网站如何分页好推建站
背景
在日常的数据库运维过程中,难免会遭遇数据误操作的情形,比如因疏忽而执行了非预期的delete或update操作,这时就需要进行数据回滚。如果在OceanBase中启用了回收站功能,并设置了合适的undo_retention,那么我们可以利用闪回查询这一功能来实现数据的快速恢复。对此感兴趣的朋友,可以前往平台进一步了解:闪回查询 。不幸的是,回收站是默认处于关闭状态的,一旦开启,数据盘的使用量也会相应增加。对于熟悉MySQL的用户来说,都知道存在一个binlog文件,这个文件可以通过各种开源工具来生成回滚的sql,OceanBase binlog service已经发布了一段时间,在2023年12月底,obd v250也开始支持部署oblogproxy(其中一种模式即binlog service)。本文将通过部署oblogproxy,并结合mysql工具来测试数据回滚操作。对于感兴趣的同学,也可以进一步测试MyFlash在回滚恢复数据方面的支持情况。
部署 oblogproxy
1、obd 版本不低于 2.5.0。
2、拷贝 oblogproxy 配置文件模版
安装obd后,配置文件模版在/usr/obd/example,可以按需拷贝,本次部署的是 oblogproxy 组件 且测试环境有ocp (提供了config server 服务),如果我们使用的环境没有ocp,需要拷贝 distributed-with-obproxy-and-oblogproxy-example.yaml 文件,这里以 oblogproxy-only-example.yaml 为例:
3、编辑oblogproxy-only-example.yaml配置文件
user:username: adminkey_file: /home/admin/.ssh/id_rsa
oblogproxy:servers:- 172.24.255.96version: 2.0.0global:: /home/admin/oblogproxyservice_port: 2983ob_sys_username: "binlog_user"ob_sys_password: "aaAA11__"#binlog_dir: /root/oblogproxy/run#binlog_mode: true # enable binlog mode, default true4、部署和启动oblogproxy
obd cluster deploy oblogproxy -c oblogproxy-only-example.yaml -vobd cluster start oblogproxy -v5、创建用户并授权
在要创建 binlog 服务所在集群的sys租户下为 obd 配置的 ob_sys_username 创建账密并授权 oceanbase 库读权限。
create user binlog_user identified by 'aaAA11__';grant select on oceanbase.* to binlog_user;6、在 obproxy 中配置 oblogproxy 服务地址
alter proxyconfig set enable_binlog_service='True';
alter proxyconfig set binlog_service_ip='172.24.255.96:2983';
alter proxyconfig set init_sql='set _show_ddl_in_compat_mode = 1;';7、创建 binlog 服务
mysql -h172.24.255.96 -P 2983
CREATE BINLOG FOR TENANT obtest.test1 WITH CLUSTER URL
'http://172.24.255.96:8080/services?Action=ObRootServiceInfo&User_ID=alibaba&UID=ocpmaster&ObRegion=obtest';步骤6、7中相关的命令和参数说明详见:
OceanBase分布式数据库-海量数据 笔笔算数
8、确认 binlog 服务是否正常
在创建 binlog 服务所在的用户租户下 执行:
mysql -h172.24.255.93 -P2883 -uroot@test1#obtest -pxxx -A -cMySQL [(none)]> show master status;
+------------------+----------+--------------+------------------+------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+------------------------------------------+
| mysql-bin.000001 | 1158 | | | 013e0324-9fc6-11ee-8dfd-00163e0383a5:1-4 |
+------------------+----------+--------------+------------------+------------------------------------------+
1 row in set (0.24 sec)在obd 配置文件的 home_path/run 目录下会生成第7步创建binlog service对应的集群名的目录结构,在 run/{集群名}/{租户名}/data 目录下确认生成了我们熟悉的 binlog 文件。
tree -L 2 run/obtest
run/obtest
└── test1├── binlog_converter.conf├── data├── etc├── log├── run└── storage6 directories, 1 file[root@172.24.255.96 data]$pwd
/home/admin/oblogproxy/run/obtest/test1/data
[root@172.24.255.96 data]$
[root@172.24.255.96 data]$ls -lrt
总用量 8
-rw-rw-r-- 1 admin admin 0 1月 3 14:50 index.LOCK
-rw-rw-r-- 1 admin admin 116 1月 3 15:01 mysql-bin.index
-rw-rw-r-- 1 admin admin 1158 1月 3 15:01 mysql-bin.000001
[root@172.24.255.96 data]$模拟数据
在 test1 租户下
create table t1(id int primary key,name varchar(20));
insert into t1 values(1,'a'),(2,'b'),(3,'c');
update t1 set name='aaa' where id=1;使用 my2sql 工具
my2sql 工具的说明: GitHub - liuhr/my2sql: 解析MySQL binlog ,可以生成原始SQL、回滚SQL、去除主键的INSERT SQL等,也可以生成DML统计信息以及大事务分析信息。
git clone https://github.com/liuhr/my2sql.git执行后会在当前目录下生成一个 my2sql 目录[root@172.24.255.96 ~]$cd my2sql/
[root@172.24.255.96 my2sql]$ls -lrt
总用量 80
-rw-r--r-- 1 root root 9662 1月 3 14:55 README.md
-rw-r--r-- 1 root root 1046 1月 3 14:55 LICENSE
drwxr-xr-x 3 root root 4096 1月 3 14:55 misc
-rw-r--r-- 1 root root 1221 1月 3 14:55 main.go
-rw-r--r-- 1 root root 12300 1月 3 14:55 go.sum
-rw-r--r-- 1 root root 838 1月 3 14:55 go.mod
drwxr-xr-x 2 root root 4096 1月 3 14:55 ehand
drwxr-xr-x 2 root root 4096 1月 3 14:55 dsql
drwxr-xr-x 2 root root 4096 1月 3 14:55 constvar
drwxr-xr-x 2 root root 4096 1月 3 14:55 base
drwxr-xr-x 3 root root 4096 1月 3 14:55 releases
drwxr-xr-x 2 root root 4096 1月 3 14:55 toolkits
drwxr-xr-x 2 root root 4096 1月 3 14:55 sqltypes
drwxr-xr-x 2 root root 4096 1月 3 14:55 sqlbuilder
drwxr-xr-x 4 root root 4096 1月 3 14:55 vendor
[root@172.24.255.96 my2sql]$cd releases/
[root@172.24.255.96 releases]$ls -lrt
总用量 4
drwxr-xr-x 2 root root 4096 1月 3 14:55 centOS_release_7.x
[root@172.24.255.96 releases]$cd centOS_release_7.x/
[root@172.24.255.96 centOS_release_7.x]$ll
总用量 7744
-rw-r--r-- 1 root root 107 1月 3 14:55 biglong_trx.txt
-rw-r--r-- 1 root root 144 1月 3 14:55 binlog_status.txt
-rwxr-xr-x 1 root root 7919430 1月 3 14:55 my2sql
[root@172.24.255.96 centOS_release_7.x]$pwd
/root/my2sql/releases/centOS_release_7.xmy2sql 查看原始sql
/root/my2sql/releases/centOS_release_7.x/my2sql \
-user root@test1#obtest -password xxx -host 172.24.255.93 -port 2883 \
-mode file -local-binlog-file /home/admin/oblogproxy/run/obtest/test1/data/mysql-bin.000001 \
-work-type 2sql -start-file /home/admin/oblogproxy/run/obtest/test1/data/mysql-bin.000001 \
-start-datetime "2024-01-03 14:00:00" -stop-datetime "2024-01-03 16:00:00" \
-output-dir /tmp/test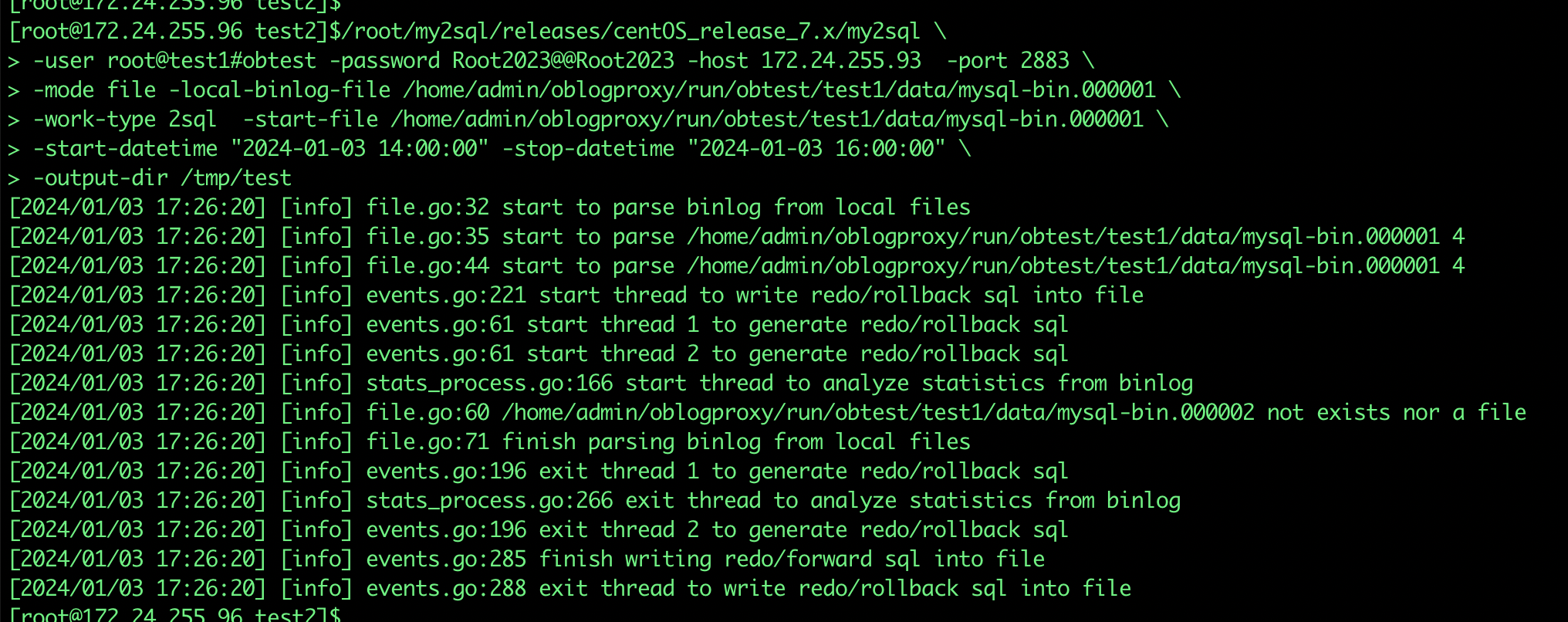
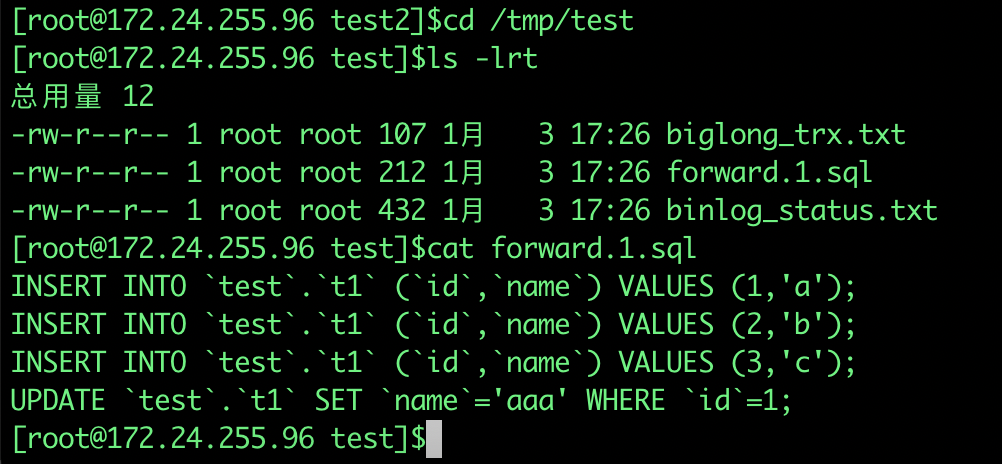
my2sql 查看回滚sql
/root/my2sql/releases/centOS_release_7.x/my2sql \
-user root@test1#obtest -password xxx -host 172.24.255.93 -port 2883 \
-mode file -local-binlog-file /home/admin/oblogproxy/run/obtest/test1/data/mysql-bin.000001 \
-work-type rollback -start-file /home/admin/oblogproxy/run/obtest/test1/data/mysql-bin.000001 \
-start-datetime "2024-01-03 14:00:00" -stop-datetime "2024-01-03 16:00:00" \
-output-dir /tmp/test2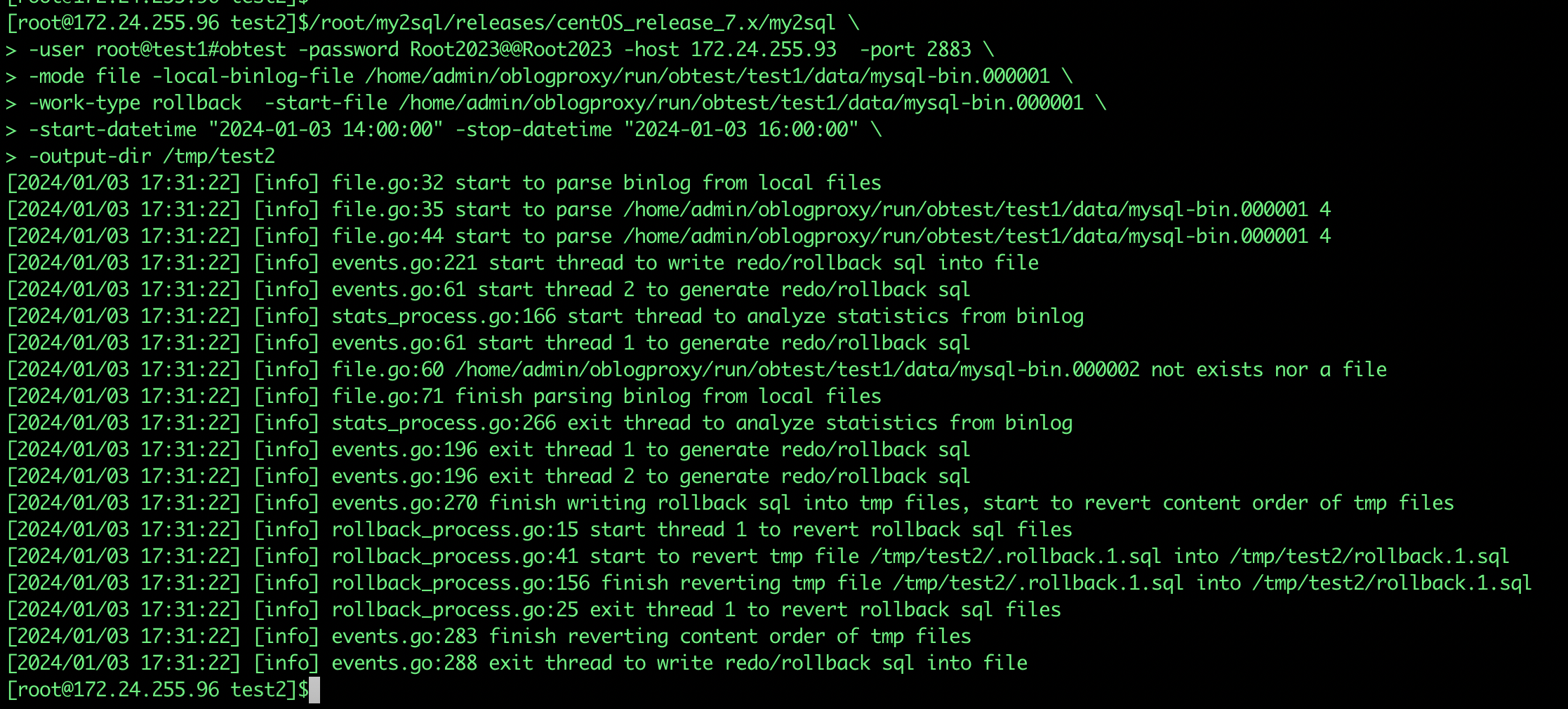
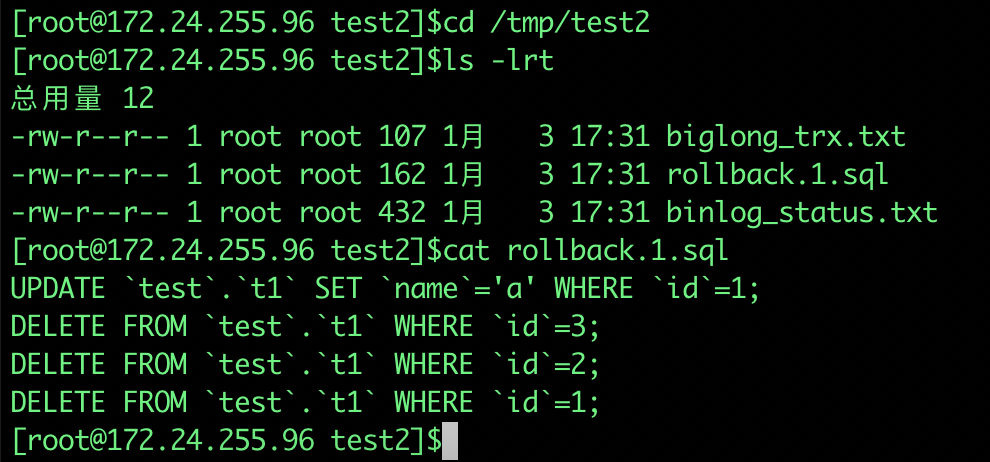
找业务评估回滚的sql,确认没有问题后执行即可实现数据误操作后回滚。
通过上面的测试,我们可以看到 oceanbase binlog service 产生的 binlog 文件的兼容性,通过开源工具 my2sql 可以正常解析。用到的命令比较粗糙没有加过滤条件,实际在使用中可以按需根据 database_name,table_name 等条件进行过滤,使得生成的sql更加符合我们的预期。