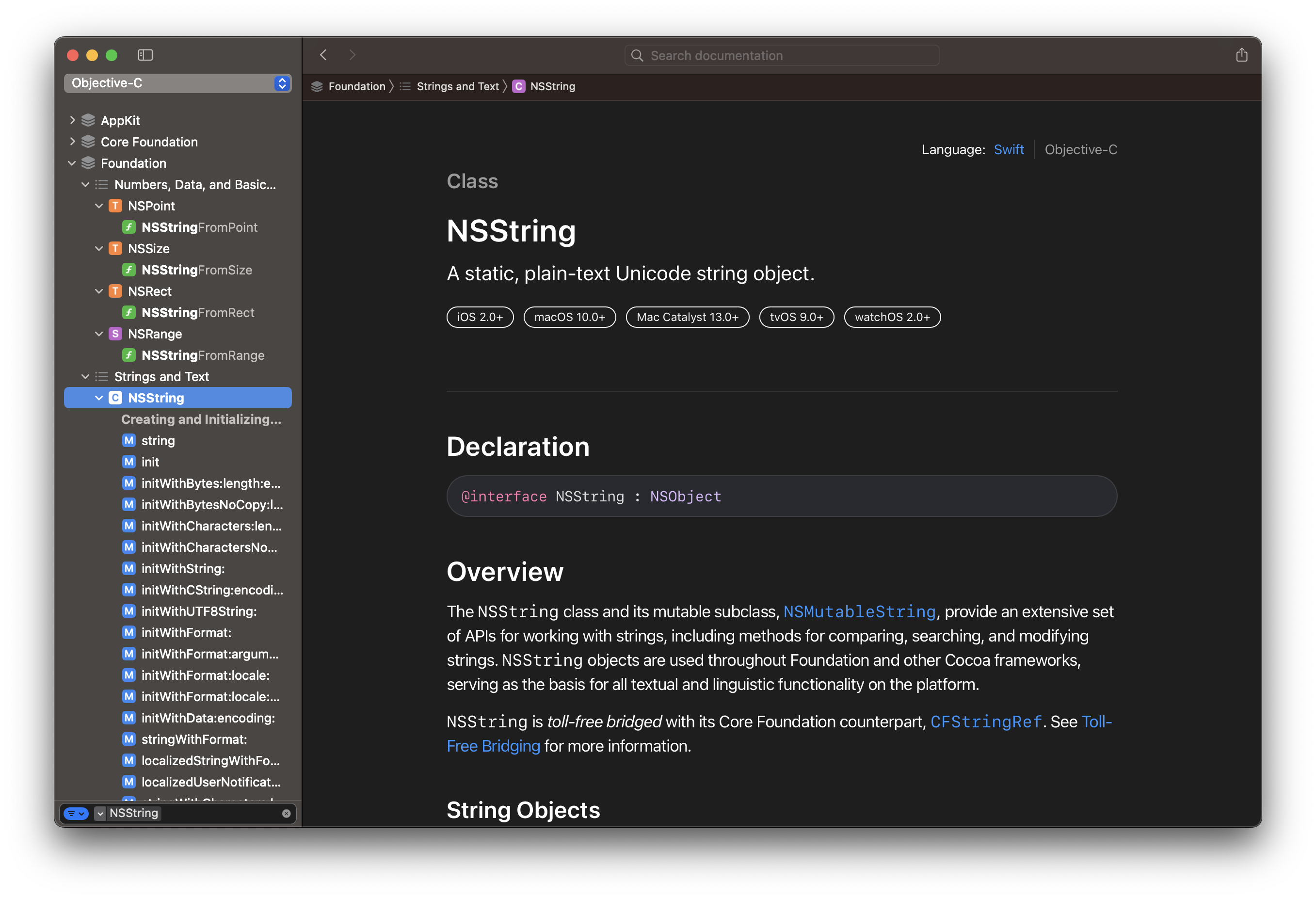 左下角、顶部
左下角、顶部Search documentation处都可以搜索文档内容。
另一种打开方式
在编辑代码的时候,双击选中某个类名/方法名等,
在右侧快速帮助栏下,点击Open in Developer Documentation也可快速打开该类/方法的开发者文档,并定位至该类/方法处。