苏州做i网站的wordpress添加表格
目录
技术栈
1.后端接口实现
2.前端实现
2.1 实现静态结构
2.2 整合上传文件的数据
2.3 实现一键上传文件
2.4 取消上传
博客主页:専心_前端,javascript,mysql-CSDN博客
系列专栏:vue3+nodejs 实战--文件上传
前端代码仓库:jiangjunjie666/my-upload: vue3+nodejs 上传文件的项目,用于学习 (github.com)
后端代码仓库:jiangjunjie666/my-upload-server: nodejs上传文件的后端 (github.com)
欢迎关注
在上一篇中,我们创建好了前端Vue3,后端nodejs的项目,并且实现了一个图片上传的功能,地址在: Vue3 + Nodejs 实战 ,文件上传项目--实现图片上传-CSDN博客 ,该篇实现了文件的批量上传并且显示实时的上传进度。
技术栈
前端:Vue3 Vue-router axios element-plus...
后端:nodejs express...
1.后端接口实现
我们先把后端上传文件的接口写好,后端接收文件我用的并不是原生的js,用的是:formidable,所以没看过上一篇创建项目的一定要去看看喔。Vue3 + Nodejs 实战 ,文件上传项目--实现图片上传-CSDN博客
在路由文件中新增一个接口
//上传文件
router.post('/fileUpload', handler.fileUp)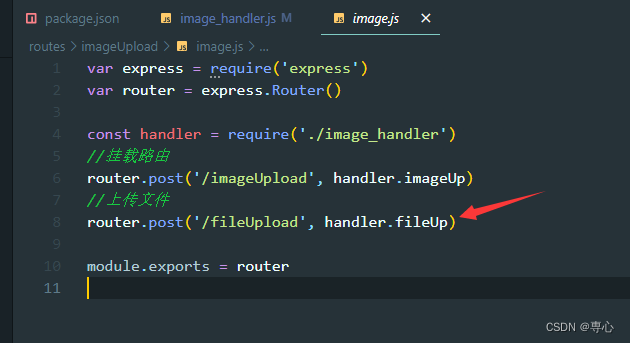
在处理函数文件中编写接口函数
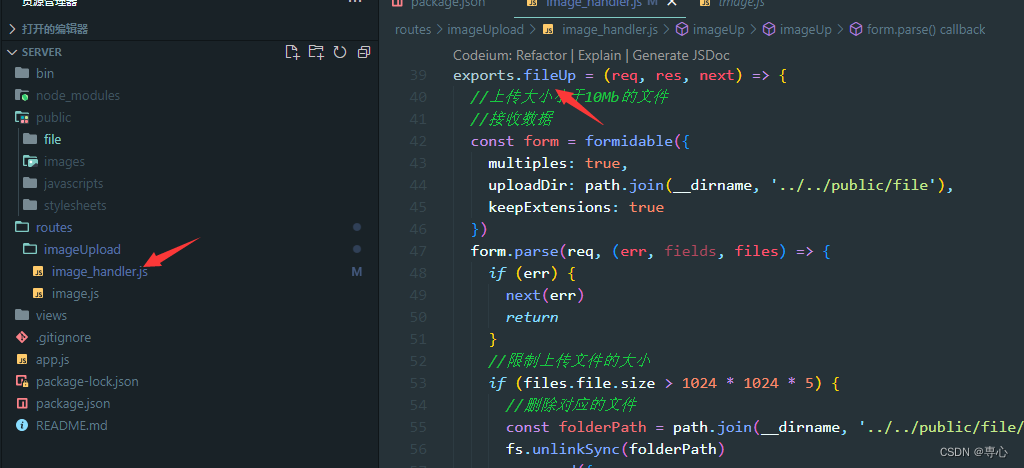
其实后端这次的代码和上一篇中的上传图片代码相差不大,无非就是进行一些文件大小控制,返回相应等,不过我新增了个保留原始的文件名的方法,用的是fs模块中的重命名方法。
其中上传的路径放在了public下的file文件夹中了,这个你们可以根据自己的喜好进行更改。
exports.fileUp = (req, res, next) => {//上传大小小于5Mb的文件//接收数据const form = formidable({multiples: true,uploadDir: path.join(__dirname, '../../public/file'),keepExtensions: true})form.parse(req, (err, fields, files) => {if (err) {next(err)return}//限制上传文件的大小if (files.file.size > 1024 * 1024 * 5) {//删除对应的文件const folderPath = path.join(__dirname, '../../public/file/' + files.file.newFilename) // 文件路径fs.unlinkSync(folderPath)res.send({code: 400,msg: '上传文件过大'})return}//修改保存文件的默认nameconst folderPath = path.join(__dirname, '../../public/file/' + files.file.newFilename) // 文件路径let newName = path.join(__dirname, '../../public/file/' + files.file.originalFilename)//对读取的文件进行重命名console.log(newName)fs.rename(folderPath, newName, (err) => {if (err) {console.log(err)return} else {console.log('重命名成功')res.send({code: 200,msg: '上传成功'})}})})
}
这就是接口函数了
上一篇中漏讲了一个地方,就是路由要在app.js中进行注册,否则该接口是调用不了的,不过有nodejs基础的应该都能想到这个问题了。
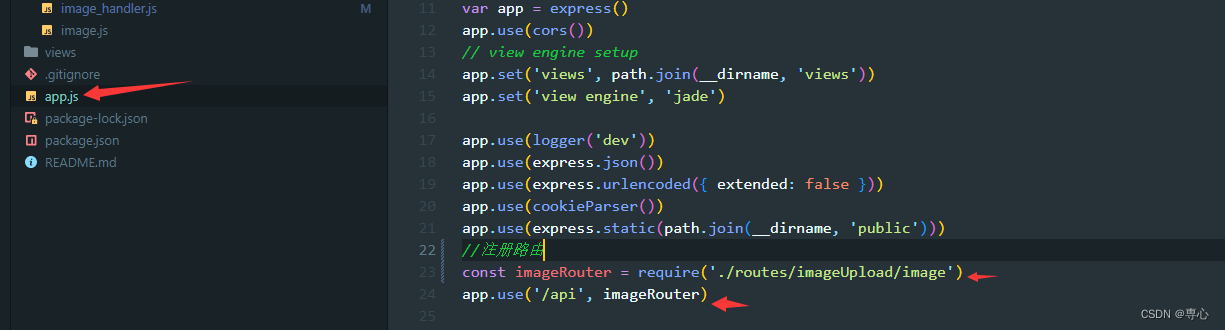
这样注册以后接口就可以正常访问了,不过注意我这里接口带了/api,所以在前端调用时记得带上/api。
2.前端实现
2.1 实现静态结构
我想到的是这样一种效果,可以显示文件名,文件的大小,文件的上传状态等等信息
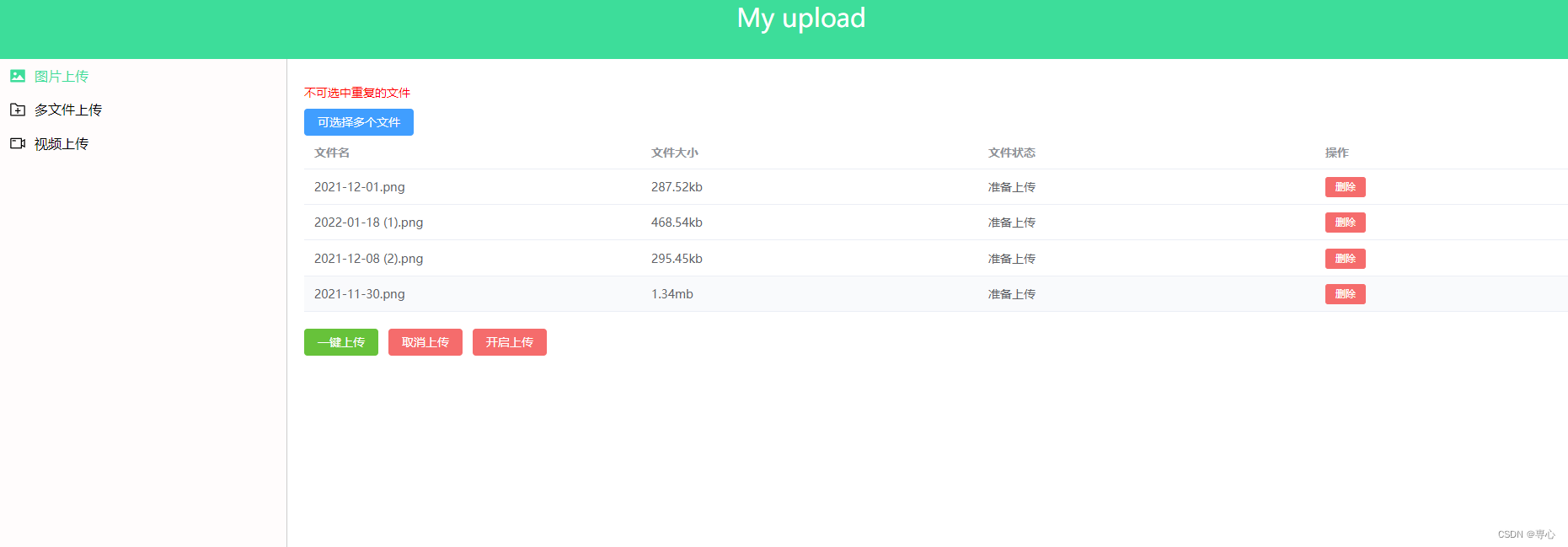
不过文件的状态这里我做了三种显示效果,是 准备上传--> 上传进度条 --> 上传成功(上传失败),table表格用的是Element-plus的 el-table组件,这里的进度我也没有自己写了,用的是Element-plus的组件,不过你们想自己实现的话也很简单(如果想的话可以自己试试)。
注意这里的input选择文件框是隐藏的,点击按钮时触发他的点击事件就行。
注意这里的input选择框默认是只支持选择单文件的,要想实现多文件选择要加上multiple属性
<template><div class="container"><input type="file" ref="fileInputRef" style="display: none" @change="handleFileClick" multiple /><p>不可选中重复的文件</p><el-button type="primary" @click="handleBtnClick">可选择多个文件</el-button><el-table :data="tableData" style="width: 100%"><el-table-column prop="name" label="文件名" width="400" /><el-table-column prop="size" label="文件大小" width="400" /><!-- 控制显示 --><el-table-column label="文件状态" width="400"><template #default="scope1"><span v-if="scope1.row.status == '准备上传'">{{ scope1.row.status }}</span><el-progress :percentage="percentage" stroke-width="8" :width="100" :duration="1" v-if="scope1.row.status == '正在上传'" /><span v-if="scope1.row.status == '上传成功'" style="color: #67c23a">{{ scope1.row.status }}</span><span v-if="scope1.row.status == '上传失败'" style="color: red">{{ scope1.row.status }}</span></template></el-table-column><el-table-column prop="address" label="操作"><template #default="scope3"><el-button size="small" type="danger" @click="handleDelete(scope3.$index, scope3.row)" :disabled="scope3.row.status == '正在上传'">删除</el-button></template></el-table-column></el-table><el-button type="success" style="margin-top: 20px" @click="handleUpload" :disabled="tableData.length == 0">一键上传</el-button><el-button size="default" style="margin-top: 20px" type="danger" @click="cancelUpload">取消上传</el-button><el-button size="default" style="margin-top: 20px" type="danger" @click="free">开启上传</el-button></div>
</template><style lang="scss" scoped>
p {font-size: 14px;color: red;margin: 10px 0;
}
</style>
2.2 整合上传文件的数据
通过基本的静态结构,可以看到table中需要一个tableDatao'n的数据,所以hai'yao我的实现思路是选择上传的文件后将需要用到的数据整合到tableData中供table表格展示,然后还要将上传文件需要用到的formData放在一个数组中保存,在之后上传时再用里面的数据。
定义好需要用到的数据
import { ref } from 'vue'
//存放文件的数组
const fileList = ref([])
//存放table的数据
const tableData = ref([])
//input框的ref
const fileInputRef = ref(null)选择文件后整合数据
//触发文件选择事件
const handleBtnClick = () => {fileInputRef.value.click()
}//触发文件选择框
const handleFileClick = (e) => {//遍历选中的所有文件添加到数组中for (let i = 0; i < e.target.files.length; i++) {let selectedFile = e.target.files[i]//将数据整合起来放进数组中tableData.value.push({id: tableData.value.length,name: selectedFile.name,//判断文件大小,大于0.1mb使用mb,否则使用kbsize: selectedFile.size > 1024 * 1024 ? (selectedFile.size / 1024 / 1024).toFixed(2) + 'mb' : (selectedFile.size / 1024).toFixed(2) + 'kb',status: '准备上传'})fileList.value.push(selectedFile)}
}删除文件的函数
//删除选中的文件
const handleDelete = (index, row) => {console.log(index)//根据index和id进行对比,删除其中的元素tableData.value.splice(index, 1)fileList.value.splice(index, 1)
}2.3 实现一键上传文件
因为我给table中的数据加了status的文件上传的状态,所以我在点击一键上传后,主要使用该字段来进行判断该上传第几个文件,这里会定义一个上传文件的index索引,然后采用递归的方式循环上传所有的文件,其实一键上传也是一个一个文件的上传。
定义好需要用到的数据
//正在上传的文件的index
const fileIndex = ref(0)//一键上传文件
const handleUpload = () => {fileIndex.value = 0//先遍历所有的循环找到没有上传的文件的indextableData.value.forEach((item) => {if (item.status == '上传成功' || item.status == '上传失败') fileIndex.value++})if (tableData.value.length == fileIndex.value) {return}tableData.value[fileIndex.value].status = '正在上传'//调用上传文件的函数uploadFile(fileList.value[fileIndex.value]).then((res) => {if (res) {tableData.value[fileIndex.value].status = '上传成功'//重新调用函数let timer = setTimeout(() => {//进度条归0percentage.value = 0handleUpload()clearTimeout(timer)}, 1000)} else {//返回的是一个promisetableData.value[fileIndex.value].status = '上传失败'}})
}上传文件的函数
因为这里需要做一个实时的上传文件的进度条显示,然后Element-plus的进度条组件中绑定了一个元素来控制其进度条显示,这里需要获取到真实的上传进度,因为我用的是axios封装的请求,所以可以使用其中的一个回调来获取进度,不过原生的axaj也是可以获取的,这个根据自己的项目来
//进度条
const percentage = ref(0)//导入axios构造的函数
import { http} from '@/api/http.js'
//上传文件的函数
const uploadFile = async (value) => {// 创建一个FormData对象来包装文件const formData = new FormData()formData.append('file', value)try {const res = await http.post('/api/fileUpload', formData, {headers: {'Content-Type': 'multipart/form-data'},//监听进度onUploadProgress: (progressEvent) => {//进度条const loaded = progressEvent.loadedconst total = progressEvent.totalconst percentCompleted = Math.round((loaded * 100) / total)//在这里改变进度条的值percentage.value = percentCompletedconsole.log(`上传进度: ${percentCompleted}%`)}})// 等待 Promise 解析console.log(res)// 根据 Promise 解析的结果来判断上传是否成功if (res.code === 200) {ElMessage({type: 'success',message: '上传成功'})return true} else {ElMessage({type: 'error',message: res.msg})return false}} catch (error) {return false}
}现在一键上传文件已经完成了,并且可以实时的显示上传的进度,我们现在可以测试一下。
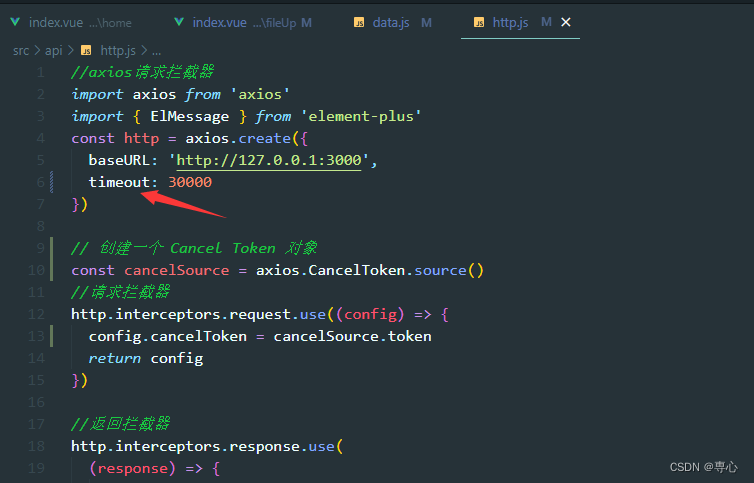
为了方便的看到上传进度,我们可以将浏览器的网络调低一点(不过这样做了就要把请求拦截器中的超时设置的长一点),设置个30s应该差不多
选择好文件后就可以点击上传了
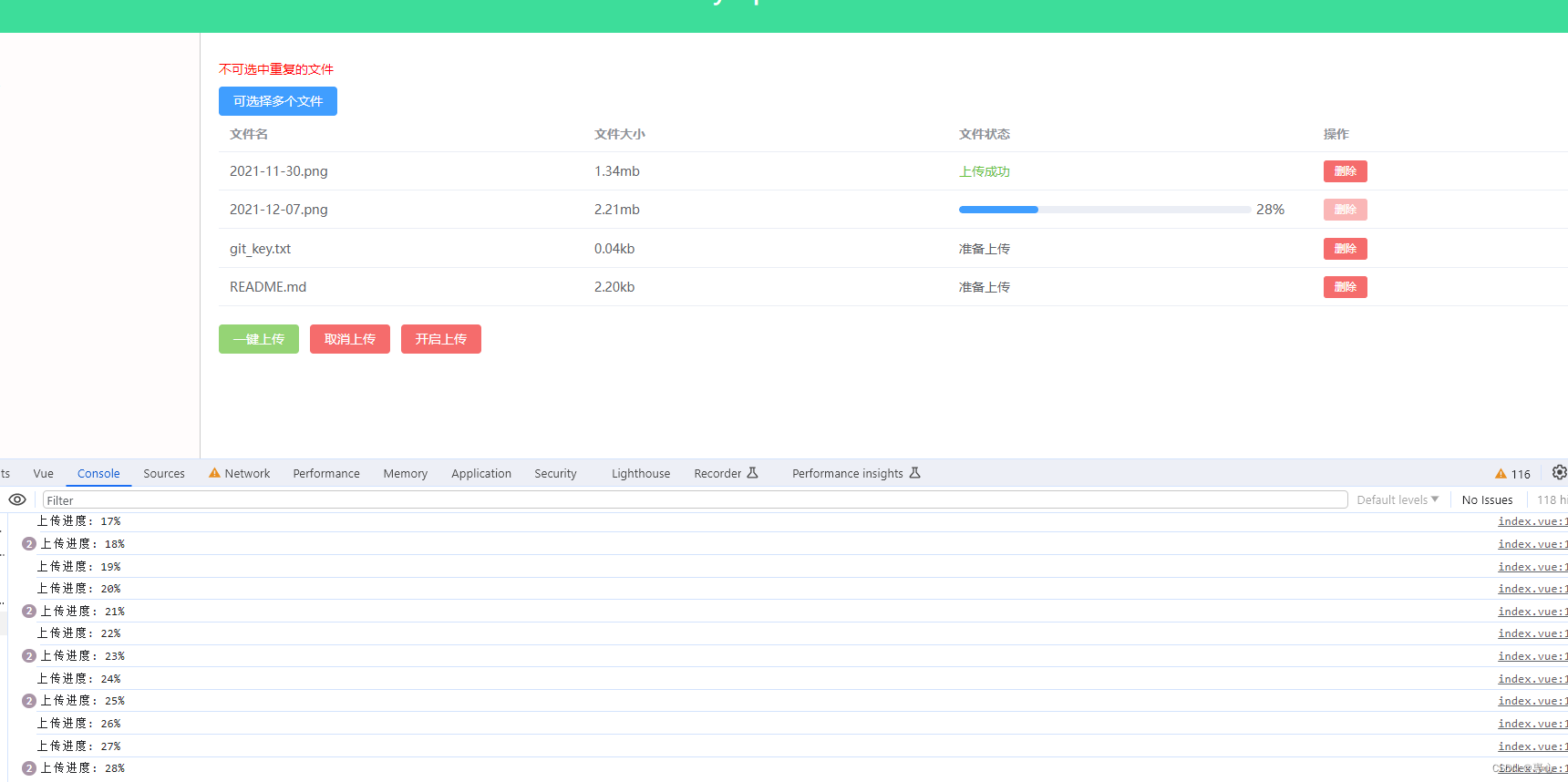
可以看到上传进度是实时显示的 ,并且从后端中文件夹的图片传输进度也能看出来
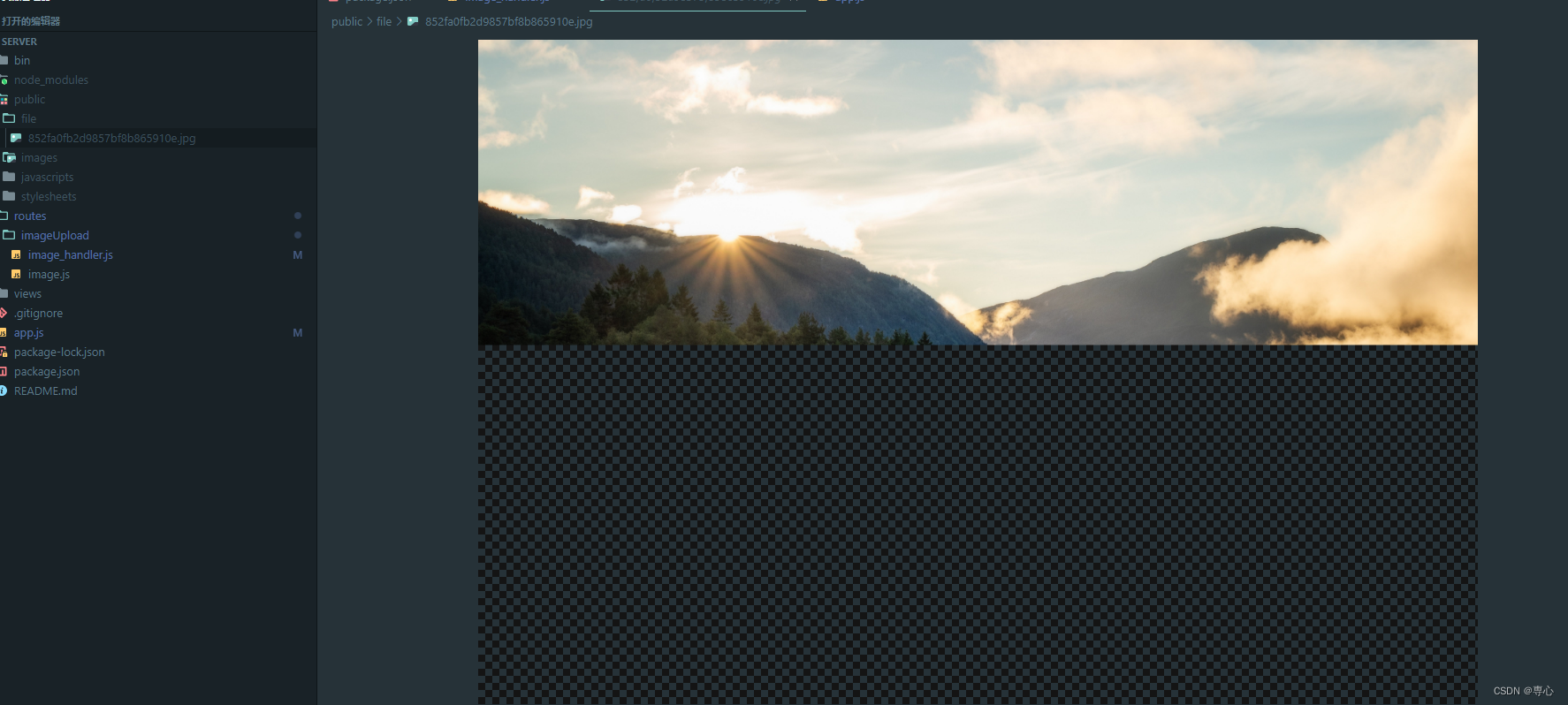
2.4 取消上传
在axios中要想取消上传(取消请求),需要用到cancel token,详情可以查看这个axios中文文档|axios中文网 | axios
在请求拦截器中定义一个token并导出在组件中使用
//axios请求拦截器
import axios from 'axios'
import { ElMessage } from 'element-plus'
const http = axios.create({baseURL: 'http://127.0.0.1:3000',timeout: 30000
})// 创建一个 Cancel Token 对象
const cancelSource = axios.CancelToken.source()
//请求拦截器
http.interceptors.request.use((config) => {config.cancelToken = cancelSource.tokenreturn config
})//返回拦截器
http.interceptors.response.use((response) => {return response.data},//失败回调(error) => {ElMessage({type: 'error',message: error.message})return Promise.reject(error)}
)export { http, cancelSource }
组件中点击取消按钮触发该函数,不过之前要导入cancelSource
import { http, cancelSource } from '@/api/http.js'//取消发送
const cancelUpload = () => {console.log('取消发送')// 取消上传cancelSource.cancel('请求取消')
}不过我这样写会出现一个小bug,就是如果取消上传后就不能再次上传了,因为我的axios发送的post用的都是同一个axios构造出来的实例,关闭后其他的的请求也用不了了,就无法再次上传,解决方法很简单就是直接刷新浏览器即可,或者在发送请求时每次都用axios重新构造一个实例,这样就不会互相受到影响了,不过我偷懒了一波就直接采用了刷新浏览器的方式了,你们如果要做的话可以优化一下这个功能。
const free = () => {//这里我将开启上传设置成了刷新页面,但实际情况下,可以重新创建axios请求示例,其他的请求就不会受到影响了,有兴趣的可以自己实现一下该功能location.reload()
}到此该一键上传文件并且实时显示进度条的功能就实现了。
下一篇是完成大文件的切片上传,敬请关注等候。