做机械设备的做哪个网站推广较好做外贸网站平台
目录
C++设计模式-原型(Prototype)
一、意图
二、适用性
三、结构
四、参与者
五、代码
C++设计模式-原型(Prototype)
一、意图
用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。
二、适用性
- 当要实例化的类是在运行时刻指定时,例如,通过动态装载;或者
- 为了避免创建一个与产品类层次平行的工厂类层次时;或者
- 当一个类的实例只能有几个不同状态组合中的一种时。建立相应数目的原型并克隆它们可能比每次用合适的状态手工实例化该类更方便一些。
三、结构
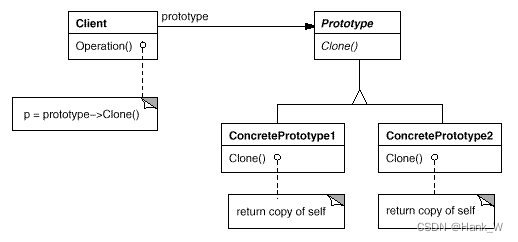
四、参与者
- Prototype
声明一个克隆自身的接口。
- ConcretePrototype
实现一个克隆自身的操作。
- Client
让一个原型克隆自身从而创建一个新的对象。
五、代码
#include<iostream>
using namespace std;class Product {
public:virtual Product* Clone() = 0;virtual void Display() = 0;
};class ConcreteProduct : public Product {
public:ConcreteProduct(){}ConcreteProduct(string TempName, string TempID) : name(TempName), id(TempID){}void SetName(string TempName) {this->name = TempName;}void SetID(string TempID) {this->id = TempID;}ConcreteProduct* Clone() {return new ConcreteProduct(this->name, this->id);}void Display() {cout << "Name: " << this->name << endl;cout << "ID: " << this->id << endl;}
private:string name;string id;
};int main() {ConcreteProduct* originalProduct = new ConcreteProduct("Product One", "1");cout << "Original Product Information:" << endl;originalProduct->Display();ConcreteProduct* copyProduct = originalProduct->Clone();cout << "Copy Product Information Unchanged:" << endl;copyProduct->Display();copyProduct->SetName("Product Two");copyProduct->SetID("2");cout << "Copy Product Information Changed:" << endl;copyProduct->Display();}