海南省住房和城市建设厅网站网站建设书籍论文
基于JSP+Servlet+mysql员工权限管理系统
- 一、系统介绍
- 二、功能展示
- 四、其他系统实现
- 五、获取源码
一、系统介绍
项目类型:Java web项目
项目名称:基于JSP+Servlet的员工权限管理系统[qxxt]
项目架构:B/S架构
开发语言:Java语言
前端技术:HTML、CSS、JS、JQuery等技术
后端技术:JSP、Servlet、JDBC等技术
运行环境:Win10、JDK1.8
数 据 库:MySQL5.7及以上
运行服务器:Tomcat8.0及以上
运行工具:Eclipse\MYEclipse\IDEA。
非常适合学习。
项目简介:登录、主要是对员工权限、角色、员工信息的增删改查。
二、功能展示
项目内容

项目骨架
项目部分运行截图
登录界面
角色列表

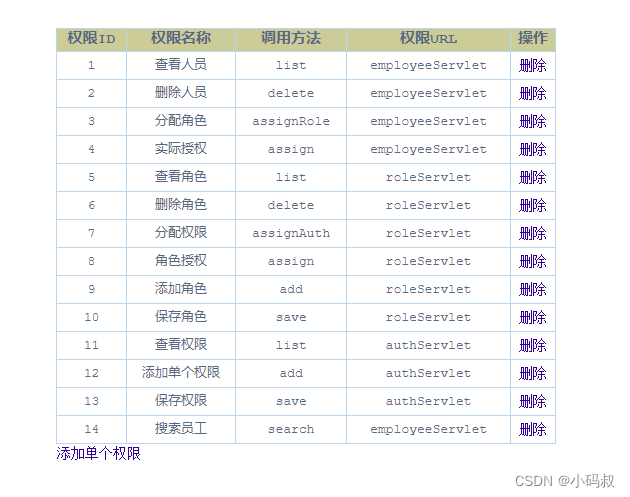
权限列表
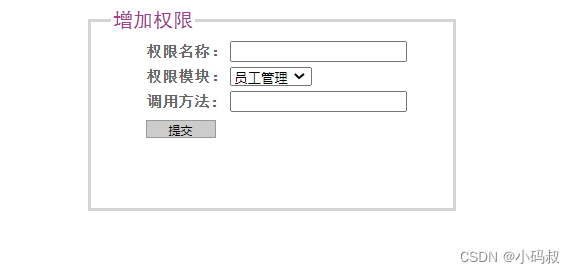
图片添加权限
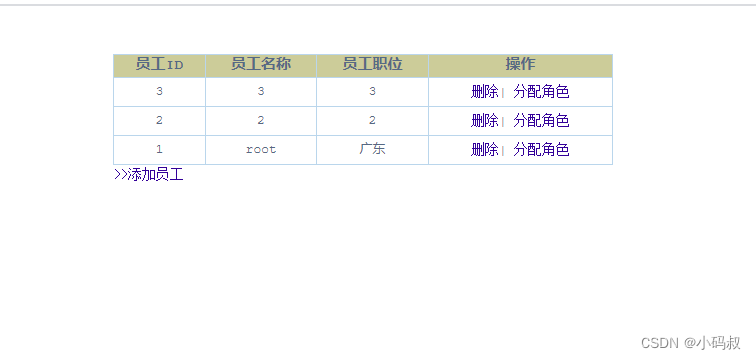
员工列表
四、其他系统实现
Java+Swing实现学生选课管理系统
Java+Swing实现学校教务管理系统
Java+Swing+sqlserver学生成绩管理系统
Java+Swing用户信息管理系统
Java+Swing实现的五子棋游戏
基于JavaSwing 银行管理系统
Java+Swing+mysql仿QQ聊天工具
Java+Swing 聊天室
Java+Swing+dat文件存储实现学生选课管理系统
Java+Swing可视化图像处理软件
Java+Swing学生信息管理系统
Java+Swing图书管理系统
Java+Swing图书管理系统2.0
基于java+swing+mysql图书管理系统3.0
大作业-基于java+swing+mysql北方传统民居信息管理系统
五、获取源码
点击下载
基于JSP+Servlet+mysql员工权限管理系统