廊坊手机网站建设英语网站都可以做哪些内容
项目介绍
一款免费的数据可视化报表工具,含报表和大屏设计,像搭建积木一样在线设计报表!功能涵盖,数据报表、打印设计、图表报表、大屏设计等!
- Web 版报表设计器,类似于excel操作风格,通过拖拽完成报表设计。
- 秉承"简单、易用、专业"的产品理念,极大的降低报表开发难度、缩短开发周期、节省成本、解决各类报表难题。
- 领先的企业级Web报表,采用纯Web在线技术,专注于解决企业报表快速制作难题。
当前版本:v1.7.6 | 2024-06-19
集成依赖
<dependency><groupId>org.jeecgframework.jimureport</groupId><artifactId>jimureport-spring-boot-starter</artifactId><version>1.7.6</version>
</dependency>升级日志
紧急补正版本,修复1.7.52发现的严重BUG.
新功能
- 【严重bug】v1.7.52合并单元格不生效
- 【严重bug】v1.7.52数据集字段点击,会将数据集合并
- 【严重bug】v1.7.52背景图设置启用背景,上传一张背景图片,发现启用背景自己关闭了
- 【严重bug】v1.7.52颜色选择器没有确定按钮了,导致保存不上
- 【严重bug】v1.7.52展示oracle数据源的报表报错 #2687
- 【严重bug】数据源创建数超限,不影响其他正常操作,不影响报表预览
- 火狐浏览器双击空白单元格没输入竖线
- 删除报表同时是删除关联数据
- 模板功能措辞修改,收藏模板
- 列表视图下,顶部操作按钮配置在一行
- 模版在视图下不可编辑,切换到列表下,可编辑了
- json数据源,配置查询后,导出excel和导出pdf不好使了
- 数据源列表排序应该按照创建和编辑时间倒序排列
- 导出pdf图像报错,图片下载失败
代码下载
- https://github.com/jeecgboot/JimuReport
- https://gitee.com/jeecg/JimuReport
技术文档
- 体验官网: http://jimureport.com
- 快速集成文档 :https://help.jeecg.com/jimureport/quick.html
- 技术文档: https://help.jeecg.com/jimureport
为什么选择 JimuReport?
永久免费,支持各种复杂报表,并且傻瓜式在线设计,非常的智能,低代码时代,这个是你的首选!
- 采用SpringBoot的脚手架项目,都可以快速集成
- Web 版设计器,类似于excel操作风格,通过拖拽完成报表设计
- 通过SQL、API等方式,将数据源与模板绑定。同时支持表达式,自动计算合计等功能,使计算工作量降低
- 开发效率很高,傻瓜式在线报表设计,一分钟设计一个报表,又简单又强大
- 支持 ECharts,目前支持28种图表,在线拖拽设计,支持SQL和API两种数据源
- 支持分组、交叉,合计、表达式等复杂报表
- 支持打印设计(支持套打、背景打印等)可设置打印边距、方向、页眉页脚等参数 一键快速打印 同时可实现套打,不动产证等精准、无缝打印
- 大屏设计器支持几十种图表样式,可自由拼接、组合,设计炫酷大屏
- 可设计各种类型的单据、大屏,如出入库单、销售单、财务报表、合同、监控大屏、旅游数据大屏等
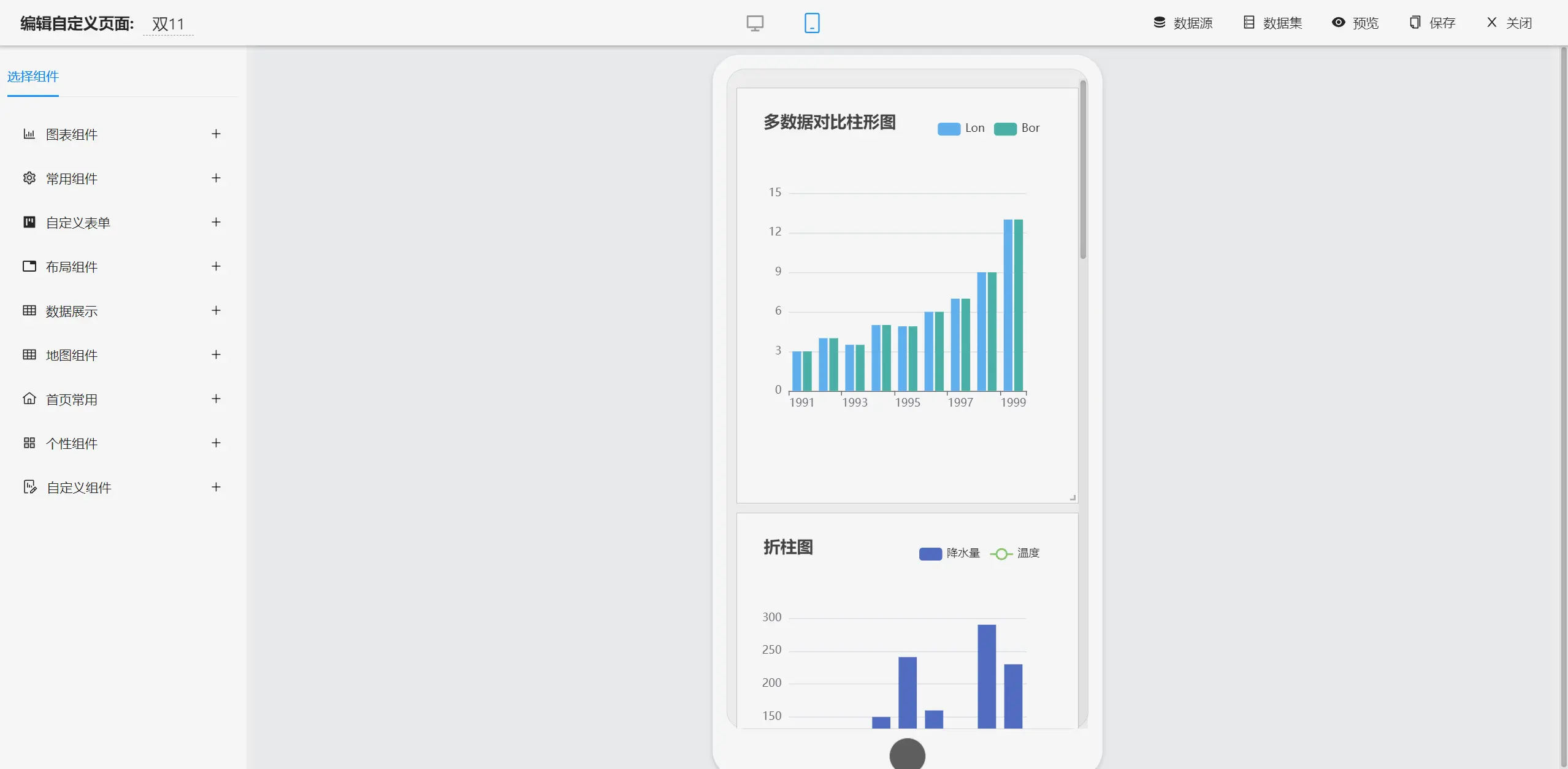
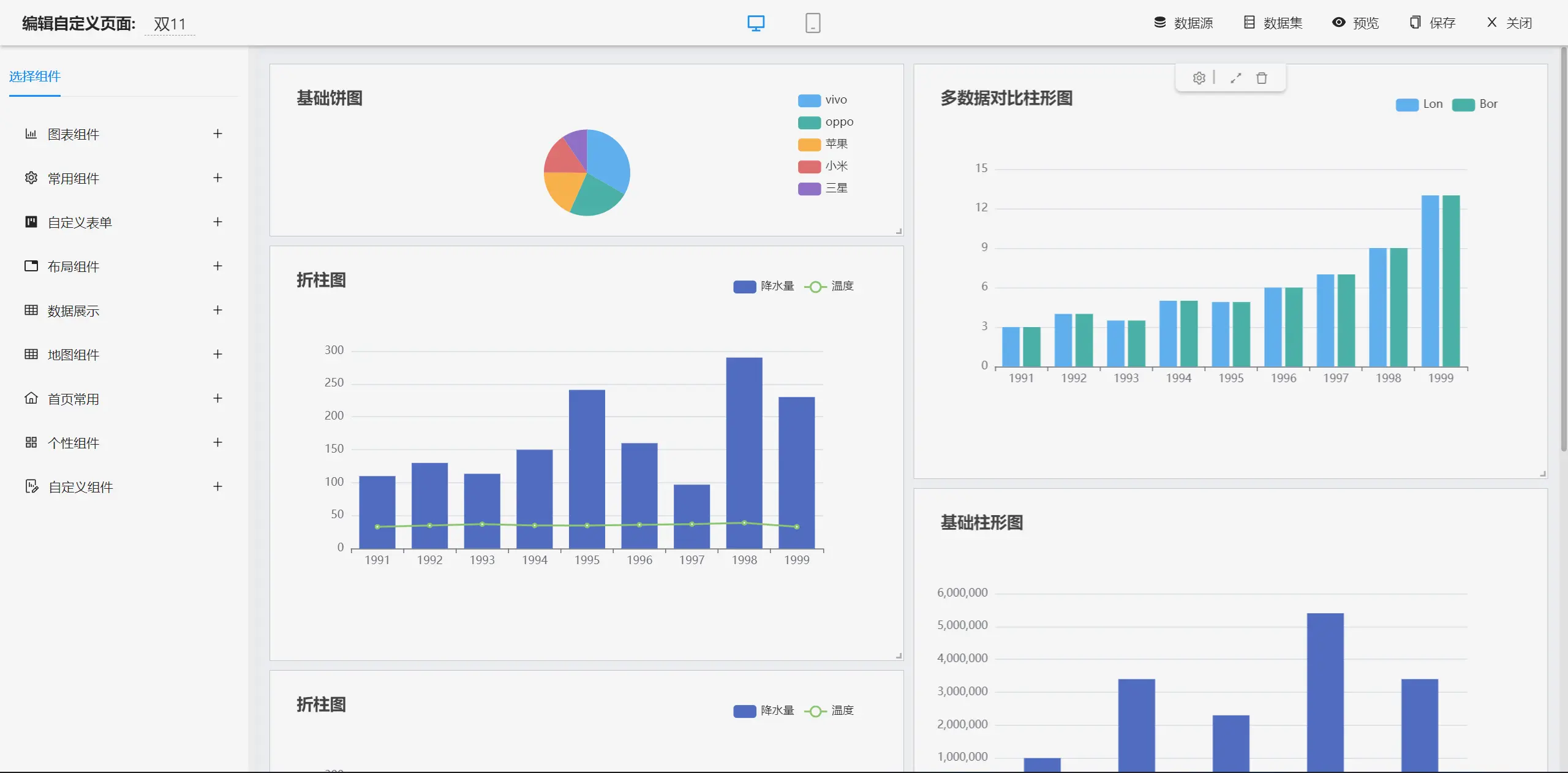
报表设计效果
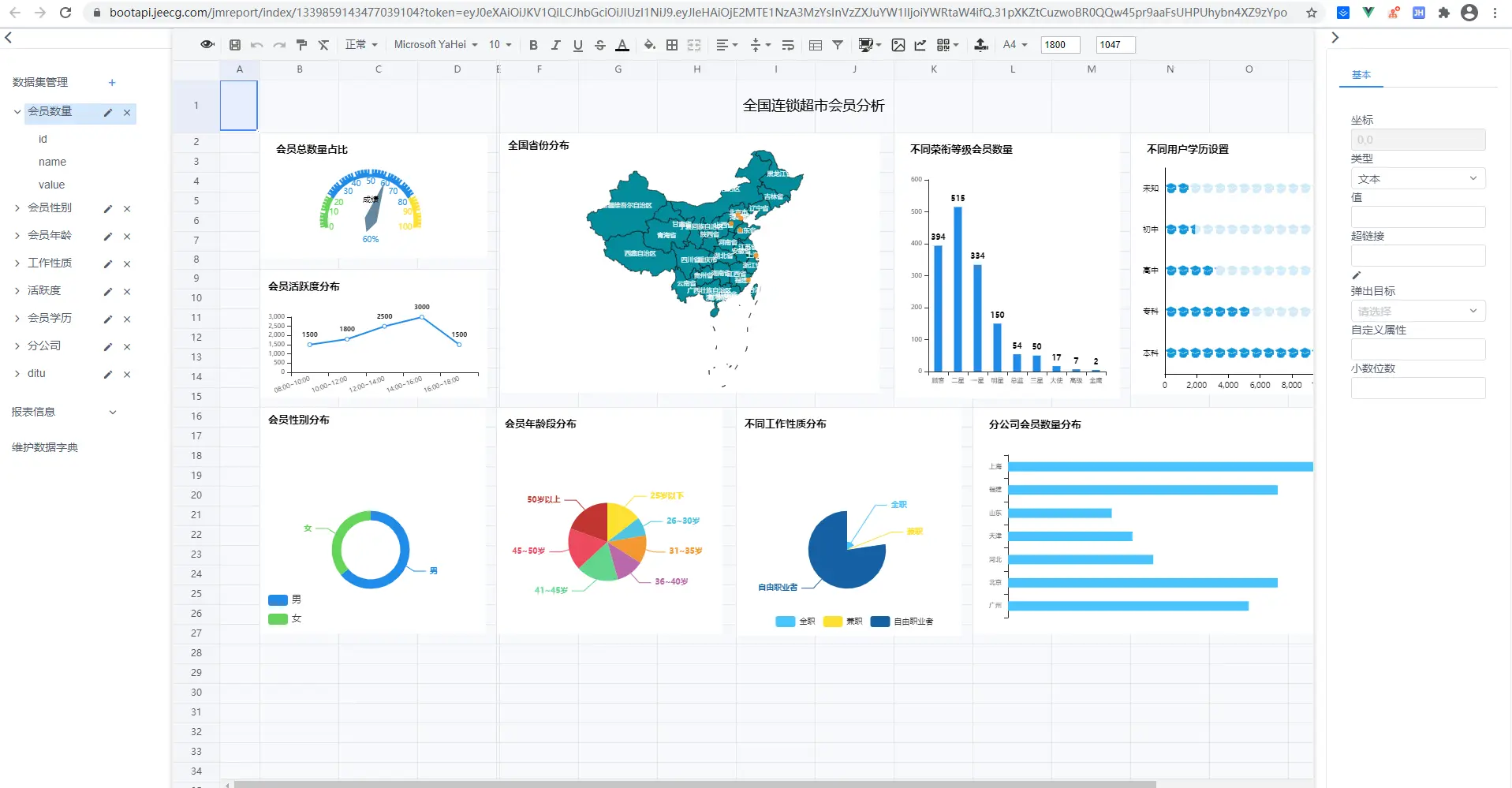
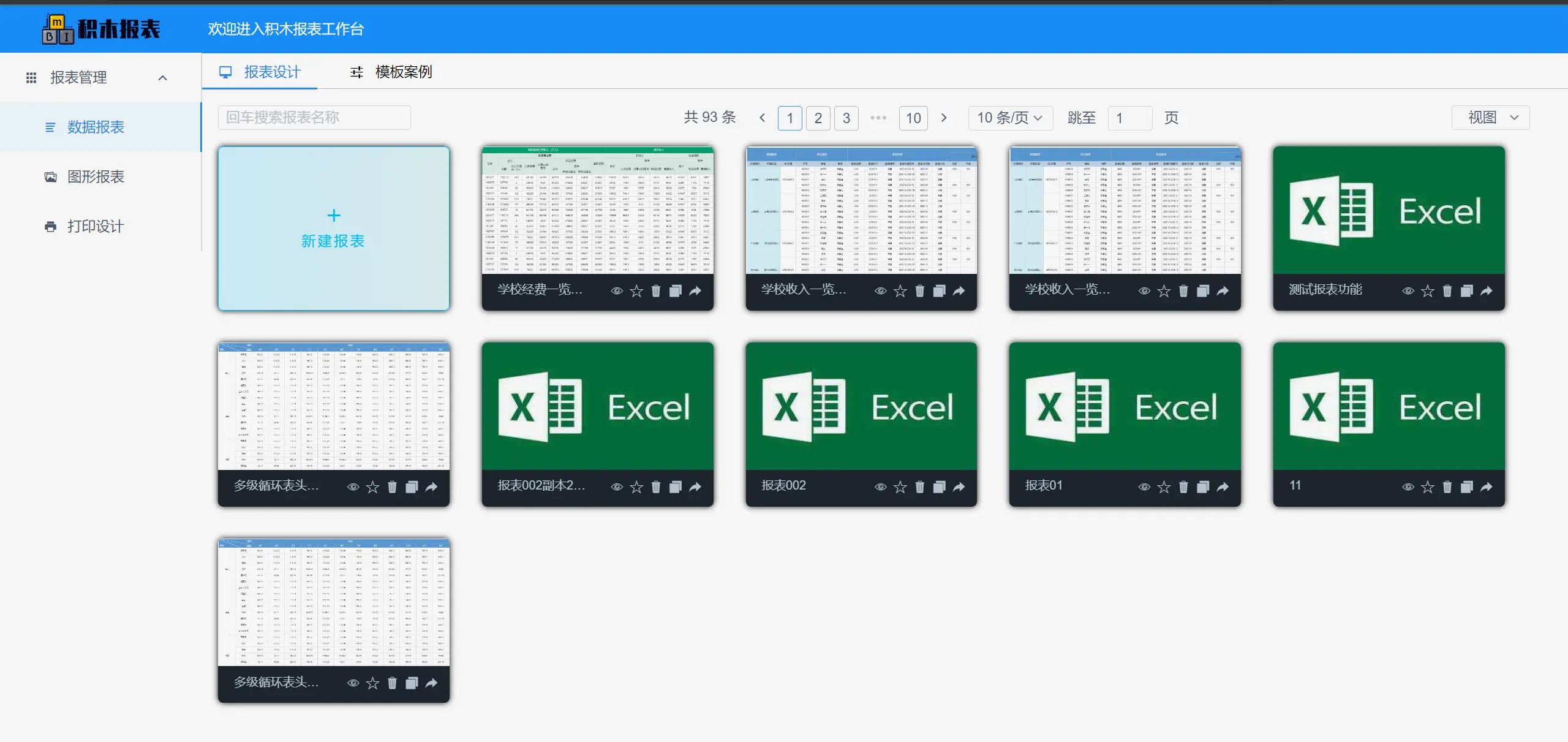


仪表盘设计器
功能清单
├─报表设计器
│ ├─数据源
│ │ ├─支持多种数据源,如Oracle,MySQL,SQLServer,PostgreSQL等主流的数据库
│ │ ├─支持SQL编写页面智能化,可以看到数据源下面的表清单和字段清单
│ │ ├─支持参数
│ │ ├─支持单数据源和多数数据源设置
│ │ ├─支持Nosql数据源Redis,MongoDB
│ │ ├─支持存储过程
│ ├─单元格格式
│ │ ├─边框
│ │ ├─字体大小
│ │ ├─字体颜色
│ │ ├─背景色
│ │ ├─字体加粗
│ │ ├─支持水平和垂直的分散对齐
│ │ ├─支持文字自动换行设置
│ │ ├─图片设置为图片背景
│ │ ├─支持无线行和无限列
│ │ ├─支持设计器内冻结窗口
│ │ ├─支持对单元格内容或格式的复制、粘贴和删除等功能
│ │ ├─等等
│ ├─报表元素
│ │ ├─文本类型:直接写文本;支持数值类型的文本设置小数位数
│ │ ├─图片类型:支持上传一张图表;支持图片动态生成
│ │ ├─图表类型
│ │ ├─函数类型
│ │ └─支持求和
│ │ └─平均值
│ │ └─最大值
│ │ └─最小值
│ ├─背景
│ │ ├─背景颜色设置
│ │ ├─背景图片设置
│ │ ├─背景透明度设置
│ │ ├─背景大小设置
│ ├─数据字典
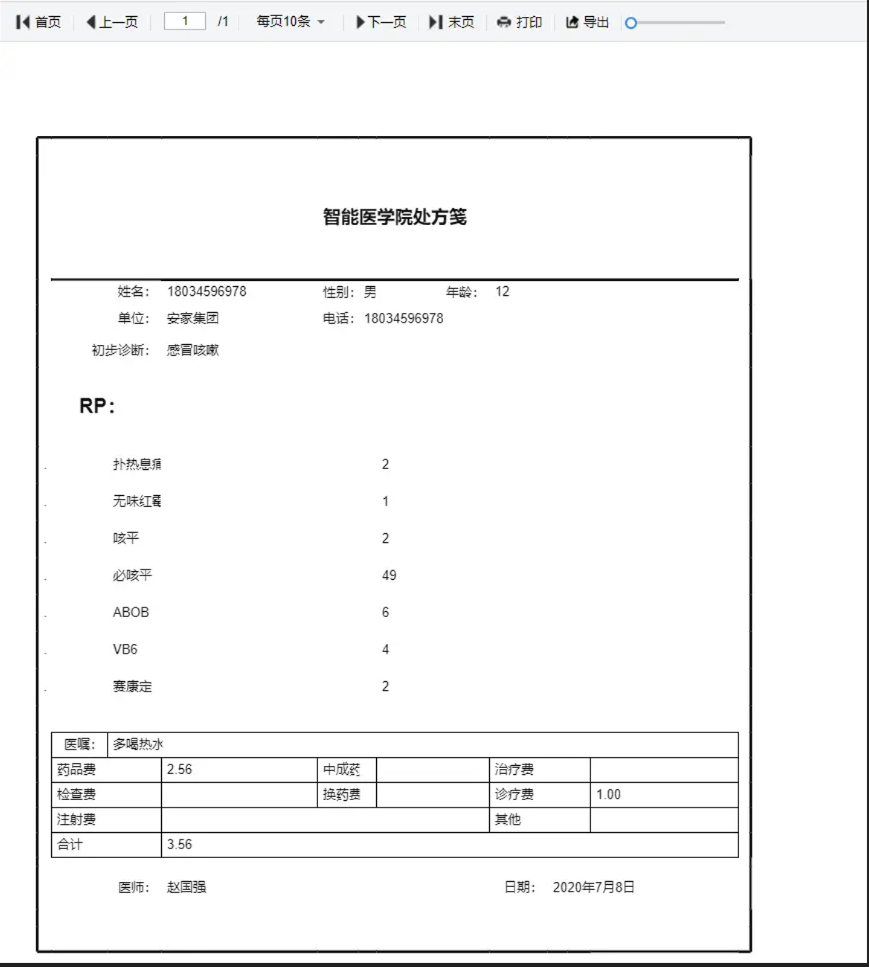
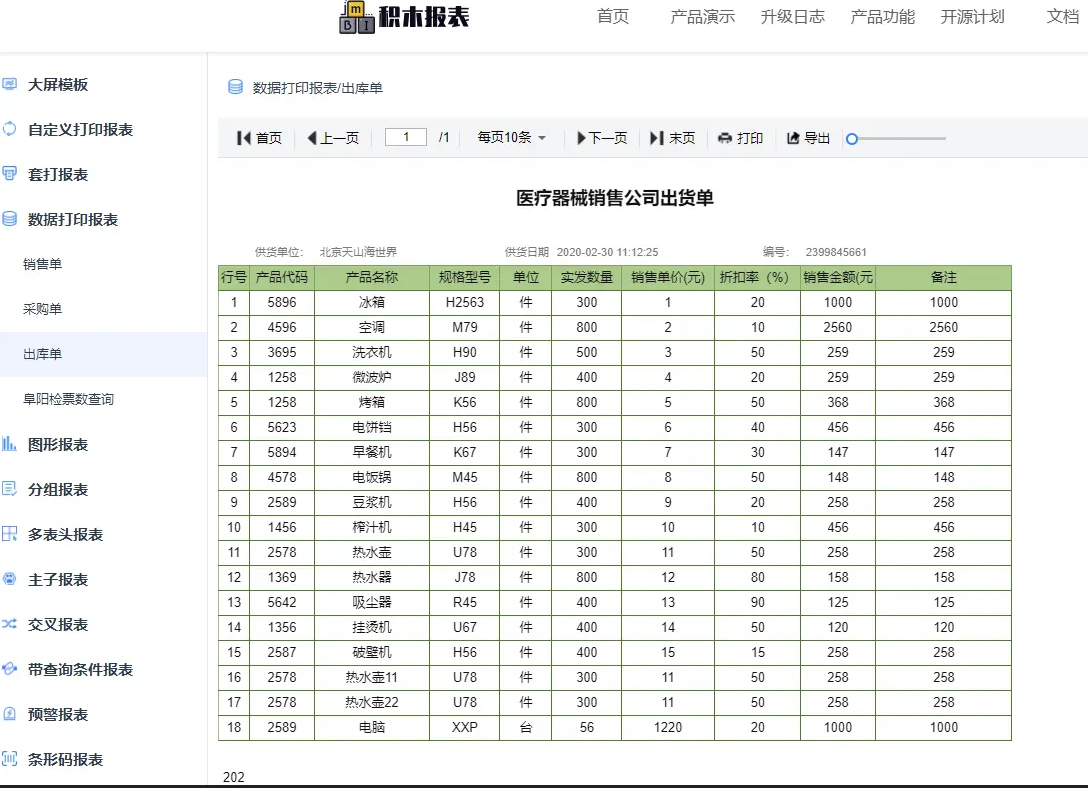
│ ├─报表打印
│ │ ├─自定义打印
│ │ └─医药笺、逮捕令、介绍信等自定义样式设计打印
│ │ ├─简单数据打印
│ │ └─出入库单、销售表打印
│ │ └─带参数打印
│ │ └─分页打印
│ │ ├─套打
│ │ └─不动产证打印
│ │ └─打印
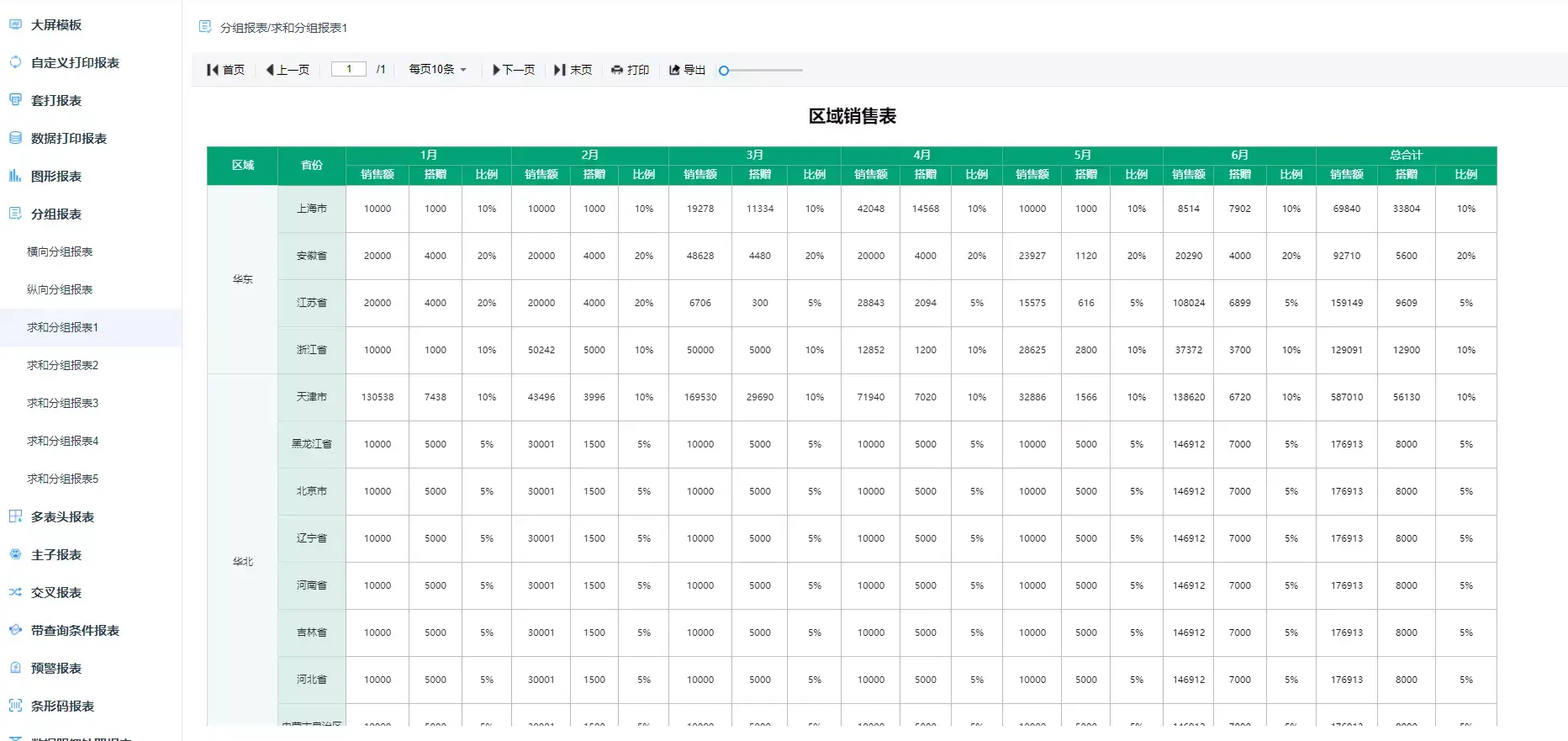
│ ├─数据报表
│ │ ├─分组数据报表
│ │ └─横向数据分组
│ │ └─纵向数据分组
│ │ └─多级循环表头分组
│ │ └─横向分组小计
│ │ └─纵向分组小计
│ │ └─分版
│ │ └─分栏
│ │ └─动态合并格
│ │ └─自定义分页条数
│ │ └─合计
│ │ ├─交叉报表
│ │ ├─明细表
│ │ ├─带条件查询报表
│ │ ├─表达式报表
│ │ ├─带二维码/条形码报表
│ │ ├─多表头复杂报表
│ │ ├─主子报表
│ │ ├─预警报表
│ │ ├─数据钻取报表
│ ├─图形报表
│ │ ├─柱形图
│ │ ├─堆叠柱形图
│ │ ├─折线图
│ │ ├─饼图
│ │ ├─动态轮播图
│ │ ├─折柱图
│ │ ├─散点图
│ │ ├─漏斗图
│ │ ├─雷达图
│ │ ├─象形图
│ │ ├─地图
│ │ ├─仪盘表
│ │ ├─关系图
│ │ ├─图表背景
│ │ ├─图表动态刷新
│ │ ├─图表数据字典
│ ├─参数
│ │ ├─参数配置
│ │ ├─参数管理
│ ├─导入导出
│ │ ├─支持导入Excel
│ │ ├─支持导出Excel、pdf;支持导出excel、pdf带参数
│ ├─打印设置
│ │ ├─打印区域设置
│ │ ├─打印机设置
│ │ ├─预览
│ │ ├─打印页码设置
├─大屏设计器
│ ├─系统功能
│ │ ├─静态数据源和动态数据源设置
│ │ ├─基础功能
│ │ └─支持拖拽设计
│ │ └─支持增、删、改、查大屏
│ │ └─支持复制大屏数据和样式
│ │ └─支持大屏预览、分享
│ │ └─支持系统自动保存数据,同时支持手动恢复数据
│ │ └─支持设置大屏密码
│ │ └─支持对组件图层的删除、组合、上移、下移、置顶、置底等
│ │ ├─背景设置
│ │ └─大屏的宽度和高度设置
│ │ └─大屏简介设置
│ │ └─背景颜色、背景图片设置
│ │ └─封面图设置
│ │ └─缩放比例设置
│ │ └─环境地址设置
│ │ └─水印设置
│ │ ├─地图设置
│ │ └─添加地图
│ │ └─地图数据隔离
│ ├─图表
│ │ ├─柱形图
│ │ ├─折线图
│ │ ├─折柱图
│ │ ├─饼图
│ │ ├─象形图
│ │ ├─雷达图
│ │ ├─散点图
│ │ ├─漏斗图
│ │ ├─文本框
│ │ ├─跑马灯
│ │ ├─超链接
│ │ ├─实时时间
│ │ ├─地图
│ │ ├─全国物流地图
│ │ ├─地理坐标地图
│ │ ├─城市派件地图
│ │ ├─图片
│ │ ├─图片框
│ │ ├─轮播图
│ │ ├─滑动组件
│ │ ├─iframe
│ │ ├─video
│ │ ├─翻牌器
│ │ ├─环形图
│ │ ├─进度条
│ │ ├─仪盘表
│ │ ├─字浮云
│ │ ├─表格
│ │ ├─选项卡
│ │ ├─万能组件
└─其他模块└─更多功能开发中。。